the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 06 Dec 2021
| 06 Dec 2021
Extreme metrics from large ensembles: investigating the effects of ensemble size on their estimates
Kalyn Dorheim
Michael Wehner
Ruby Leung
We consider the problem of estimating the ensemble sizes required to characterize the forced component and the internal variability of a number of extreme metrics. While we exploit existing large ensembles, our perspective is that of a modeling center wanting to estimate a priori such sizes on the basis of an existing small ensemble (we assume the availability of only five members here). We therefore ask if such a small-size ensemble is sufficient to estimate accurately the population variance (i.e., the ensemble internal variability) and then apply a well-established formula that quantifies the expected error in the estimation of the population mean (i.e., the forced component) as a function of the sample size n, here taken to mean the ensemble size. We find that indeed we can anticipate errors in the estimation of the forced component for temperature and precipitation extremes as a function of n by plugging into the formula an estimate of the population variance derived on the basis of five members. For a range of spatial and temporal scales, forcing levels (we use simulations under Representative Concentration Pathway 8.5) and two models considered here as our proof of concept, it appears that an ensemble size of 20 or 25 members can provide estimates of the forced component for the extreme metrics considered that remain within small absolute and percentage errors. Additional members beyond 20 or 25 add only marginal precision to the estimate, and this remains true when statistical inference through extreme value analysis is used. We then ask about the ensemble size required to estimate the ensemble variance (a measure of internal variability) along the length of the simulation and – importantly – about the ensemble size required to detect significant changes in such variance along the simulation with increased external forcings. Using the F test, we find that estimates on the basis of only 5 or 10 ensemble members accurately represent the full ensemble variance even when the analysis is conducted at the grid-point scale. The detection of changes in the variance when comparing different times along the simulation, especially for the precipitation-based metrics, requires larger sizes but not larger than 15 or 20 members. While we recognize that there will always exist applications and metric definitions requiring larger statistical power and therefore ensemble sizes, our results suggest that for a wide range of analysis targets and scales an effective estimate of both forced component and internal variability can be achieved with sizes below 30 members. This invites consideration of the possibility of exploring additional sources of uncertainty, such as physics parameter settings, when designing ensemble simulations.
- Article
(93433 KB) - Full-text XML
- BibTeX
- EndNote





Recently, much attention and resources have been dedicated to running and analyzing large ensembles of climate model simulations under perturbed initial conditions (e.g., Deser et al., 2012; Pausata et al., 2015; Steinman et al., 2015; Bittner et al., 2016; Li and Ilyina, 2018; Maher et al., 2018; Deser et al., 2020; Lehner et al., 2020; Maher et al., 2021a, b). Both detecting the forced component in externally forced experiments and quantifying the role of internal variability are being facilitated by the availability of these large ensembles. Many variables and metrics of model output have been analyzed, with large ensembles allowing precise estimates of their current and future statistics. Large ensembles are also being used to answer methodological questions, particularly about the precision these experiments can confer to the estimate of those variables and metrics, and how that varies with increasing ensemble sizes (e.g., Milinski et al., 2020). Recent efforts by multiple modeling centers to coordinate these experiments so that they can be comparable (by being run under the same scenarios of future greenhouse gas emissions) allow answering those questions robustly, accounting for the size and behavior over time of internal variability, which is known to be a model-specific characteristic (Deser et al., 2020).
In this methodological study, we adopt the point of view of a modeling center interested in estimating current and future behavior of several metrics of extremes, having to decide on the size of a large ensemble. Such a decision, we assume, needs to be reached on the basis of a limited number of initial condition members, which the center would run as a standard experiment. We choose a size of five, which is a fairly common choice for future projection experiments, and use the statistics we derive on the basis of such small ensemble to estimate the optimal size of a larger ensemble, according to standards of performance that we specify. We test our estimate of the optimal size by using a perfect model setting, defining what a full large ensemble gives us as “the truth”. We use two large ensembles available through the Climate Variability and Predictability (CLIVAR) single-model initial-condition large ensemble (SMILE) initiative (Lehner et al., 2020), the Community Earth System Model version 1 – Community Atmosphere Model 5.0 Large Ensemble Community Project (CESM1-CAM5 LENS) (of 40 ensemble members, Kay et al., 2015) and the Canadian Earth System Model version 2 (CanESM2) ensemble (of 50 members, Kirchmeier-Young et al., 2017; Kushner et al., 2018), both run over the historical period and under Representative Concentration Pathway 8.5 (RCP8.5) according to the CMIP5 protocol (Riahi et al., 2011; Taylor et al., 2012).
Our metrics of interest are indices describing the tail behavior of daily temperature and precipitation. We conduct the analysis in parallel for extremes of temperature and precipitation because we expect our answers to be dependent on the signal-to-noise ratio affecting these two atmospheric quantities, which we know to be different in both space and time (Hawkins and Sutton, 2009, 2011; Lehner et al., 2020).
We consider the goal of identifying the forced change over the course of the 21st century in the extremes behavior. We seek an answer in terms of the ensemble size for which we expect the estimate of the forced component to approximate the truth within a given tolerance or for which our estimate does not change significantly with additional ensemble members. We also consider the complementary problem of identifying the ensemble size that fully characterizes the variability around the forced component. After all, considering future changes in extremes usually has salience for impact risk analysis, and any risk-oriented framework will be better served by characterizing both the expected outcomes (i.e., the central estimates) and the uncertainties surrounding them. Both types of questions can be formulated on a wide range of geographic scales, as the information that climate model experiments provide is used for evaluation of hazards at local scales, for assessment of risk and adaptation options, all the way to globally aggregated metrics, usually most relevant for mitigation policies. The time horizon of interest may vary as well. Therefore, we present results from grid-point scales all the way to global average scales, and for mid-century and late-century projections, specific years or decades along the simulations, or whole century-long trajectories.
The consideration of two models, two atmospheric quantities and several extreme metrics, each analyzed at a range of spatial and temporal scales, helps our conclusions to be robust and – we hope – applicable beyond the specifics of our study.
The CESM1-CAM5 LENS (CESM ensemble from now on) has been the object of significant interest and many published studies, as the more-than-1300 citations of Kay et al. (2015) testify to, and, if in lesser measure, so has been the CanESM2 ensemble (CanESM ensemble from now on). The CESM model has a resolution of about 1∘ in the longitude–latitude dimensions (Hurrell et al., 2013), while CanESM has a coarser resolution of about 2∘ (Arora et al., 2011). Both have been run by perturbing the atmospheric state at a certain date of the historical simulation (five different simulations in the case of CanESM) by applying “errors” of the order of magnitude of machine precision. These perturbations have been found to generate alternative system trajectories that spread out losing memory in the atmosphere of the respective initial conditions within a few days of simulation time (Marotzke, 2019). We note that sources of variability from different ocean states, particularly at depth, are not systematically sampled by this type of ensembles, albeit they are partially addressed by the design of the CanESM2 that uses defacto different ocean states. For CESM, 38 or 40 ensemble members (depending on the variable considered) are available, covering the period between 1920 and 2100, while CanESM only starts from 1950 but has 48 or 50 ensemble members. In the following, we will not distinguish precisely between the full size or the full size minus two, as the results are not influenced by this small difference. Both models were run under historical and RCP8.5 external forcing, the latter applied starting at 2006. In our analysis, we focus first on results from the CESM ensemble and use CanESM to confirm the robustness of our results. For consistency, we use the period 1950–2100 for both ensembles.
We use daily output of minimum and maximum temperature at the surface (TASMIN and TASMAX) and average precipitation (PR) and compute a number of extreme metrics, all of them part of the Expert Team on Climate Change Detection and Indices (ETCCDI) suite (Alexander, 2016). All the metrics amount to annual statistics descriptive of daily output. They are
-
TXx – highest value over the year of daily maximum temperature (interpretable as the warmest day of the year);
-
TXn – lowest value over the year of daily maximum temperature (interpretable as the coldest day of the year);
-
TNx – highest value over the year of daily minimum temperature (interpretable as the warmest night of the year);
-
TNn – lowest value over the year of daily minimum temperature (interpretable as the coldest night of the year);
-
Rx1Day – precipitation amount falling on the wettest day of the year;
-
Rx5Day – average daily amount of precipitation during the wettest 5 consecutive days (i.e., the wettest pentad) of the year.
We choose these indices as they reflect diverse aspects of daily extremes but also because of a technical matter: their definitions all result in the identification of what statistical theory of extreme values calls “block maxima” or “block minima” (here, the block is composed of the 365 d of the year). The same theory establishes that quantities so defined lend themselves to be fitted by the generalized extreme value (GEV) distribution (Coles, 2001). GEV fitting allows us to apply the power of inferential statistics, through which we can estimate return levels for any given period (e.g., the 20-, 50- or 100-year events), and their confidence intervals. We will be looking at how these statistics – i.e., tail inference by a statistical approach that was intended specifically for data-poor problems – change with the number of data points at our disposal, varying with ensemble size and asking if the statistical approach buys us any statistical power with respect to the simple “counting” of events across the ensemble realizations.
3.1 Identifying the forced component
Milinski et al. (2020) use the ensemble mean computed on the basis of the full ensemble as a proxy for the true forced signal and analyze how its approximation gains in precision by using an increasingly larger ensemble size. By a bootstrap approach, subsets of the full ensemble of a given size n are sampled (without replacement) multiple times (in our analysis, we will use 100 times), their mean (for the metric of interest) is computed, and the multiple replications of this mean are used to compute the root mean square error (RMSE) with respect to the full ensemble mean. Note that this bootstrap approach at estimating errors is expected to become less and less accurate as n increases, as was also noted in Milinski et al. (2020). For n approaching the size of the full ensemble, the repeated sampling from a finite population introduces increasingly stronger dependencies among the samples, which share larger and larger numbers of members, therefore underestimating RMSE(n). More problematically, this approach would not be possible if we did not have a full ensemble to exploit, and if our model was thought of having different characteristics in variability than the models for which large ensembles are available. As a more realistic approach, therefore, we assume that only five ensemble members are available and we abandon the bootstrap, proposing to use a different method to infer the expected error as a function of
-
an estimate of the ensemble variability that we compute on the basis of the five members available; and
-
the variable size n of the ensemble that we are designing.
We will compare our inferred errors according to our method to the “true” errors that the availability of an actual large ensemble allows us to compute.
It is a well-known result of descriptive statistics that the standard error of the sample mean around the true mean decreases as a function of n, the sample size, as in (see Wehner, 2000, for an application to climate model ensemble size computations well before the advent of large ensembles). Here, σ is the true standard deviation of the population. In our case, it is the standard deviation of the ensemble, and we take as its true value what we compute as the full ensemble standard deviation on the basis of 40 or 50 members for CESM and CanESM respectively, while we estimate it on the basis of only five members and show how our inferred errors compare to the true errors. We will also show in the first application of our method to global average trajectories how the error estimated by the bootstrap compares to ours and the true error, confirming that for n approaching the full ensemble size the bootstrap underestimates the RMSE. For the remainder of our analysis, we will not use the bootstrap approach further.
Since we are considering extreme metrics that can be modeled by a GEV, we also derive a range of return levels at a set of individual locations.
If a random variable z (say the temperature of the hottest day of the year, TXx) is distributed according to a GEV distribution, its distribution function has the form
where three parameters μ, σ and ξ determine its domain and its behavior. The domain is defined as , and the three parameters satisfy the following conditions: , σ>0 and . μ, σ and ξ represent the location, scale and shape parameter, respectively, related to the mean, variability and tail behavior of the random quantity z.
If p (say p=0.01) is the tail probability to the right of level zp under the GEV probability density function, zp is said to be the return level associated to the -year return period (100-year return period in this example) and is given by
Thus, zp in our example represents the temperature in the hottest day of the year expected to occur only once every 100 years (in a stationary climate) or with 0.01 probability every year (a definition more appropriate in the case of a transient climate).
We estimate the parameters of the GEVs, and therefore the quantities that are function of them, like zp and their confidence intervals by maximum likelihood, using the R package extRemes1.
Because of the availability of multiple ensemble members we can choose a narrow window along the simulations (we choose 11 years) to satisfy the requirement of stationarity that the standard GEV fit postulates. We perform separate GEV fits centered around several dates along the simulation, i.e., 2000, 2050 and 20952 (the last chosen to allow extracting a symmetric window at the end of the simulations). The GEV parameters are estimated separately for a range of ensemble sizes n up to the full size available (for each n, we concatenate 11 years from the first n members of the ensemble, obtaining a sample of 11⋅n values, and for each value of n the same subset of members is used across all metrics, locations, times and return periods). On the basis of those estimates, we compute return levels and their confidence intervals for several return periods X, (expressed in years), and assess when the estimates of the central value converge and what the trade-off is between sample size and width of the confidence interval. Lastly, we can use a simple counting approach, based on computing the empirical cumulative distribution function (CDF) from the same sample, to determine those same X-year events. That is, after computing the empirical CDF, we choose the value that leaves to its right no more than data points, where p is the tail probability corresponding to the -year return period as defined above. The comparison will verify if fitting a GEV allows to achieve an accurate estimate using a smaller ensemble size than the empirical approach (where “accurate” is defined as close to the estimate obtained by the full ensemble).
We perform the analysis for a set of individual locations (i.e., grid points), as for most extreme quantities there would be little value in characterizing very rare events as means of large geographical regions. Figure C9 shows the 15 locations that we chose with the goal of testing a diverse set of climatic conditions.
3.2 Characterizing internal variability
Recognizing the importance of characterizing variability besides the signal of change, we ask how many ensemble members are required to fully characterize the size of internal variability and its possible changes over the course of the simulation due to increasing anthropogenic forcing. Process-based studies are suited to tackle the question of how and why changes in internal variability manifest themselves in transient scenarios (Huntingford et al., 2013), while here we simply describe the behavior of a straightforward metric, the within-ensemble standard deviation. We look at this quantity at the grid-point scale and we investigate how many ensemble members are needed to robustly characterize the full ensemble behavior, which here again we assume to be representative of the true variability of the system. This translates into two separate questions. First, for a number of dates along the simulation spanning the 20th and 21st centuries, we ask how many ensemble members are needed to estimate an ensemble variance that is not statistically significantly different from that estimated on the basis of the full ensemble (note that we have implicitly answered this by verifying that, at least for the computation of the expected RMSE in Sect. 3.1, plugging in an estimate of σ based on five members appears to be accurate). Second, we first detect changes in variance between all possible pairs of these dates on the basis of the full ensemble, and we then ask how many ensemble members are needed to detect the same changes. We use F tests to determine significant differences in variance, and since we apply them at each grid point we adopt a method for controlling the false discovery rate described for environmental applications in Ventura et al. (2004) and Wilks (2016) as a way to correct for multiple testing fallacies.
In the following presentation of our main findings, we choose two representative metrics, TNx (warmest night of the year) and Rx5Day (average rainfall amount during the 5 wettest days of the year) using the 40-member CESM ensemble. In the Appendix, we include the same type of results for the additional metrics considered and the 50-member CanESM ensemble. We will discuss if and when the results presented in this section differ from those shown in the Appendix.
4.1 Identifying the forced component
We start from time series of annual values of globally averaged TNx and Rx5Day (Fig. 1, top panels). We compute them for each ensemble member separately and average them over n ensemble members as the ensemble size n increases, applying the bootstrap approach and computing RMSE(n) (see Sect. 3.1) at every year along the simulation.

Figure 1Time series for TNx (warmest night of the year, left) and Rx5Day (average daily amount during the 5 consecutive wettest days of the year, right) showing how the estimate of the forced component of their global mean trajectories over the period 1950–2100 changes when averaging an ensemble of increasing size. The top row shows the entire time series. The middle row zooms into the relatively flatter period of 1950–2000, so that the y-axis range allows a clearer assessment of the relative size of the uncertainty ranges for different sizes of the ensembles. The ranges are determined by bootstrapping. The bottom row plots the bootstrapped RMSE for every year and each ensemble size.
As Fig. 1 indicates, for both quantities, the marginal effect of increasing the ensemble size by five members is not constant but rather decreases as the ensemble size increases. This is qualitatively visible in the evolution of the ranges in the panels of the first two rows and is measured along the y axis of the plots along the bottom row, where RMSE(n) for increasing n is shown (each n corresponding to a different color).
Table 1Global mean of TNx as simulated by the CESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 35, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σt is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σt estimated by a subset of five ensemble members and 5 years around the year t considered (columns labeled “(F-5)”). Results are shown for four individual years (t) along the simulation (column-wise), since σt varies along its length. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
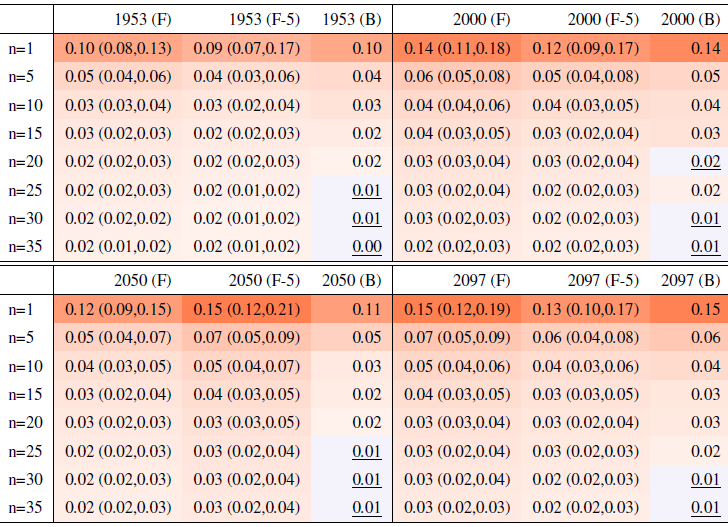
This behavior is to be expected, as we know the RMSE of a mean behaves in inverse proportion to the square root of the size of the sample from which the mean is computed, but the actual behavior shown in the plots and Tables 1 and 2 along columns labeled (B) could be misleading, as the variability of the largest means (largest in sample size n) could be underestimated by the bootstrap (see Sect. 3.1). Furthermore, this assessment would not be possible if all we had was a five-member ensemble for our model. We can therefore compute the formula for the standard error of a mean, (see Sect. 3.1), using the full ensemble to estimate σ, which we assume to be the true standard deviation of the ensemble. We then repeat the estimation by substituting a value of σ derived using only five ensemble members. Table 1 shows RMSEs for the same increasing values of n, evaluated at four different dates along the simulation, as we expect σ to change. The columns labeled (F) apply the formula using the full ensemble size to estimate σt, t=1953, 2000, 2050 and 2097. The values along these columns represent the truth against which we compare our estimates based on the first five ensemble members (columns labeled (F-5)) and the estimates by the bootstrap (columns labeled (B)). Importantly, for the accuracy of our results, when we use only the first five members we increase the sample size by using a window of 5 years around each date t. We are aware that this could introduce autocorrelation within the sample values, but the comparison of these results to the truth shows that the estimated values based on the smaller ensemble are an accurate approximation of it, always being consistent with the 95 % confidence intervals (shown in parentheses). From the table entries, we can assess that the bootstrap estimation is inaccurate once the ensemble size exceeds about 15–20 out of 40 available (we have colored the cells in gray when this happens to underline this behavior). For the larger sizes, the RMSE estimated by the bootstrap falls in all cases to the left of the confidence interval under the (F) column, confirming the tendency to underestimate the RMSE. However, the estimate of RMSE associated with an ensemble size of 10 or 15 already quantifies a high degree of accuracy for the approximation of the ensemble mean of the full 40-member ensemble: those RMSEs for TNx are on the order of 0.02–0.04 ∘C.
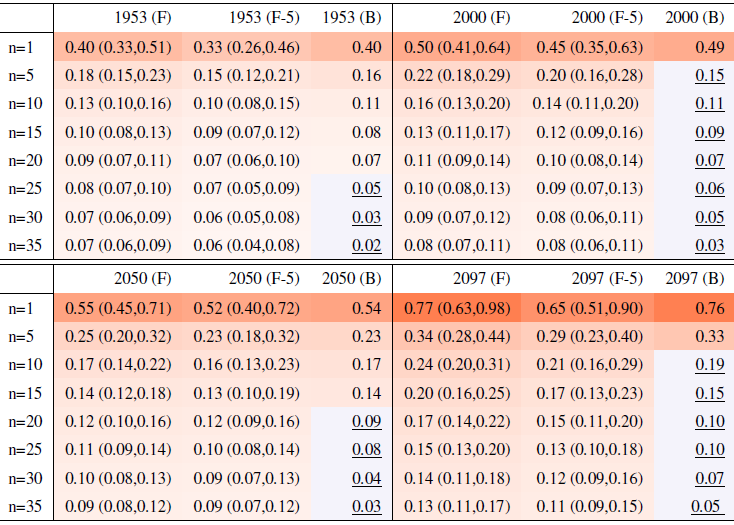
Table 2 reports the same analysis results for the precipitation metric, Rx5Day. The same general message can be drawn, with too-narrow estimates by the bootstrap approach for ensemble sizes starting at around 20 or 25 members. Even in this case, however, the estimate for the RMSE is on the order of 0.1–0.2 mm/d for Rx5Day once the ensemble size exceeds 10.
Table 2Same as Table 1, for Rx5Day. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
The lessons learned here are as follows:
-
for both metrics, an accurate estimate of σt, i.e., the instantaneous model internal variability at global scale, is possible using five ensemble members (and a window of 5 years around the year t of interest);
-
if the formula for computing the RMSE on the basis of a given sample size is adopted, and that estimate for σt is plugged in, it is possible, on the basis of an existing five-member ensemble, to accurately estimate the required ensemble size to identify the forced component within a given tolerance for error. Of course, the size of this tolerance will change depending on the specific application.
We note here that the calculation of the RMSE for increasing ensemble sizes is straightforward once σt is estimated. Even more straightforward is the calculation of the expected “gain” in narrowing the RMSE. A simple ratio calculation shows that for n spanning the range 5 to 45 (relevant sizes for our specific examples), the reduction in RMSE follows the sequence . Thus, compared to a single model run's RMSE, we expect the RMSE of mean estimates derived by ensemble sizes of n=5, 10, 20, 35 or 45 to be 45 %, 32 %, 22 %, 17 % or 15 % of that, respectively.
We assess how the results of the formula compare to the actual error by considering the difference between the smaller size ensemble means and the truth (the full ensemble mean), year by year and comparing that difference to twice the expected RMSE derived by the formula, i.e., , akin to a 95 % probability interval for a normally distributed quantity. Here is where our approximation, and the use of possibly autocorrelated samples in the estimates of σ, could possibly reveal shortcomings. Figure 2, for global averages of the two same quantities, shows the ratios of actual error vs. the 95 % probability bound, indicating the 100 % level by a horizontal line for reference. As can be assessed, the actual error is in most cases much smaller than the 95 % bound (as it is not reaching the 100 % line in the great majority of cases), and we see that only occasionally the actual error spikes above the 95 % bound for individual years, consistent with what would be expected of a normally distributed error. This behavior is consistently true for ensemble sizes larger than n=5.
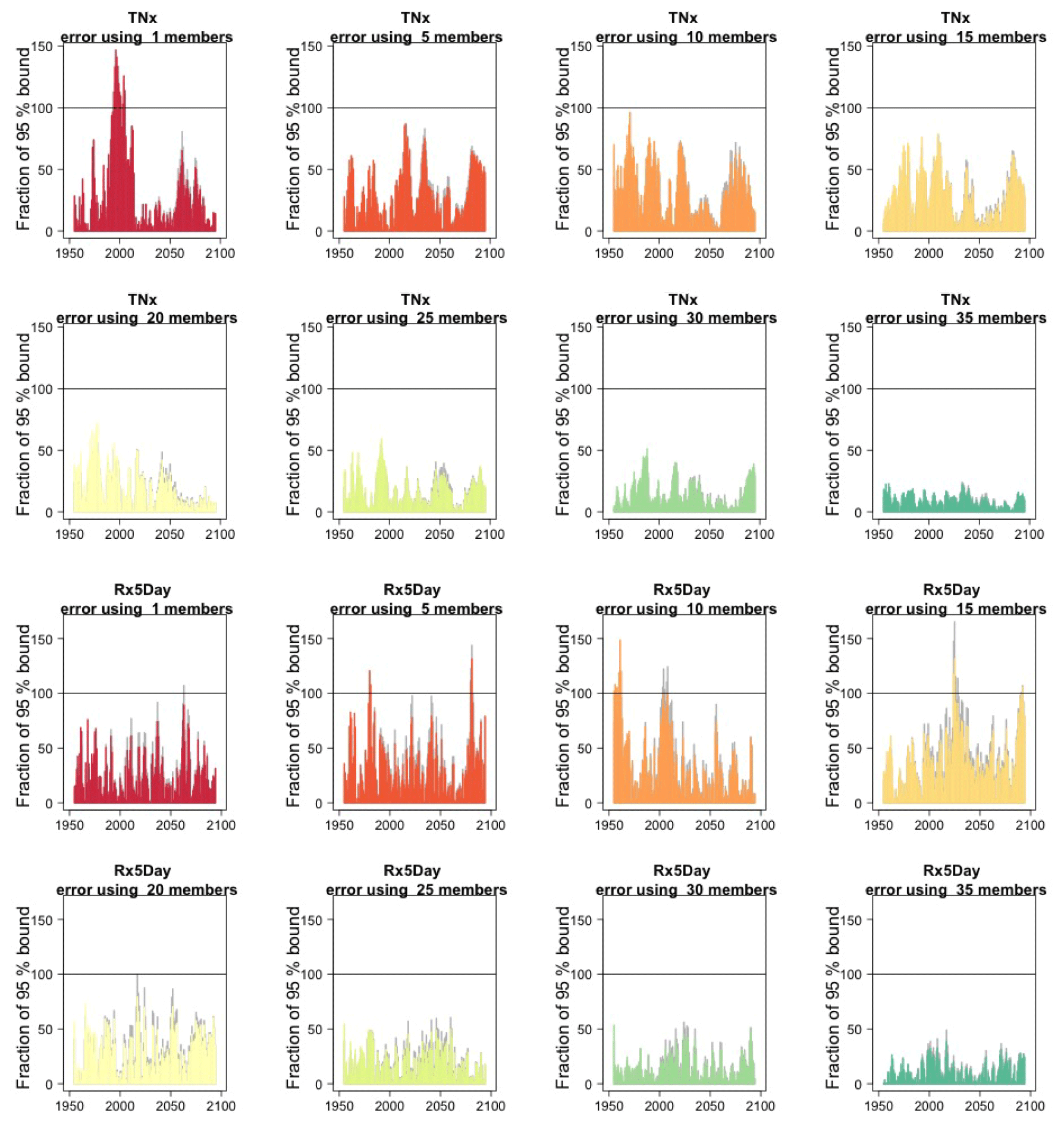
Figure 2In each plot, for each year, the height of the bar gives the error in the estimate of the forced component (defined as the mean of the entire ensemble) as a percentage of the expected 95 % probability bound, estimated by the formula with n the ensemble size. Gray bars indicate whether σt is the truth (i.e., estimated using the whole ensemble); colored bars indicate whether σt is estimated using only five ensemble members (but using 5 years around each year). Each plot corresponds to a different and increasing ensemble size: 1, 5, 10, 15, 20, 25, 30, 35. The top two rows of plots are for TNx; the bottom two rows are for Rx5Day. All results are for the CESM ensemble.
In the Appendix, we report the results of applying the same analysis to the rest of the indices. We cannot show all results, but we tested country averages, zonal averages, land- and ocean-area averages separately, confirming that the qualitative behavior we assess here is common to all these other scales of aggregation.
Here, we go on to show how the same type of analysis can be applied at the grid-point scale and still deliver an accurate bound for the error in approximating the forced component. For the grid-scale analysis, we define as the forced component anomalies by mid- and end-of-century (compared to a baseline) obtained as differences between 5-year averages: 2048–2052 and 2096–2100 vs. 2000–2005. We use only five members (and as before, a 5-year window for each to increase the sample size) to estimate the ensemble standard deviation of the two anomalies (separately, as that standard deviation may differ at mid-century and the end of the century) at each grid point and compare the actual error when approximating the “true” anomalies (i.e., those obtained on the basis of the full ensemble) by increasingly larger ensemble sizes to the 95 % confidence bound, calculated by the formula (here i indicates the grid cell, and c indicates the period in the century considered for the anomalies). In Figs. 3 and 4, we show fields of the ratio of actual error to the 95 % bound, as the ensemble size increases. Red areas are ones where the ratio exceeds 100 %, i.e., where the bound was exceeded by the actual error, which we would expect to happen only over 5 % of the surface. As can be gauged even by eye, only small and sparse areas appear where the actual error exceeds the expected error, especially if land regions are considered (incidentally, these indices have been mostly used over land areas, as input to impact analyses). The prevalence of red areas over the oceans could be due to an underestimation of linked to the use of the 5-year windows and the autocorrelation possibly introduced, consistent with ocean quantities having more memory than land quantities, but we do not explore that further here. Over the majority of the Earth's surface, particularly when errors are estimated for ensemble sizes of 20 or more, the bound is a good measure providing an accurate estimate of the error behavior according to normal distribution theory. Tables B1 through B4 in the Appendix confirm this by reporting percentages of surface areas (distinguishing global, land-only or ocean-only aggregation) where the actual error exceeds the bound, i.e., where the values of the fields exceed 100 %. As can be assessed for all metrics considered in our analysis, 20 ensemble members consistently keep such fraction at or under 5 % for the CESM model ensemble, while the coarser-resolution CanESM requires 25 ensemble members for that to be true.
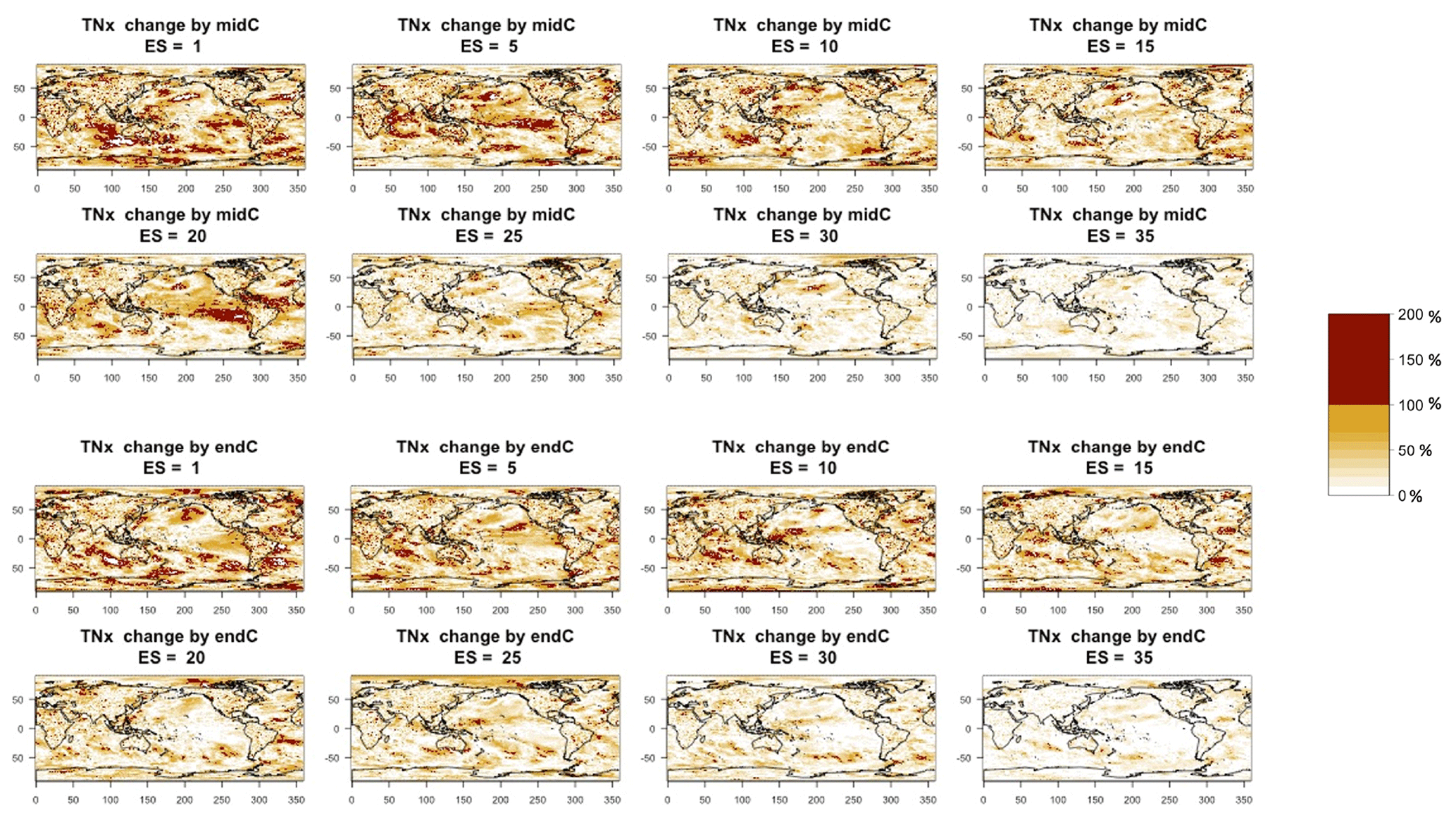
Figure 3Error in the estimation of anomalies in TNx by mid-century (top two rows) and end of century (bottom two rows) from the CESM ensemble. In each plot, for increasing ensemble sizes, the color of each grid point indicates the ratio (as a percentage) between actual error and the 95 % confidence bound. Values of less than 100 % indicate that the actual error in estimating the anomaly at that location is contained within the bound. The color scale highlights in dark red the values above 100 %, whose total fraction is reported in Table B1.
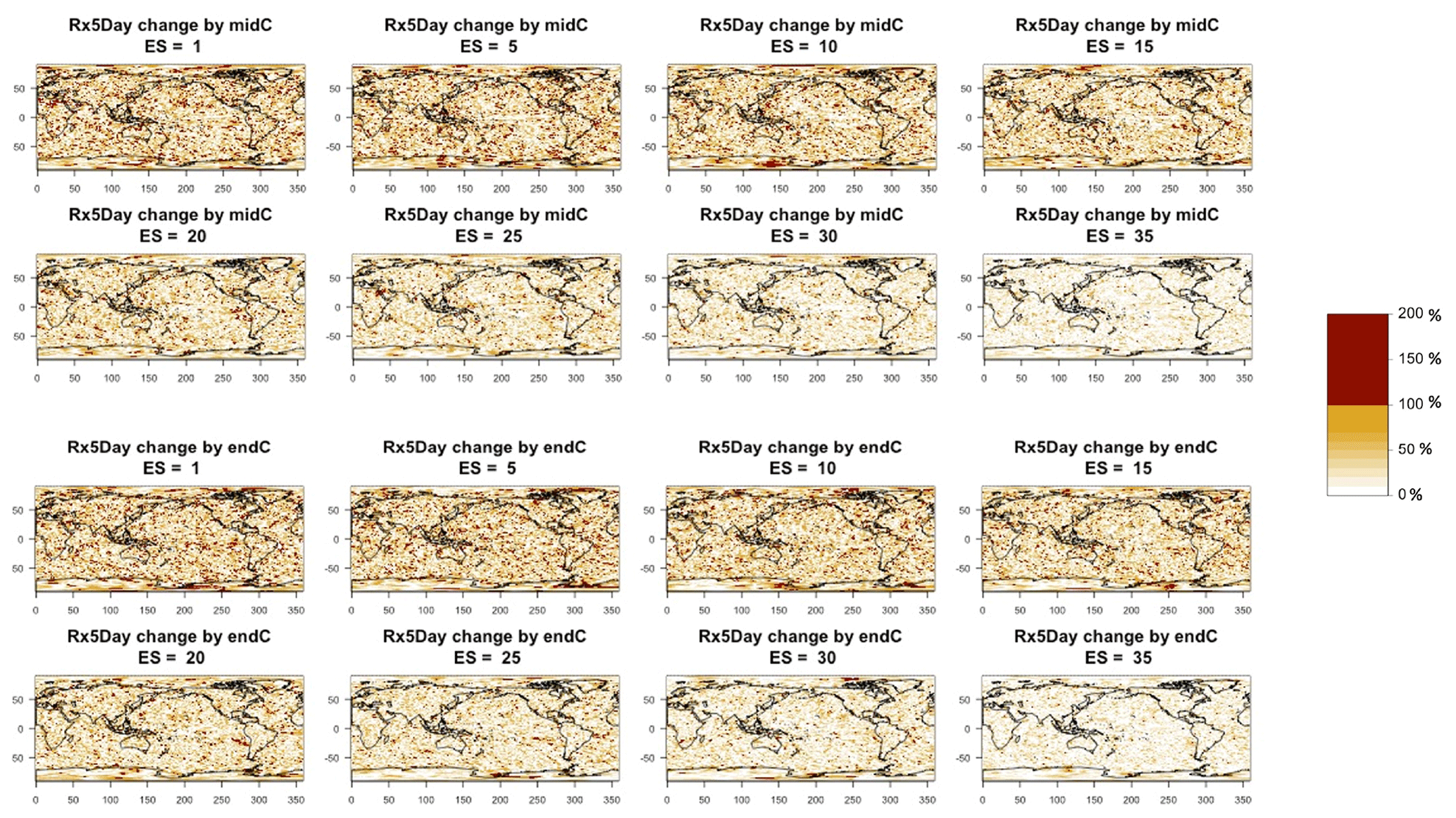
Figure 4Error in the estimation of anomalies in Rx5Day by mid-century (top two rows) and end of century (bottom two rows) from the CESM ensemble. In each plot, for increasing ensemble sizes, the color of each grid point indicates the ratio (as a percentage) between actual error and the 95 % confidence bound. Values of less than 100 % indicate that the actual error in estimating the anomaly at that location is contained within the bound. The color scale highlights in dark red the values above 100 %, whose total fraction is reported in Table B3.
Overall, these results attest to the fact that we can use a small ensemble of five members to estimate the population standard deviation and plug it into the formula for the standard error of the sample mean as a function of sample size. Imposing a ceiling for this error allows us then to determine how large an ensemble should be, in order to approximate the forced component to the desired level of accuracy. This holds true across the range of spatial scales afforded by these models, from global means all the way to grid-point values.
4.2 GEV results
As explained in Sect. 3, the extreme metrics we chose can be fit by a generalized extreme value distribution, and return levels for arbitrary return periods derived, with their confidence interval. In this section, we ask two questions:
-
How many ensemble members are needed for the estimates to stabilize and the size of the confidence interval not to change in a substantial way?
-
Is there any gain in applying GEV fitting rather than simply “counting” rare events across the ensemble?
Here, we show results for our two main metrics, choosing two different locations for each. These results are indicative of what happens across the rest of locations (see Fig. C9), for the other metrics and the other model considered (see Appendix for a sampling of those).

Figure 5Return levels for TNx at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 40), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble (central and confidence interval bounds), which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show return levels for the same return periods estimated by counting, i.e., computing the empirical cumulative distribution function of TNx on the basis of the n×11 years in the sample, where n is the ensemble size. Note that in the 100-year return level plots the first such dot is obtained by interpolation of the last two values of the CDF, since the sample size is less than 100 (see text). The first three rows show results for a location in India, while the following three rows show results for a location in western South America (see Fig. C9).
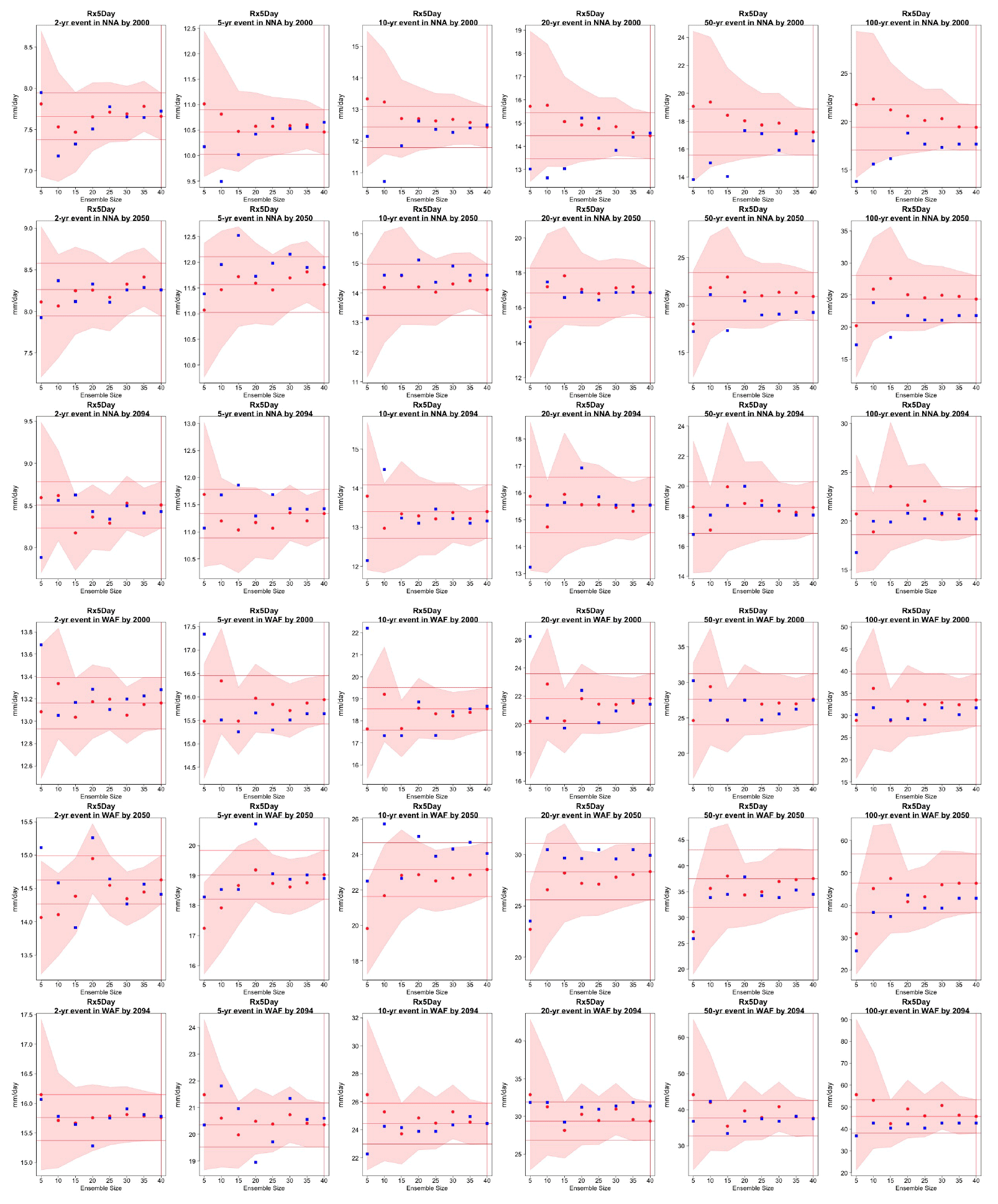
Figure 6Return levels for Rx5Day at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 40), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble (central and confidence interval bounds), which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show return levels for the same return periods estimated by counting, i.e., computing the empirical cumulative distribution function of Rx5Day on the basis of the n×11 years in the sample, where n is the ensemble size. Note that in the 100-year return level plots the first such dot is obtained by interpolation of the last two values of the CDF, since the sample size is less than 100 (see text). The first three rows show results for a location in northern North America, while the following three rows show results for a location in west Africa (see Fig. C9).
Figures 5 and 6 and several more in the Appendix compare for each of the six return levels (along the columns), and across the three projection dates (along the rows), the behavior of the GEV central estimates (red dots) and 95 % confidence intervals (pink envelope, calculated according to the maximum likelihood approach) based on an increasing ensemble size (along the x axis) to the “truth” obtained by the full ensemble, which is drawn as a reference across each plot as horizontal lines. We also compute estimates of the central quantities based on computing the empirical cumulative distribution function (see Sect. 3.1) from the same data points. These empirical estimates are added to each plot as blue dots for each of the ensemble sizes considered. Note that also for these empirical estimates we use 11-year windows for each ensemble member, so that the sample is exactly the same as that used for fitting the corresponding GEV. Only the left-most blue dot in the 100-year return level panels is based on interpolating the values of the empirical CDF, which for that sample size is based on only 55 data points. We first observe that in the great majority of cases the central estimate settles within the “true” confidence interval as soon as the ensemble comprises 15 or 20 members. This is true for both model ensembles, i.e., both when the truth is identified through 40 and through 50 ensemble members, as the corresponding plots in the Appendix confirm. Therefore, if all that concerns us is the central estimate, an ensemble of 20 members, from which we sample 11-year windows to enrich the sample size, delivers an estimate of the “truth” within its confidence interval. When an estimate of the uncertainty is concerned, however, the truth remains by definition an unattainable target, as the size of the confidence intervals is always bound to decrease for larger sample sizes. The behavior of the confidence intervals for the return level estimates in the plots, however, suggests that there might be only marginal gains for ensemble sizes beyond 30 for both models. The value of this general result will benefit from an analysis of larger ensembles. In addition, the value of increasing the sample size should always be judged on the basis of the actual size of the 95 % confidence intervals in the units of the quantity of interest and what that size means for managing risks associated with these extremes. This is an aspect that, however, goes beyond the scope of our work. As for the results of the empirical counting approach, i.e., the blue point estimates, we can assess that in the majority of cases but not across the board when we look closely to all the plots in the Appendix, they do not deviate significantly from the central estimates based on fitting the GEV using the same sample size. However, while the latter can provide a measure of uncertainty through confidence intervals, the estimates based on counting events do not come with uncertainty bounds. Another advantage of using the GEV is the ability to extrapolate to even more rare events than the ensemble size would allow to robustly estimate, not underplaying the risk of statistical extrapolations as a general rule.
Further statistical precision could be attained by relaxing the quasi-stationarity assumption and extending the analysis period to contain a longer window of years. Exchanging time for ensemble members, however, when beyond a decade's worth, necessitates in most cases the inclusion of temporal covariates: for example, indicators of the phase and magnitude of major modes of variability known to affect the behavior of the atmospheric variables in question over multi-decadal scales. The inclusion of covariates of course adds another source of fitting uncertainty.
4.3 Characterizing internal variability
After concerning ourselves with the characterization of the forced component, we turn to the complementary problem of characterizing internal variability. Rather than aiming at eliminating the effects of internal variability as we have done so far in the estimation of a forced signal, we take here the opposite perspective, wanting to fully characterize its size and behavior over space and time. After all, the real world realization will not be akin to the mean of the ensemble but to one of its members, and we want to be sure to estimate the range of variations such members may display. Thus, we ask how large the ensemble needs to be to fully characterize the variations that the full-size ensemble produces, which once again we take as the truth (as mentioned, the answer to this question can be seen as a systematic confirmation that five members are sufficient for the estimation of σ, one result that we only indirectly affirmed so far). We also ask how large an ensemble is needed to detect changes in the size of internal variability with increasing external forcing. Our definition of internal variability here is simply the size of the ensemble variance. We tackle both of these questions directly at the grid-point scale, as that answer can serve as an upper bound for the characterization of variability at coarser spatial scales. Figures 7 through 10 synthesize our findings for both of these questions.
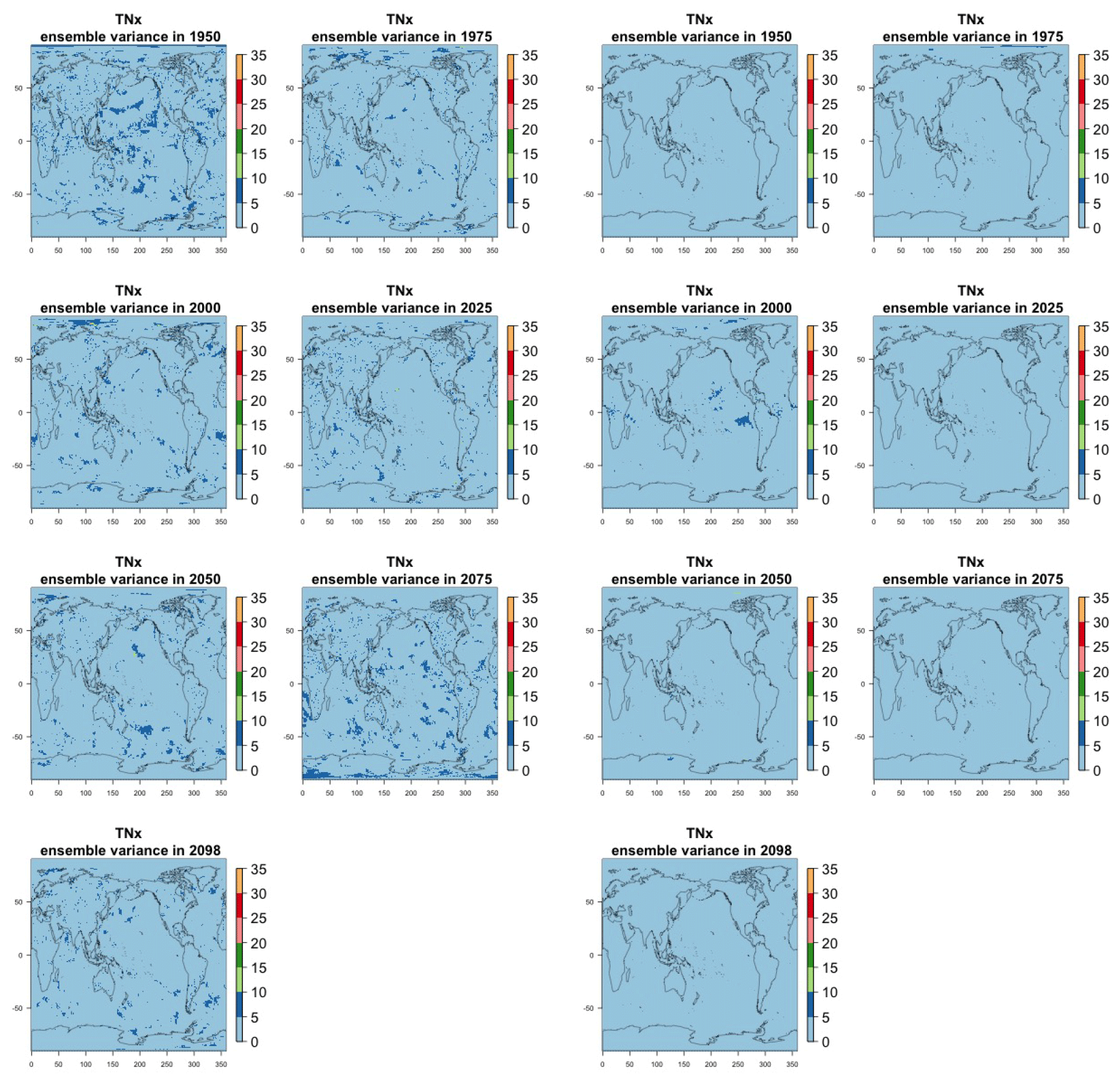
Figure 7Estimating the ensemble variance for TNx: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate an ensemble variance at that location that is statistically indistinguishable from that computed on the basis of the full 40-member ensemble, using an F test to test the null hypothesis of equality in variance. The results of the first two columns use only the specific year for each of the ensemble members. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
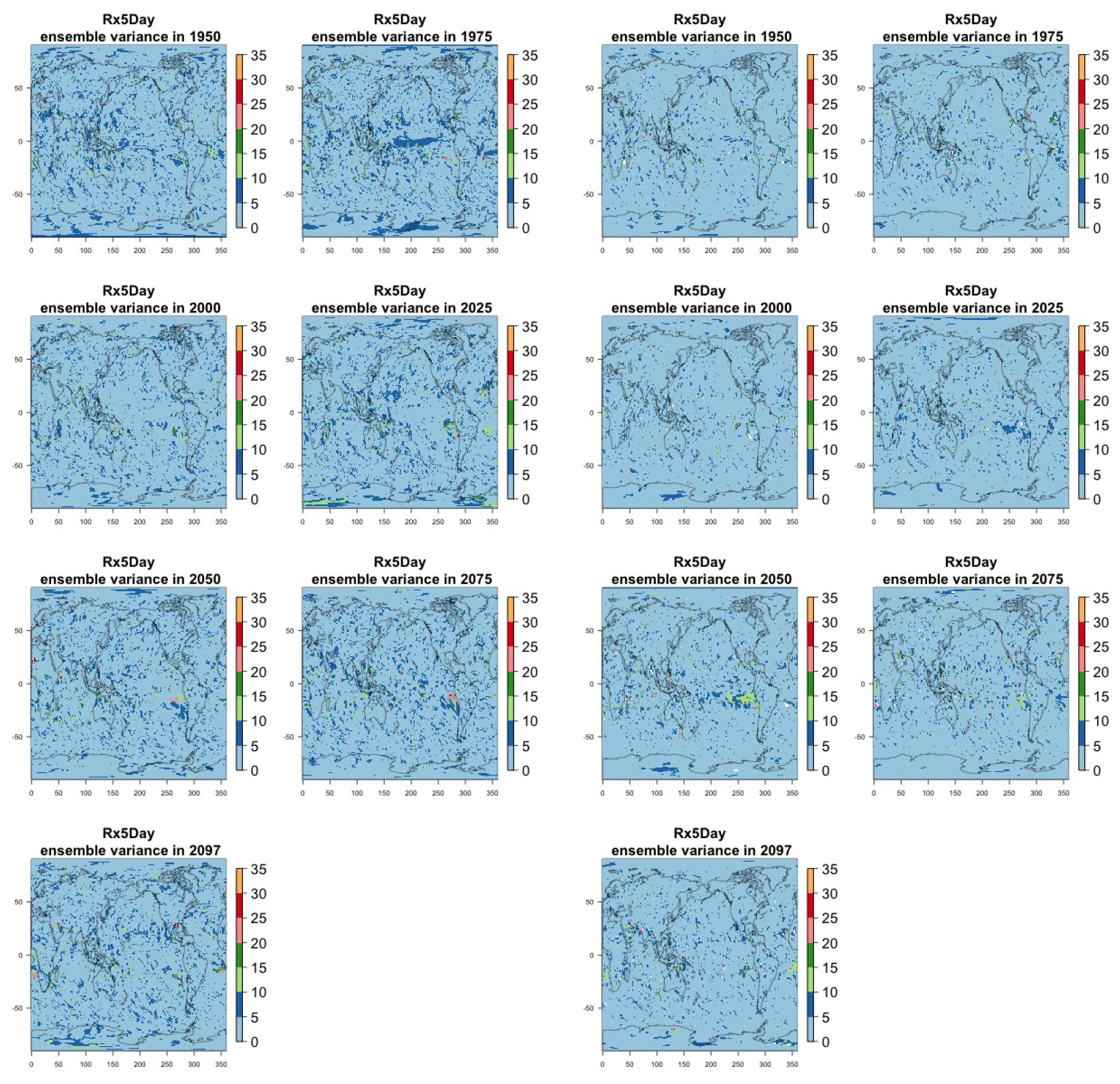
Figure 8Estimating the ensemble variance for Rx5Day: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate an ensemble variance at that location that is statistically indistinguishable from that computed on the basis of the full 40-member ensemble, using an F test to test the null hypothesis of equality in variance. The results of the first two columns use only the specific year for each of the ensemble members. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
The two columns on the left-hand side of Fig. 7 show for several years along the simulation of TNx how many ensemble members are needed (denoted by the colors; see legends) in order to estimate an ensemble variance at each grid point that is not statistically distinguishable from the same variance estimated by the full 40-member ensemble. We use a traditional F-test approach to test the null hypothesis of equality in variance. Note that we do this at various times along the length of the simulation (1950, 1975, 2000, 2025, 2050, 2075, 2100) because we account for the possibility that internal variability might change over its course with increasing external forcing, but for now we remain agnostic on this issue. For all times considered, five members are sufficient to estimate an ensemble variance indistinguishable, statistically, from that which would be estimated using the full ensemble at most grid points over the Earth's surface, as the light blue color indicates. For some sparse locations, however, 10 members are needed to achieve the same type of accuracy. The same type of figure for the precipitation metric, Fig. 8, left two columns, confirms that for this noisier quantity a larger extent of the Earth's surface needs ensemble sizes of 10 or more to accurately estimate the behavior of the full ensemble variance. The two right-hand columns in Fig. 7 show corresponding plots where now most of the Earth's surface only requires five members. This is the result of “borrowing strength” in the estimation of the ensemble variance by using a 5-year window around the date as we have done for the analysis of σt in the previous sections. This solution addresses the problem of estimating the variance for both temperature and precipitation metrics, as Fig. 8 confirms, reducing also for the latter the number of grid points that require more statistical power to a noisy speckled pattern. Similar figures in the Appendix attest to this remaining true for the other model and the remaining metrics as well. We note here that the patterns shown in some of these figures have indeed the characteristics of noise. To minimize that possibility, we have applied a threshold for the significance of the p values from the F test obtained through the method that controls the false discovery rate (Ventura et al., 2004). The method has been shown to control for the false identification of significant differences “by chance” due to repeating statistical tests hundreds or thousands of times, as in our situation. The same method has been proven effective in particular for multiple testing over spatial fields, despite the presence of spatial correlation (Ventura et al., 2004; Wilks, 2016). We fix the false discovery rate to 5 %.
Detecting changes in the size of the variance over time by comparing two dates over the simulation is a problem that we expect to require more statistical power than the problem of characterizing the size of the variance at a given point, as the difference between stochastic quantities is affected by larger uncertainty than the quantities individually considered, unless those are strongly correlated. Figure 9 shows the ensemble size required to detect the same changes in the ensemble variance of TNx that the full ensemble of 40 members detects. Each plot is at the intersection of a column and a row corresponding to two of the dates considered in the previous analysis, indicating that the solution applies to detecting a change in variance between those two dates, as the title of each plot specifies. Here again we use the F test and the method for controlling the false discovery rate.
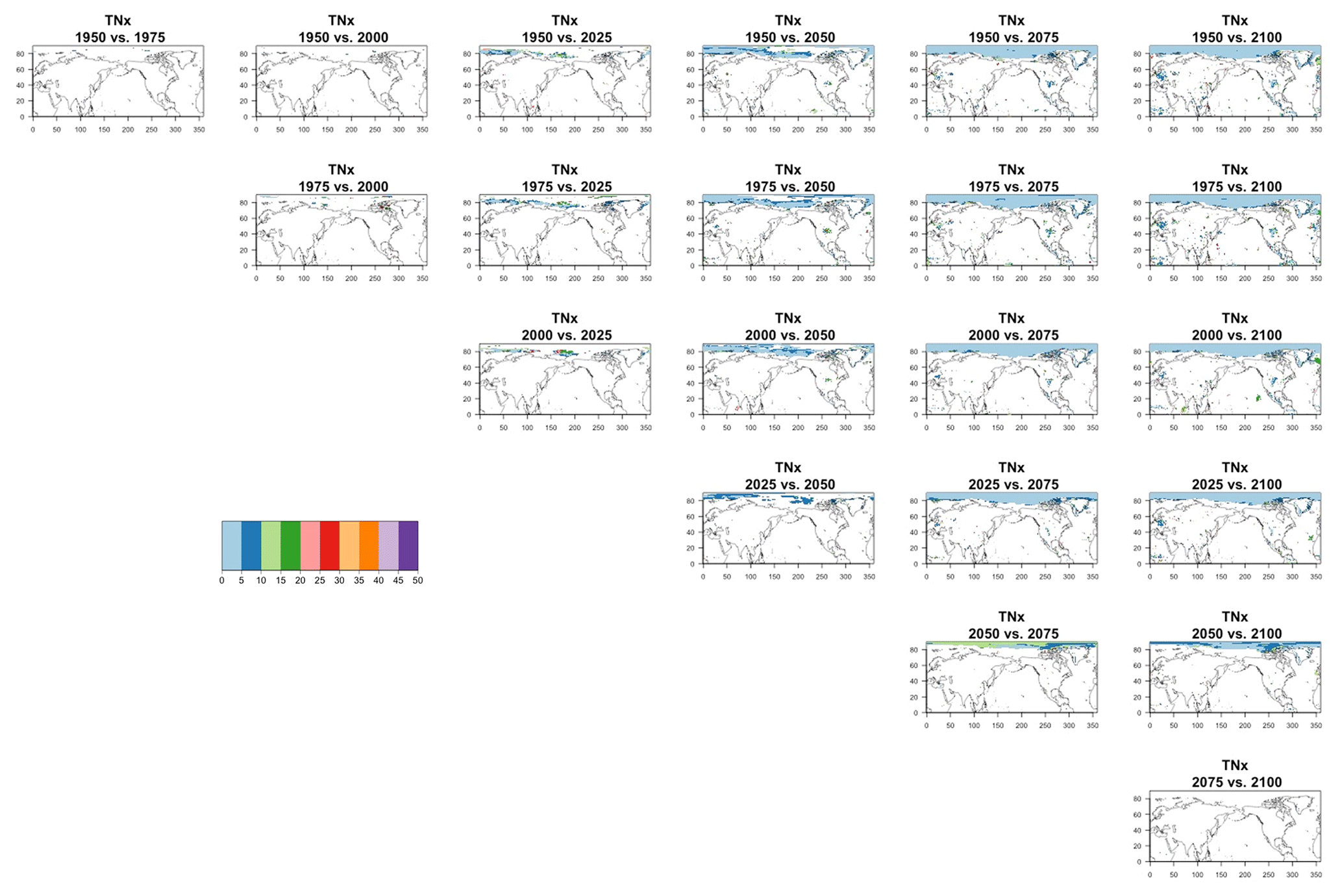
Figure 9Estimating changes in ensemble variance for TNx: each plot corresponds to a pair of years along the simulation (same set of years as depicted in Figs. 7 and 8 above). Colored areas are regions where on the basis of the full 40-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here, the sampling size is increased by using 5 years around each date. We only show the Northern Hemisphere, as no region in the Southern Hemisphere shows significant changes in variance for this quantity.
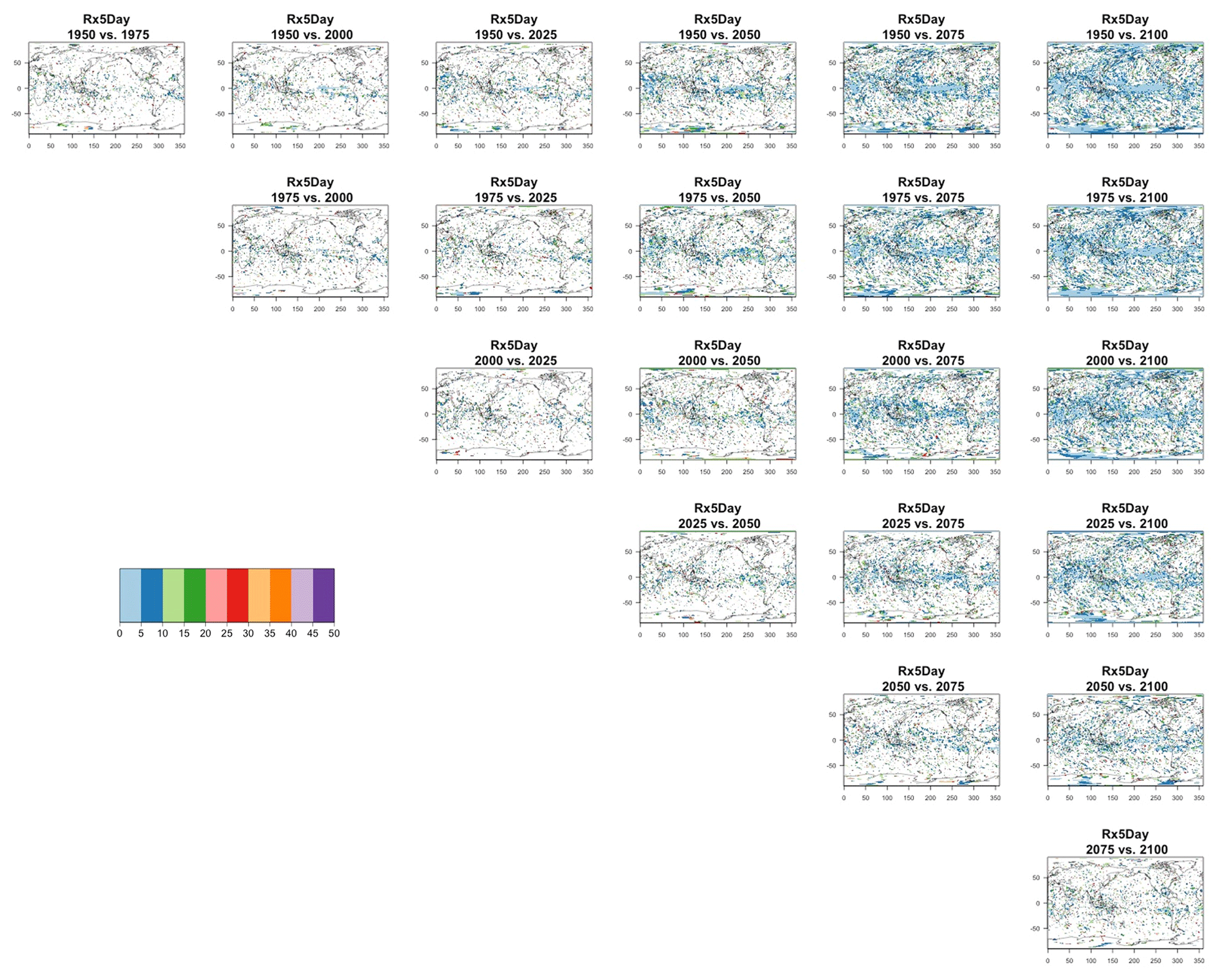
Figure 10Estimating changes in ensemble variance for Rx5Day: each plot corresponds to a pair of years along the simulation (same set of years as depicted in Figs. 7 and 8 above). Colored areas are regions where on the basis of the full 40-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here, the sampling size is increased by using 5 years around each date.
Blank areas are regions where the full ensemble has not detected any changes in the ensemble variance at that location when comparing the two dates. Colored areas are regions where such change has been detected by the full ensemble, and the color indicates what (smaller) ensemble size is sufficient to detect the same change. Here, as in the previous analysis, a significant change is detected when the F test for the ratio of the two variances that are being compared across time has a p value smaller than the threshold determined by applying the false discovery rate method and fixing the false discovery rate to 5 %. These results are obtained by increasing the sample size using 5 years around the dates, as in the right-hand columns of Figs. 7 and 8. In the case of TNx, a metric based on daily minimum temperature, the changes are confined to the Arctic region and in most cases the ensemble size required is again five, with only one instance where the changes between mid-century and end of century require consistently a larger ensemble size over an appreciable extent (as many as 15 members over the region). When we conduct the same analysis on the precipitation metric, shown in Fig. 10, we are presented with a spatially noisier picture, with changes in variance scattered throughout the Earth's surface, especially over the oceans. In the case of this precipitation metric, the ensemble size required is in many regions as large as 15 or 20 members. These results are made clearer by Figs. C30 and C31 in the Appendix, where the grid boxes where significant changes are present are gathered into histograms (weighted according to the Earth's surface fraction that the grid boxes represent) that show the ensemble size required along the x axis. We highlight in those figures the fact that for the temperature-based metric only three histograms, corresponding to three specific time comparisons, gather grid boxes covering more than 5 % of the Earth's surface, while the coverage is more extensive than 5 % for all time comparisons for the precipitation metric. These results are representative of the remaining metrics and the alternative model as Figs. C20 through C41 in the Appendix.
We do not show it explicitly here, as it is not the focus of our analysis, but, for both model ensembles, when the change is significant, the ensemble variance increases over time for both precipitation metrics, indicating that the ensemble spread increases with the strength of external forcing over time under RCP8.5. This is expected as the variance of precipitation increases in step with its mean. For the temperature-based metrics, the changes, when significant, are mostly towards an increase in variance (ensemble spread) with forcings for hot extremes (TNx and TXx, the hottest night and day of the year), for which the significant changes are mostly located in the Arctic region. The ensemble spread decreases instead for cold extremes (TNn and TXn, the coldest night and day of the year), for which the significant changes are mostly located in the Southern Ocean.
4.4 Signal-to-noise considerations
Another aspect that is implicitly relevant to the establishment of a required ensemble size, if the estimation is concerned with emergence of the forced component, or, more in general, with “detection and attribution”-type analysis is the signal-to-noise ratio of the quantity of interest. Assuming as we have done in our study that the quantity of interest can be regarded as the mean μ of a noisy population, the signal-to-noise ratio is defined as , where σ is the standard deviation of the population. A critical threshold, say K, for SN is usually set at K=1 or 2, and it is immediate to derive the sample size required for such threshold to be hit, by computing the value of n that makes , i.e., . Figure 11 shows two maps of the spatially varying ensemble sizes required for the signal-to-noise ratio to exceed 2, when computing anomalies at mid-century for the two metrics from the CESM ensemble. In the Appendix, we show maps for the remaining metrics and CanESM. The anomalies are computed as 5-year mean differences, as in Sect. 4.1 under RCP8.5. If the majority of the Earth's surface requires only two to four ensemble members to be averaged for the temperature metric to reach the SN value of 2, the Southern Ocean and the Arctic, together with some limited regions over land, need more statistical power, up to 18 ensemble members. The pattern remains similar, but the requirements enhanced for the hottest day of the year (TXx, shown in Fig. C42). Cold extremes evidently are more substantially affected by noise over larger portions of the land regions (TNn and TXn, again in Fig. C42). The behavior of the precipitation metrics is qualitatively very different, with the great majority of the globe not reaching that level of SN even when averaging 40 members, as the white areas in Figs. 11, bottom panel, and C42, last panel, signify. This discussion is also model specific. Figure C43 shows the same type of results when using CanESM, a model running at a coarser resolution which we therefore expect to show an emergence of the signal from the noise relatively more easily. This is confirmed by the homogeneous light blue color for the temperature metrics in Fig. C43, indicating that between two and six ensemble member averages reach an SN of 2. It remains the case also for CanESM, however, that the noise affects substantially SN for the precipitation metrics.
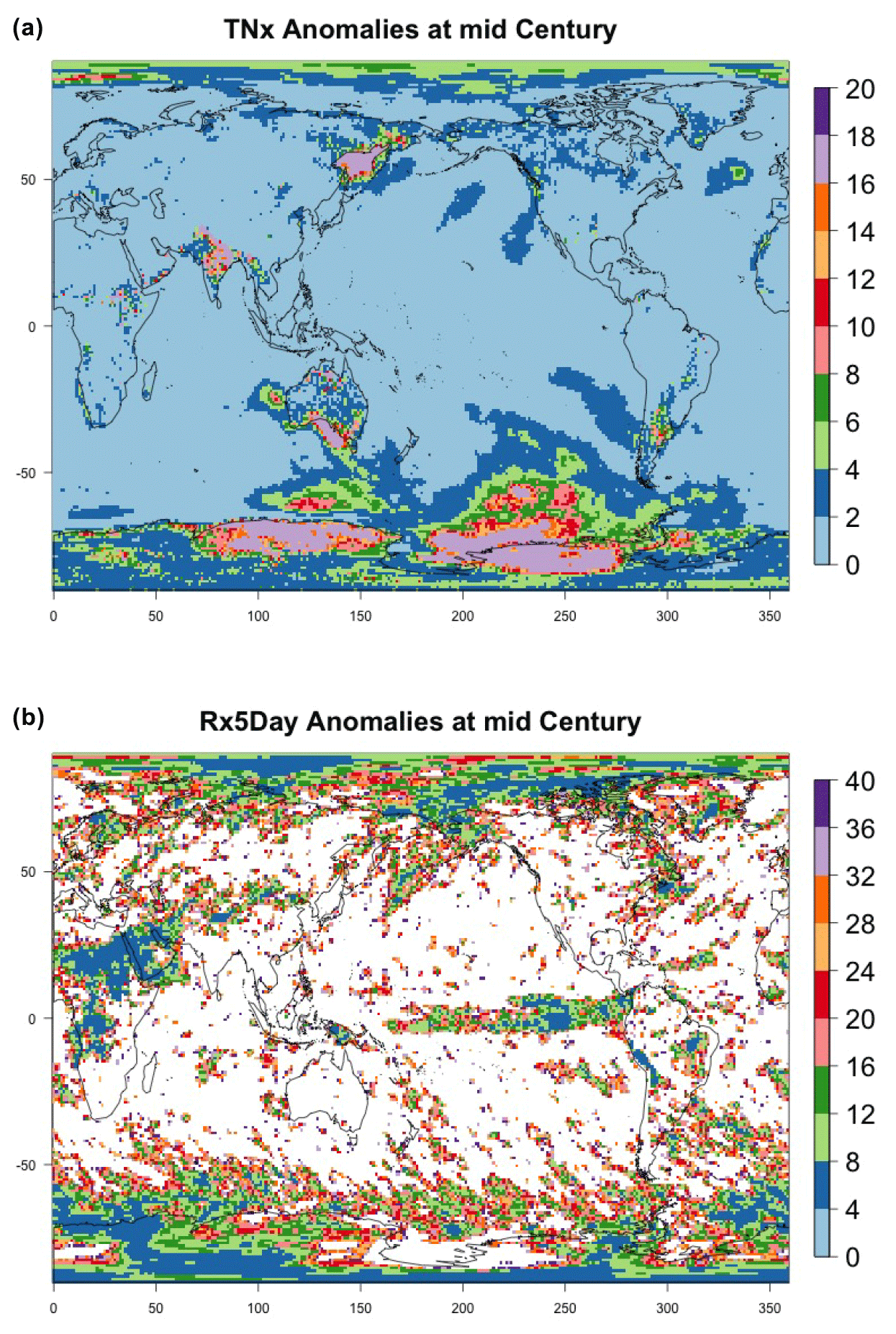
Figure 11Ensemble size n required for the signal-to-noise ratio of the grid-point scale anomalies to exceed 2 (anomalies defined as the mean of 2048–2052 minus the historical baseline taken as 2000–2005). Results are shown for CESM and hottest night (TXn, a) and wettest pentad (Rx5Day, b) of the year.
In this study, we have addressed the need for deciding a priori the size of a large ensemble, using an existing five-member ensemble as guidance. Aware that the optimal size ultimately depends on the purpose the ensemble is used for, and in order to cover a wide range of possible uses, we chose metrics of temperature and precipitation extremes and we considered output from grid-point scale to global averages. We tackled the problem of characterizing forced changes along the length of a transient scenario simulation and that of characterizing the system's internal variability and its possible changes. By using a high emission scenario like RCP8.5, but considering behaviors all along the length of the simulations, we are also implicitly addressing a wide range of signal-to-noise magnitudes. Using the availability of existing large ensembles with two different models, CESM1-CAM5 and CanESM2, we could compare our estimates of the expected errors that a given ensemble size would generate with actual errors, obtained using the full ensembles' estimates as our “truth”.
First, we find that for the many uses that we explored, it is possible to put a ceiling on the expected error associated with a given ensemble size by exploiting a small ensemble of five members. We estimate the ensemble variance at a given simulation date (e.g., 2000, or 2050, or 2095), which is the basis for all our error computations, on the basis of five members, “borrowing strength” by using a window of 5 years around that date. The results we assess are consistent with assuming that the quantities of interest are normally distributed with standard deviation , where σ can be estimated on the basis of the five members available: the error estimates and therefore the optimal sizes computed on the basis of choosing a given tolerance for such errors provide a safe upper bound to the errors that would be committed for a given ensemble size n. This is true for all metrics considered, both models and the full range of scales of aggregation. When we compare such estimates (verified by the availability of the actual large ensembles), there appears to be a sweet spot in the range of ensemble sizes that provides accurate estimates for both forced changes and internal variability, consisting of 20 or 25 members. The larger of these sizes also appears approximately sufficient to conduct an estimation of rare events with a probability of occurrence each year as low as 0.01, by fitting a GEV and deriving return levels and their confidence intervals. In most cases (locations around the globe, times along the simulation and metrics considered), enlarging the sample size beyond 25 members provides only marginal improvement in the confidence intervals, while the central estimate does not change significantly from the one established using 25 members and in most cases accurately approximating that obtained by the full ensemble.
In all cases considered, a much smaller ensemble size of 5 to 10 members, if enriched by sampling along the time dimension (that is, using a 5-year window around the date of interest) is sufficient to characterize the ensemble variability, while its changes along the course of the simulations under increasing greenhouse gases, when found significant using the full ensemble size, can be detected using 15 or 20 ensemble members.
Some caveats are in order. Obviously, the question of how many ensemble members are needed is fundamentally ill-posed, as the answer ultimately and always depends on the most exacting use to which the ensemble is put. One can always find a higher-frequency, smaller-scale metric and a tighter error bound to satisfy, requiring a larger ensemble size than any previously identified. As tropical-cyclone-permitting and eventually convection-permitting climate model simulations become available, these metrics will be more commonly analyzed. Even for a specific use, the answer depends on the characteristics of internal variability. The fact that for both the models considered here five ensemble members are sufficient to obtain an accurate estimate of it is promising, but this does not guarantee that five are sufficient for all models. In fact, this could also be invalidated by a different experimental exploration of internal variability: new work is adopting different types of initialization, involving ocean states, which could uncover a dimension of internal variability that has so far being underappreciated (Hawkins et al., 2016; Marotzke, 2019). This would likely change our best estimates of internal variability and with it possibly the ensemble sizes required to accurately estimate it.
With this work, however we have shown a way to attack the problem “bottom up”, starting from a smaller ensemble and building estimates of what would be required for a given problem. One can imagine a more sophisticated setup where an ensemble can be recursively augmented (rather than assuming a fixed five-member ensemble as we have done here) in order to approximate the full variability incrementally better. We have also shown that for a large range of questions the size needed is actually well below what we have come to associate with “large ensembles”. There exist other important sources of uncertainties in climate modeling, one of which is beyond reach of any single modeling center, having to do with structural uncertainty (e.g., Knutti et al., 2010). Adopting the perspective of an individual model, however, parameter settings have an equally if not more important role than initial conditions. Together with scenario uncertainty, all these dimensions compete over computational resources for their exploration. The same computational resources may be further stretched by the need for downscaling the results of Earth system model (ESM) ensembles through regional and impact models (Leduc et al., 2019). Our results may provide guidance in choosing how to allocate those resources among these alternative sources of variation.
Table A1Global mean of TNn as simulated by the CESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 35, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
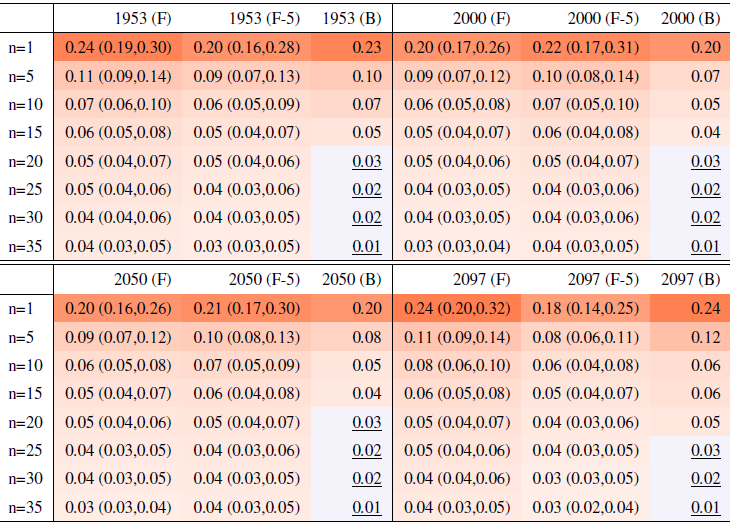
Table A2Global mean of TXx as simulated by the CESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 35, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).

Table A3Global mean of TXn as simulated by the CESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 35, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
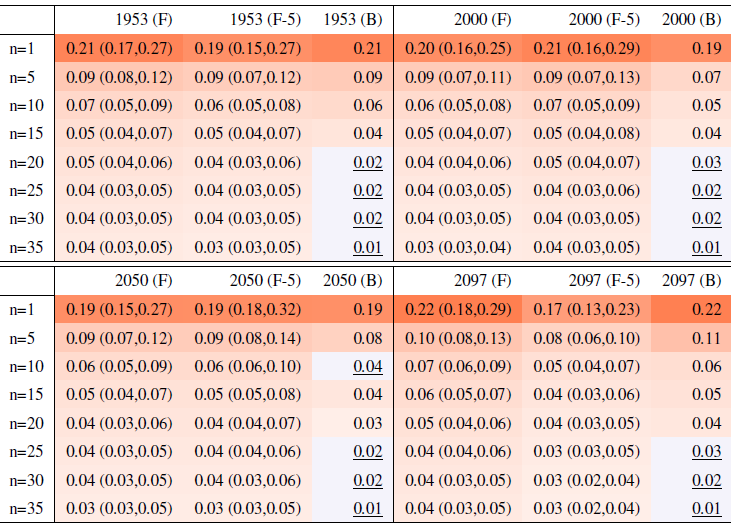
Table A4Global mean of Rx1Day as simulated by the CESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 35, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
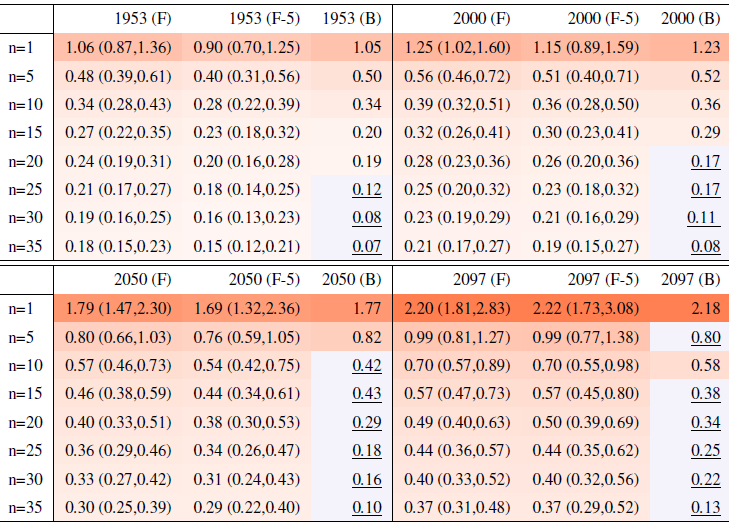
Table A5Global mean of TNx as simulated by the CanESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 40, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
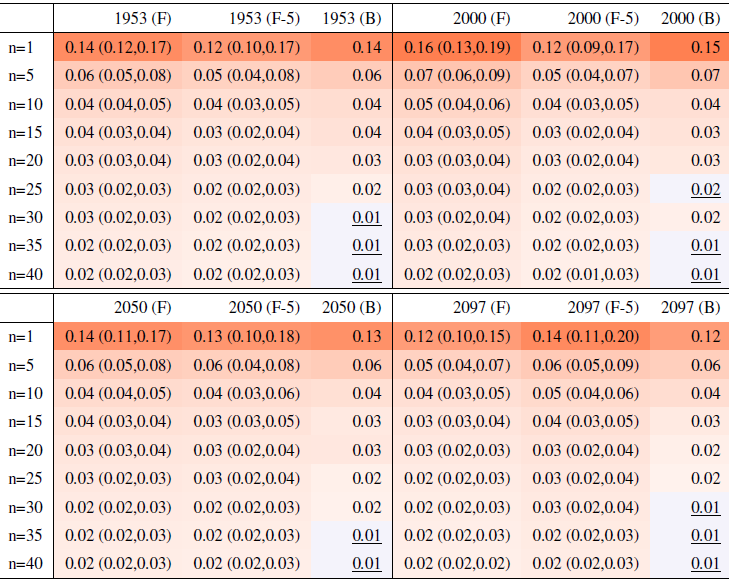
Table A6Global mean of Rx5Day as simulated by the CanESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 40, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
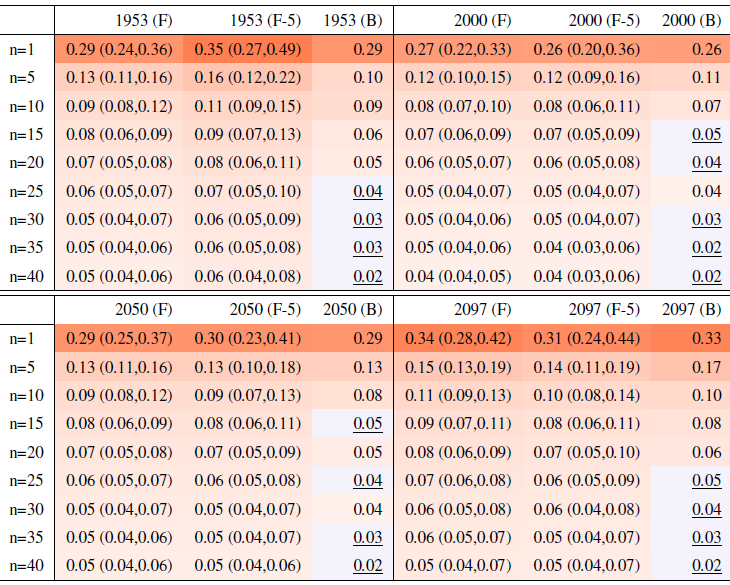
Table A7Global mean of TNn as simulated by the CanESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 40, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
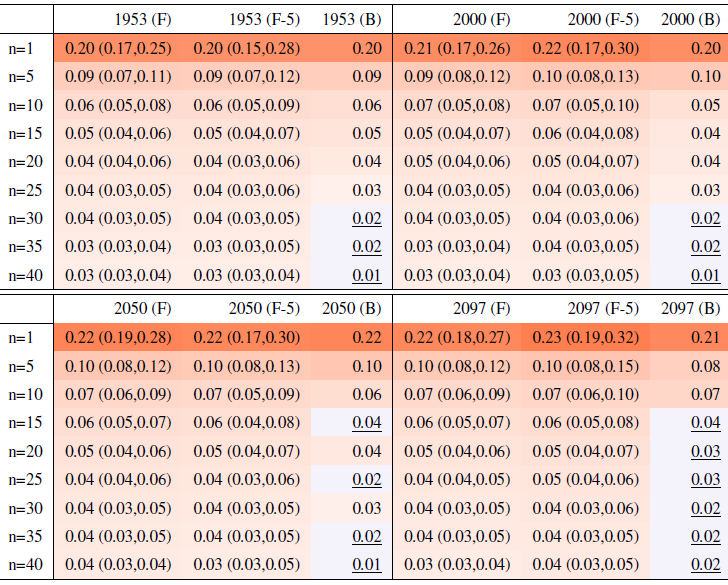
Table A8Global mean of TXx as simulated by the CanESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 40, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
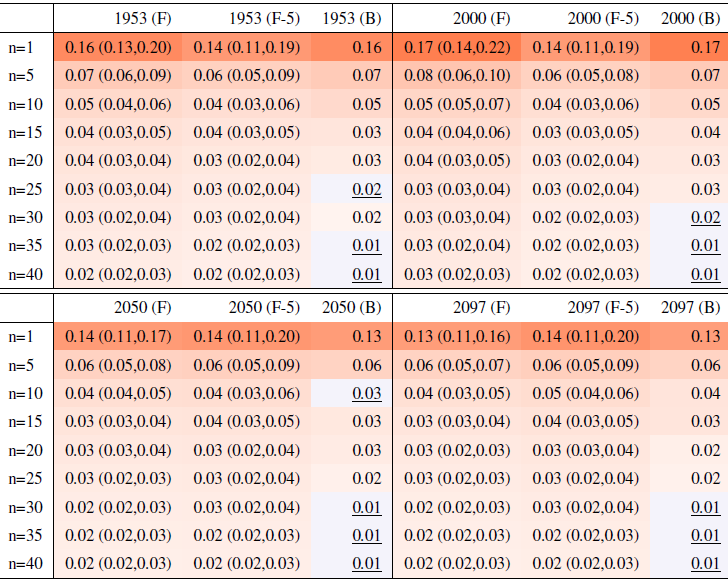
Table A9Global mean of TXn as simulated by the CanESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 40, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
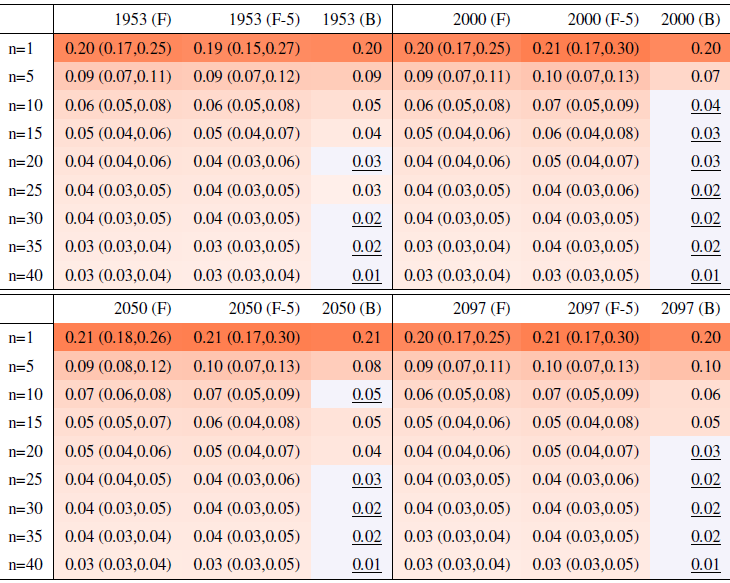
Table A10Global mean of Rx1Day as simulated by the CanESM ensemble: values of the RMSE in approximating the full ensemble mean by the individual runs (first row, n=1) and by ensembles of increasingly larger sizes (from 5 to 40, along the remaining rows). The estimates obtained by the bootstrap approach (columns labeled “(B)”) are compared to the estimates obtained by the formula , where σ is estimated as the ensemble standard deviation using all ensemble members (columns labeled “(F)”, where also the 95 % confidence interval is shown). We also compare estimates derived by plugging into the formula a value of σ estimated by a subset of five ensemble members and 5 years around the year considered (columns labeled “(F-5)”). Results are shown for four individual years along the simulation (column-wise), since σ varies along it. Each cell color reflects the value of the central estimate in the cell, and those cases when the bootstrap estimate is inconsistent with the corresponding F-column estimate are colored in gray (and underlined).
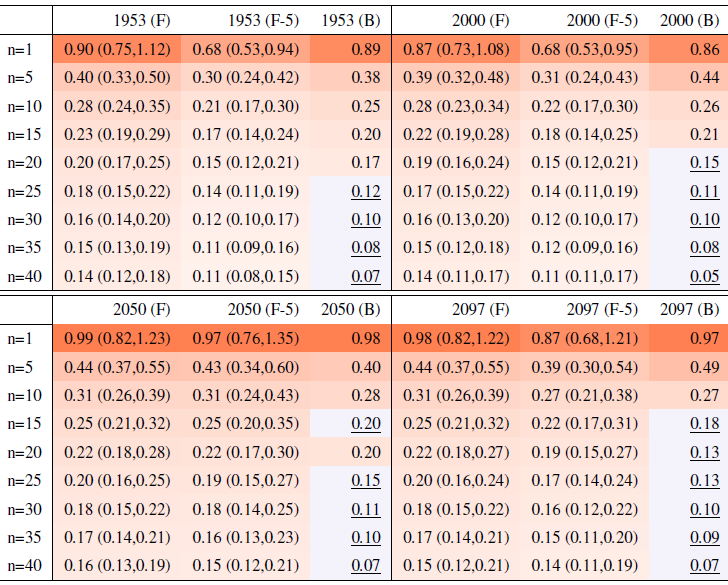
Table B1Percentage of the global, land or ocean surface where the actual errors exceed the errors estimated on the basis of the formula “a priori” using five ensemble members to estimate σ. Results are shown for all temperature extreme metrics, derived from the CESM ensemble whose full size is 40 members. Calculations apply cosine-of-latitude weighting. Results for TNx are summaries of the behavior shown in Fig. 3, i.e., the fraction of surface represented by locations where the error ratio is larger than 100 %. Numbers under small n values are affected by noise, as we randomly choose n members from the full ensemble, only once. As can be gauged, the decreasing behavior of the fractions stabilizes for n≥15. Cell color reflects the value in the cell.
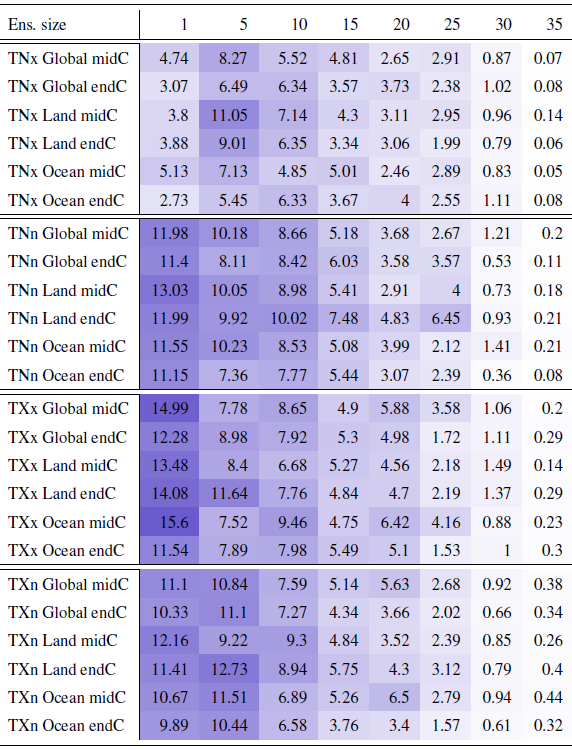
Table B2Percentage of the global, land or ocean surface where the actual errors exceed the errors estimated on the basis of the formula “a priori” using five ensemble members to estimate σ. Results are shown for all temperature extreme metrics, derived from the CanESM ensemble whose full size is 50 members. Calculations apply cosine-of-latitude weighting. Numbers under small n values are affected by noise, as we randomly choose n members from the full ensemble, only once. As can be gauged, the decreasing behavior of the fractions stabilizes for n≥15. Cell color reflects the value in the cell.
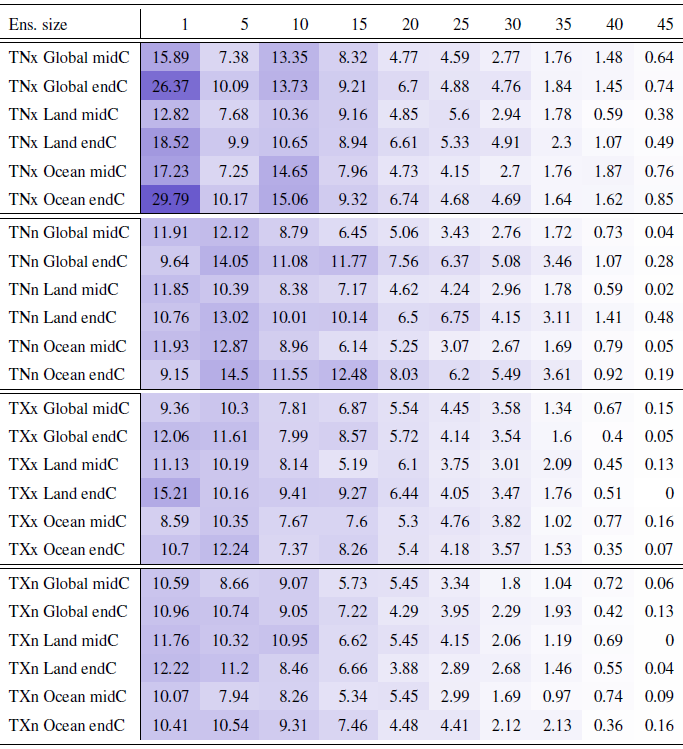
Table B3Percentage of the global, land or ocean surface where the actual errors exceed the errors estimated on the basis of the formula “a priori” using five ensemble members to estimate σ. Results are shown for the two precipitation extreme metrics, derived from the CESM ensemble whose full size is 40 members. Calculations apply cosine-of-latitude weighting. Results for Rx5Day are summaries of the behavior shown in Fig. 4, i.e., the fraction of surface represented by locations where the error ratio is larger than 100 %. Numbers under small n values are affected by noise, as we randomly choose n members from the full ensemble, only once. As can be gauged, the decreasing behavior of the fractions stabilizes for n≥15. Cell color reflects the value in the cell.
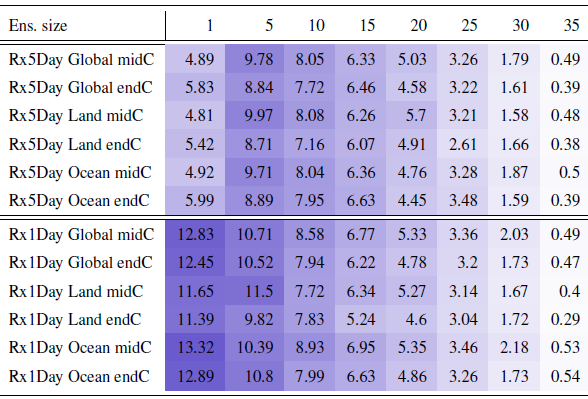
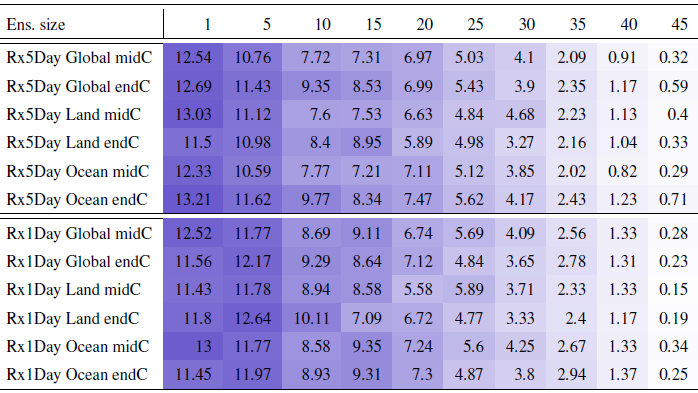
Table B4Percentage of the global, land or ocean surface where the actual errors exceed the errors estimated on the basis of the formula “a priori” using five ensemble members to estimate σ. Results are shown for the two precipitation extreme metrics, derived from the CanESM ensemble whose full size is 50 members. Calculations apply cosine-of-latitude weighting. Numbers under small n values are affected by noise, as we randomly choose n members from the full ensemble, only once. As can be gauged, the decreasing behavior of the fractions stabilizes for n≥15. Cell color reflects the value in the cell.
C1 Forced component
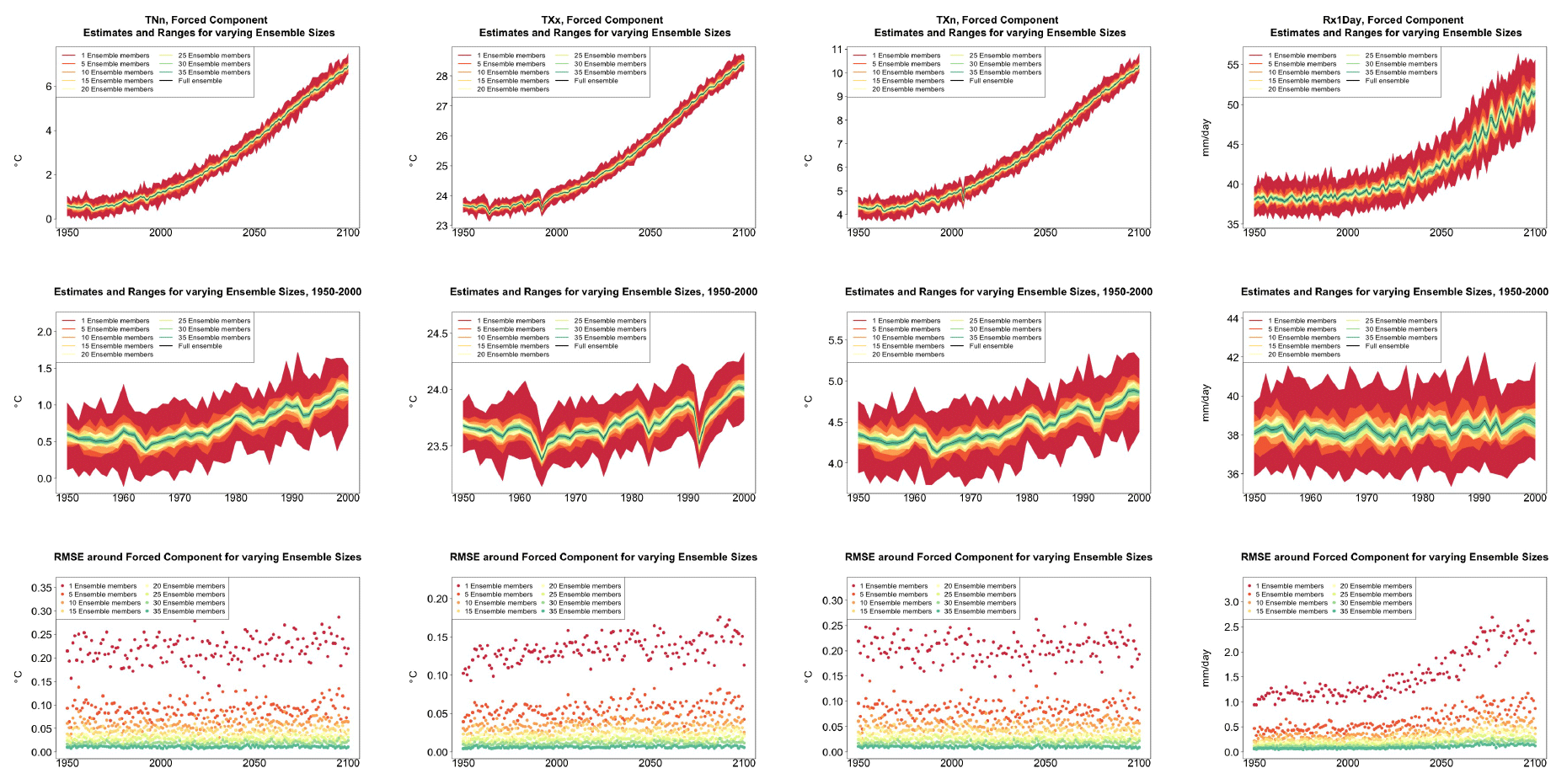
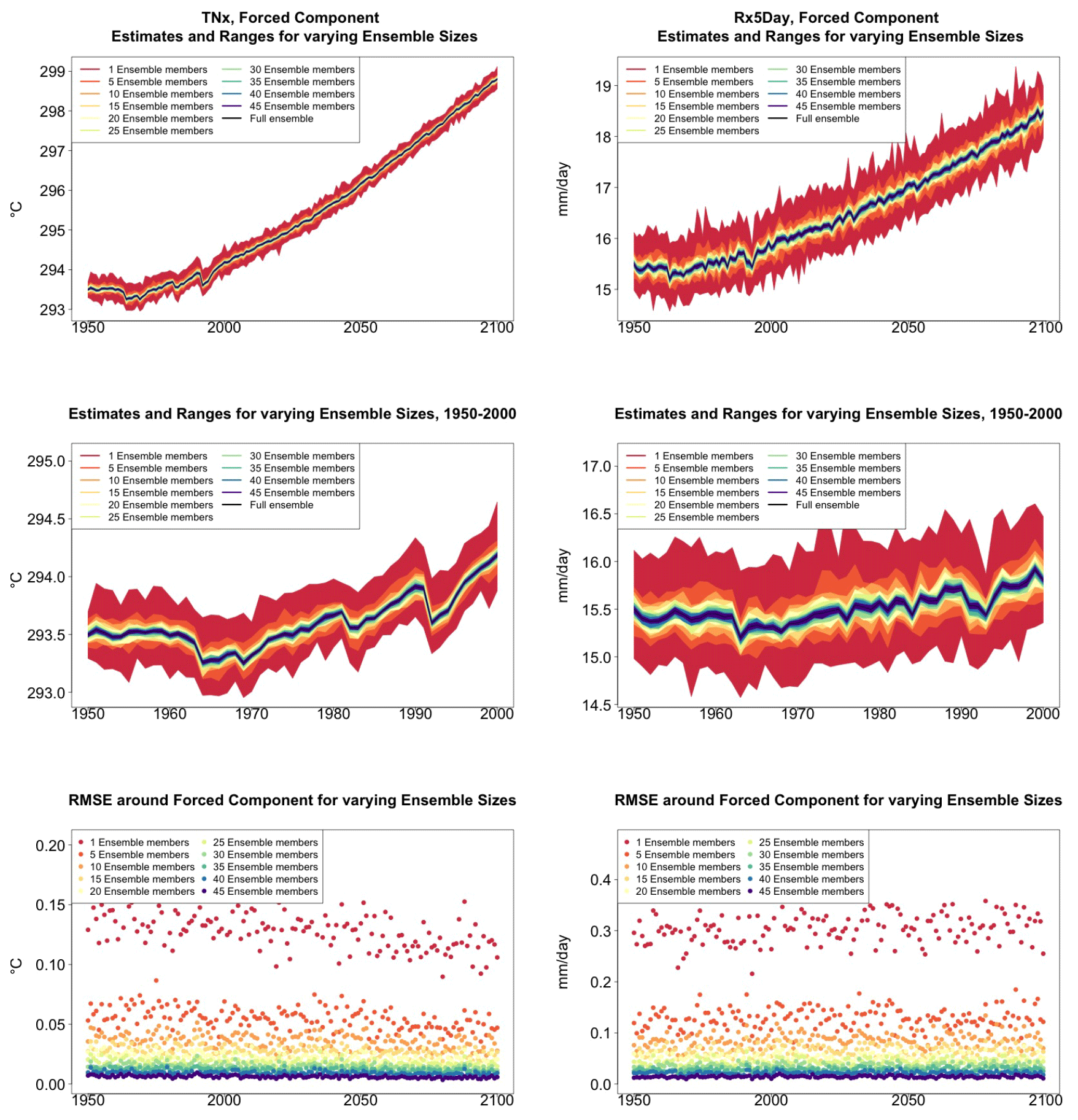
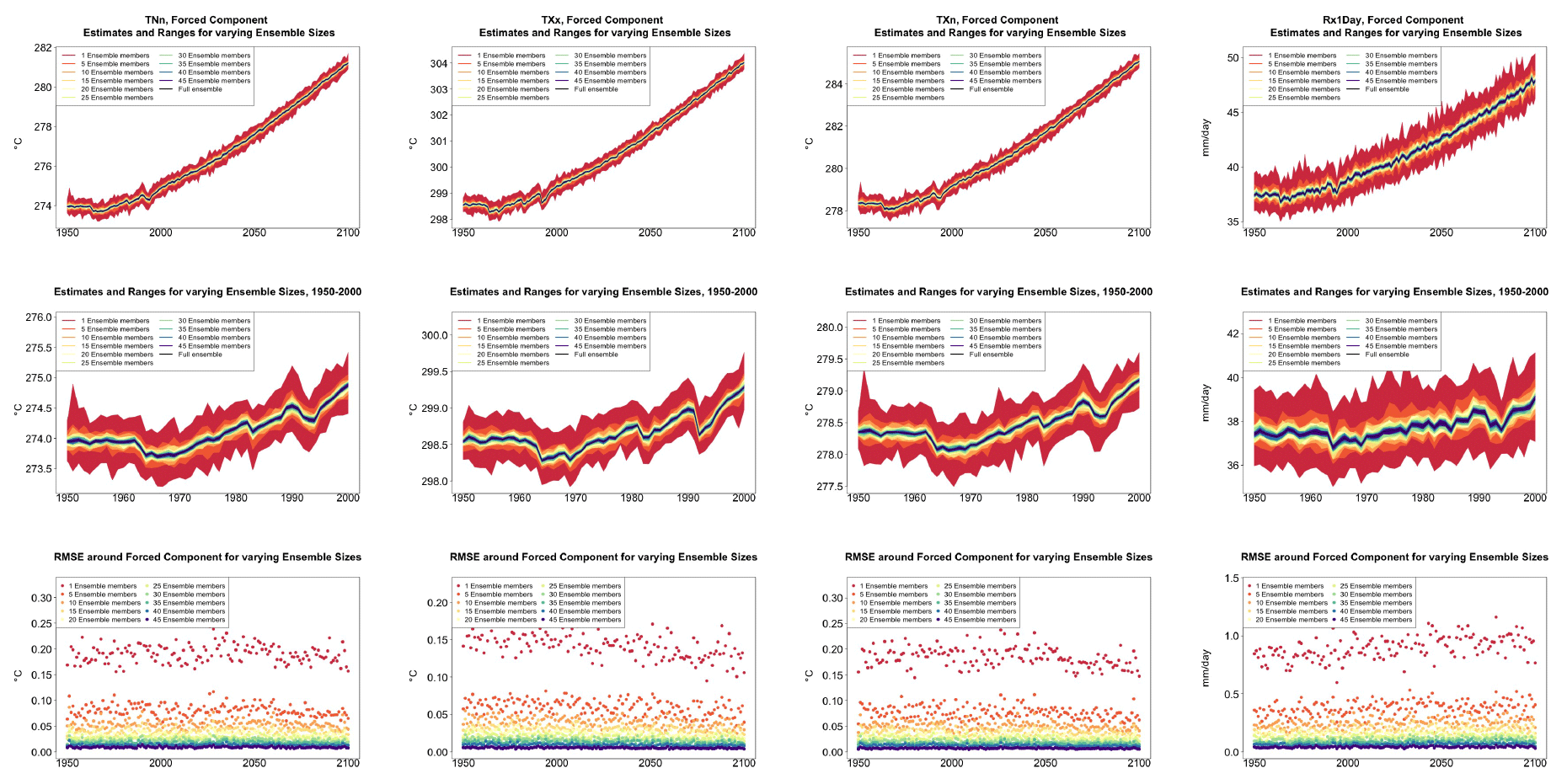

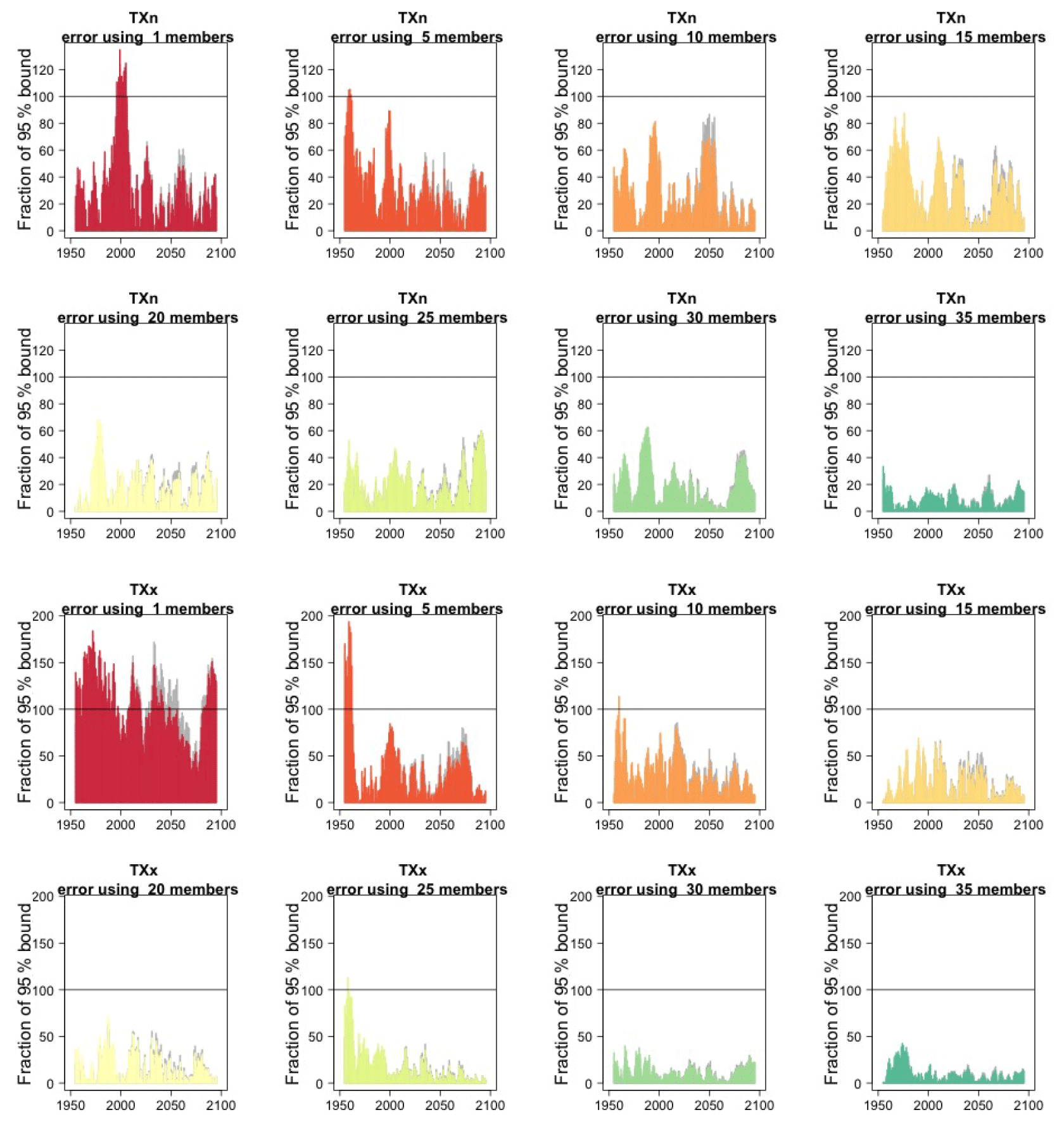
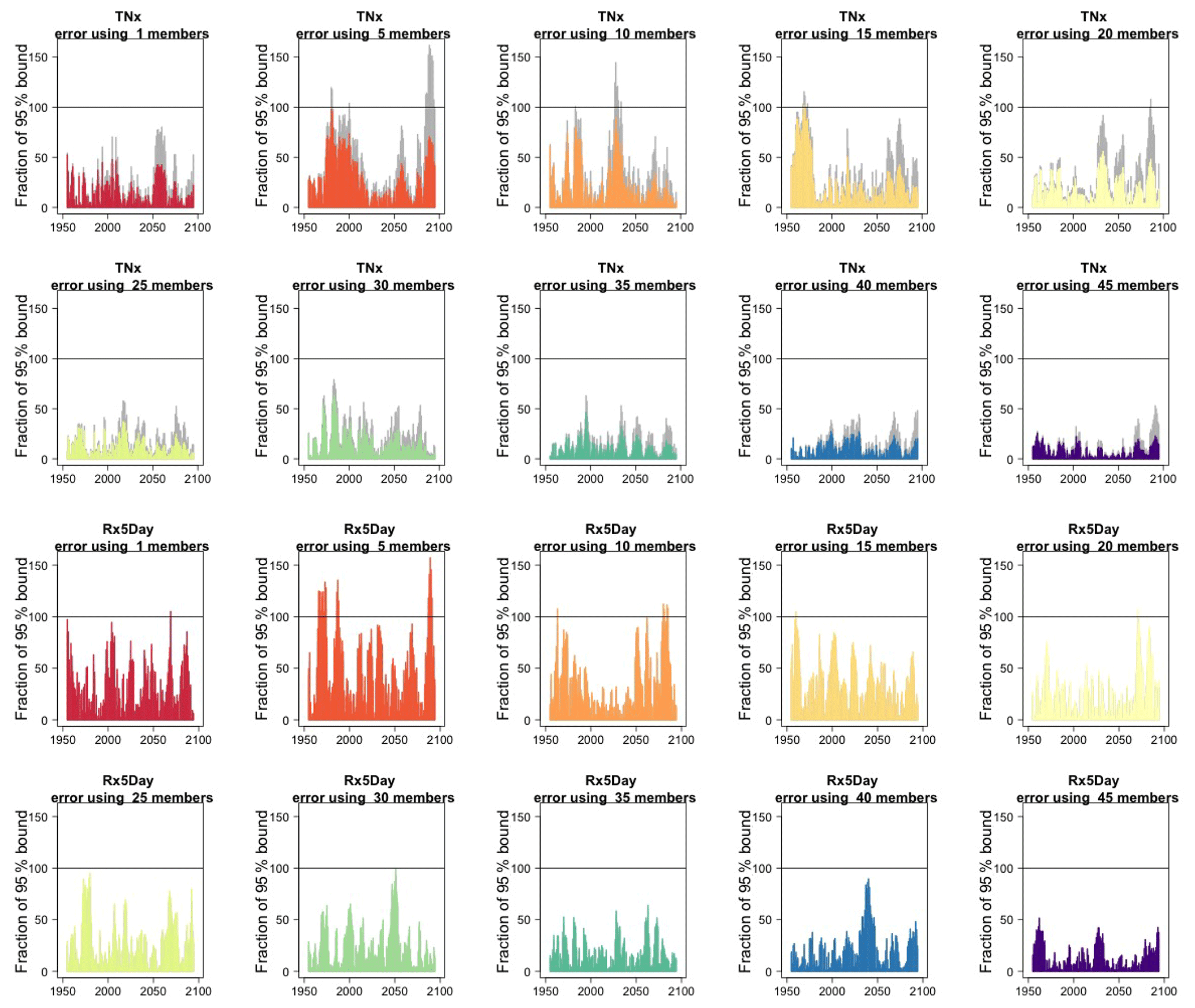
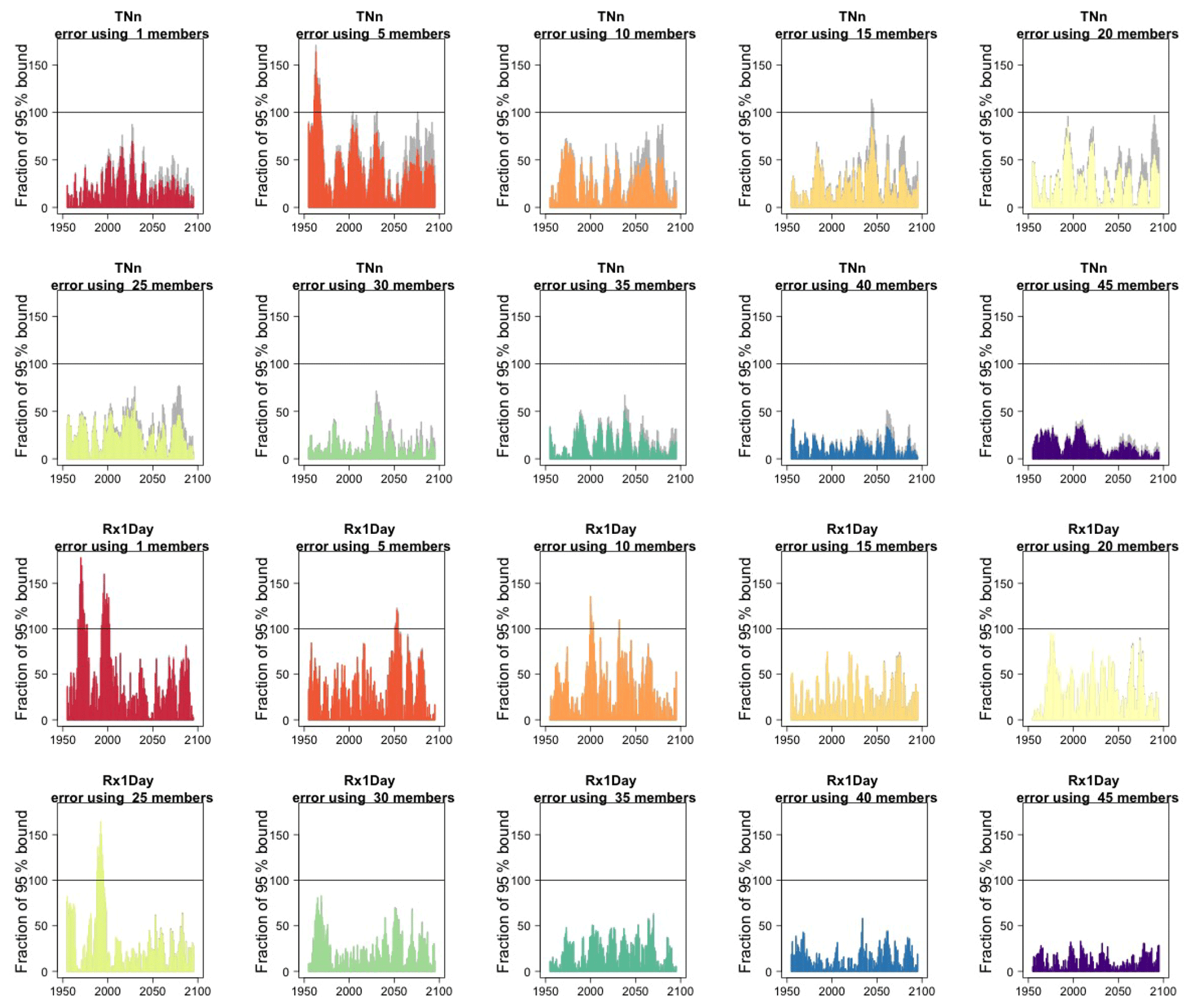
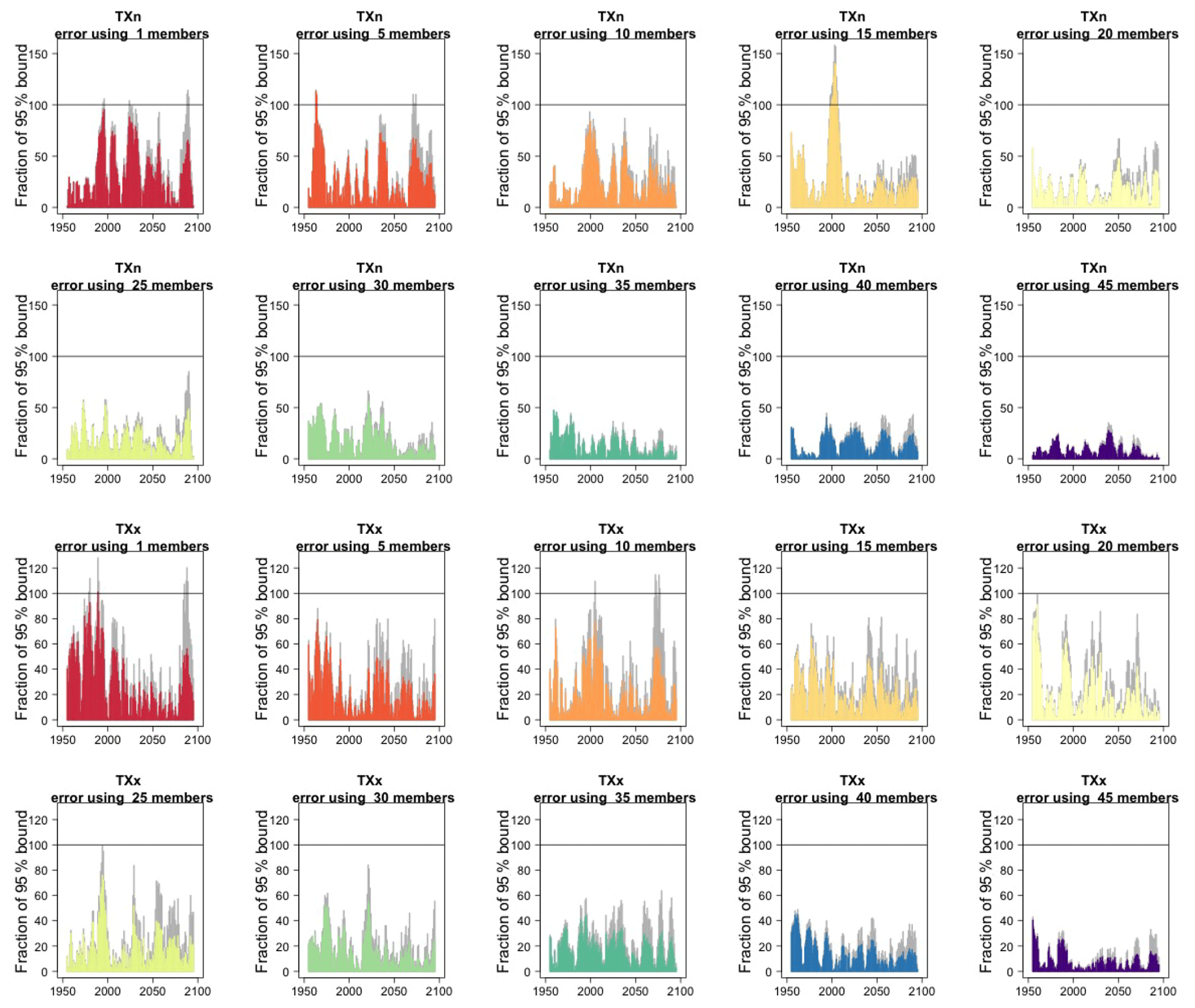
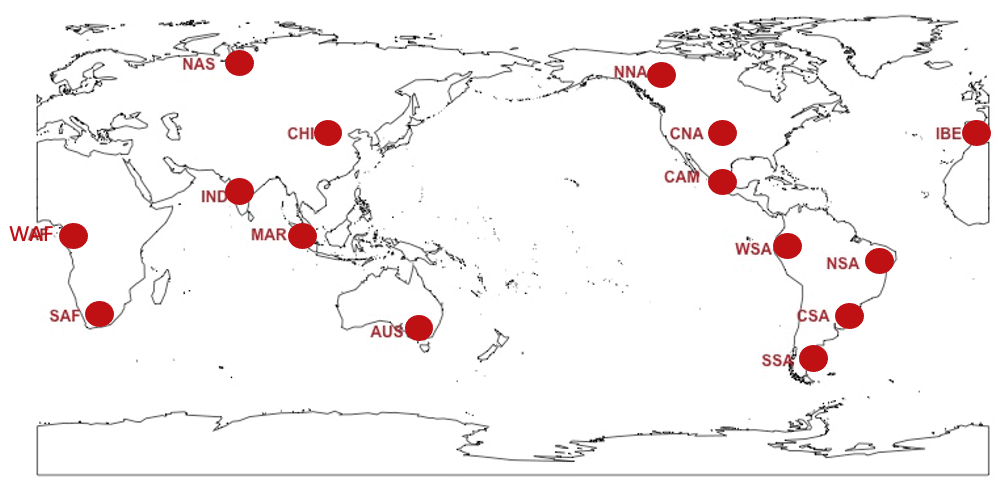
Figure C9The 15 locations at which we fit GEV distributions to the various quantities.
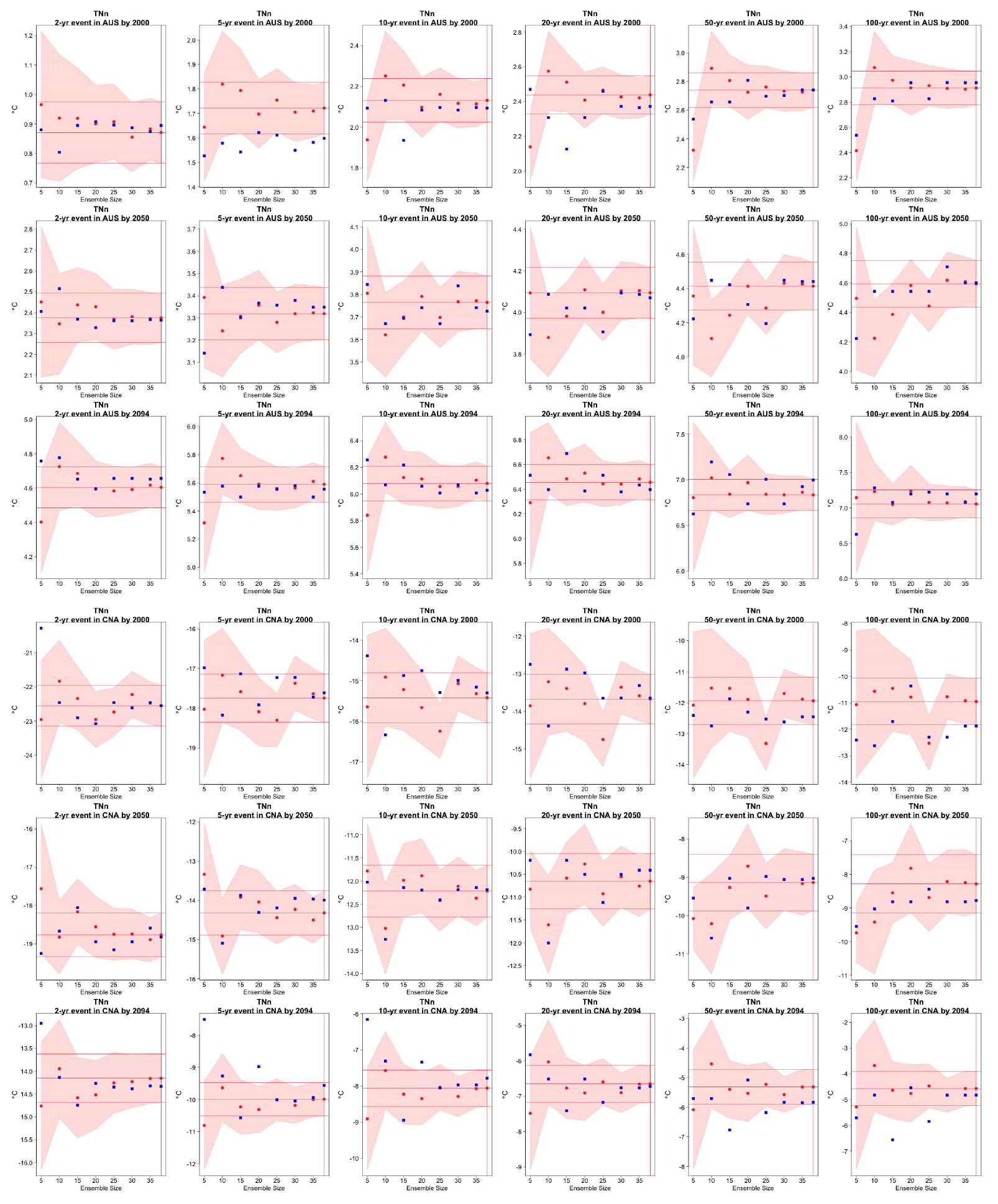
Figure C10Return levels for TNn from the CESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 40), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of TNn on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location in Australia, while the following three rows show results for a location in central North America (see Fig. C9).
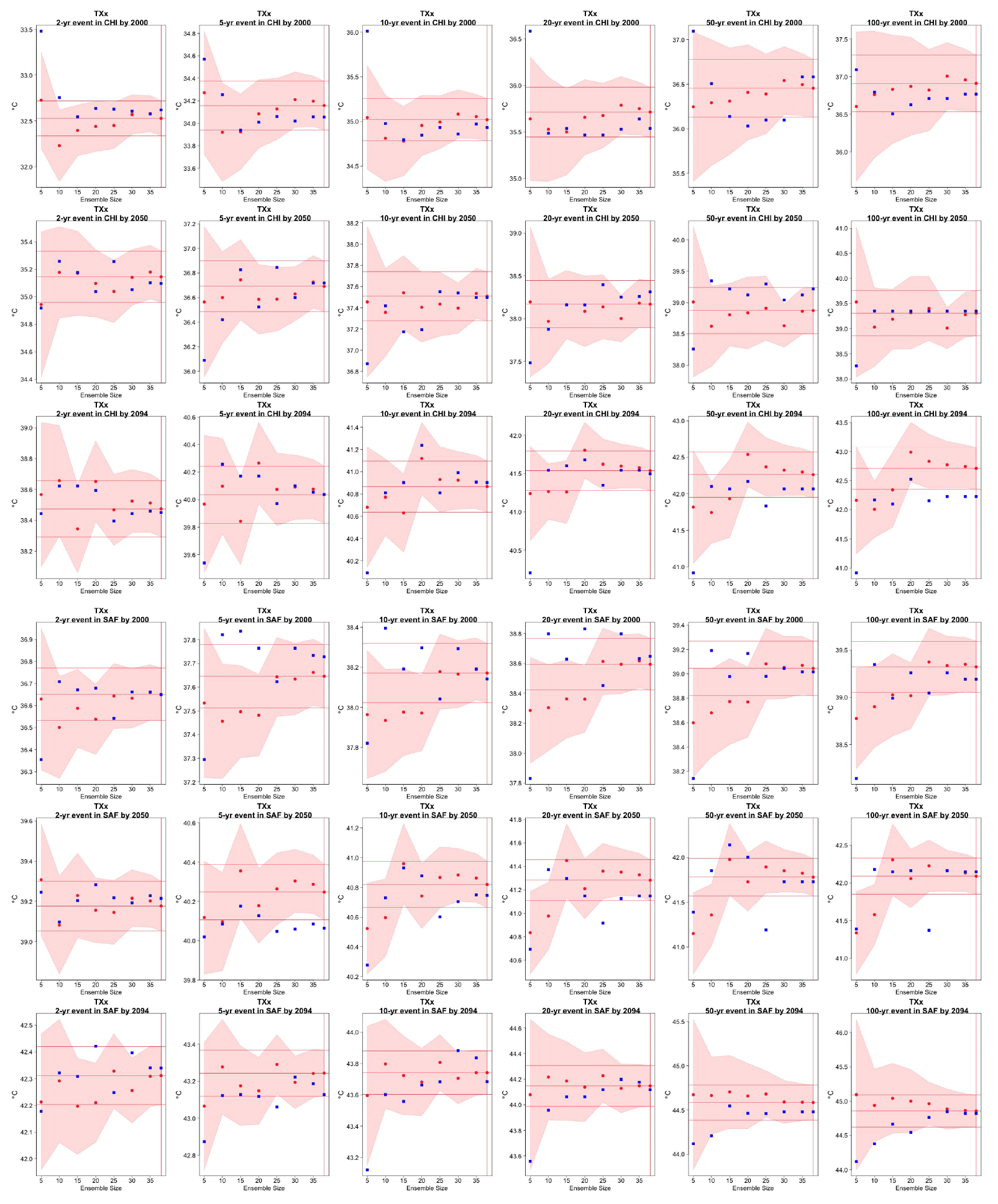
Figure C11Return levels for TXx from the CESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 40), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of TXx on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location in China, while the following three rows show results for a location in southern Africa (see Fig. C9).
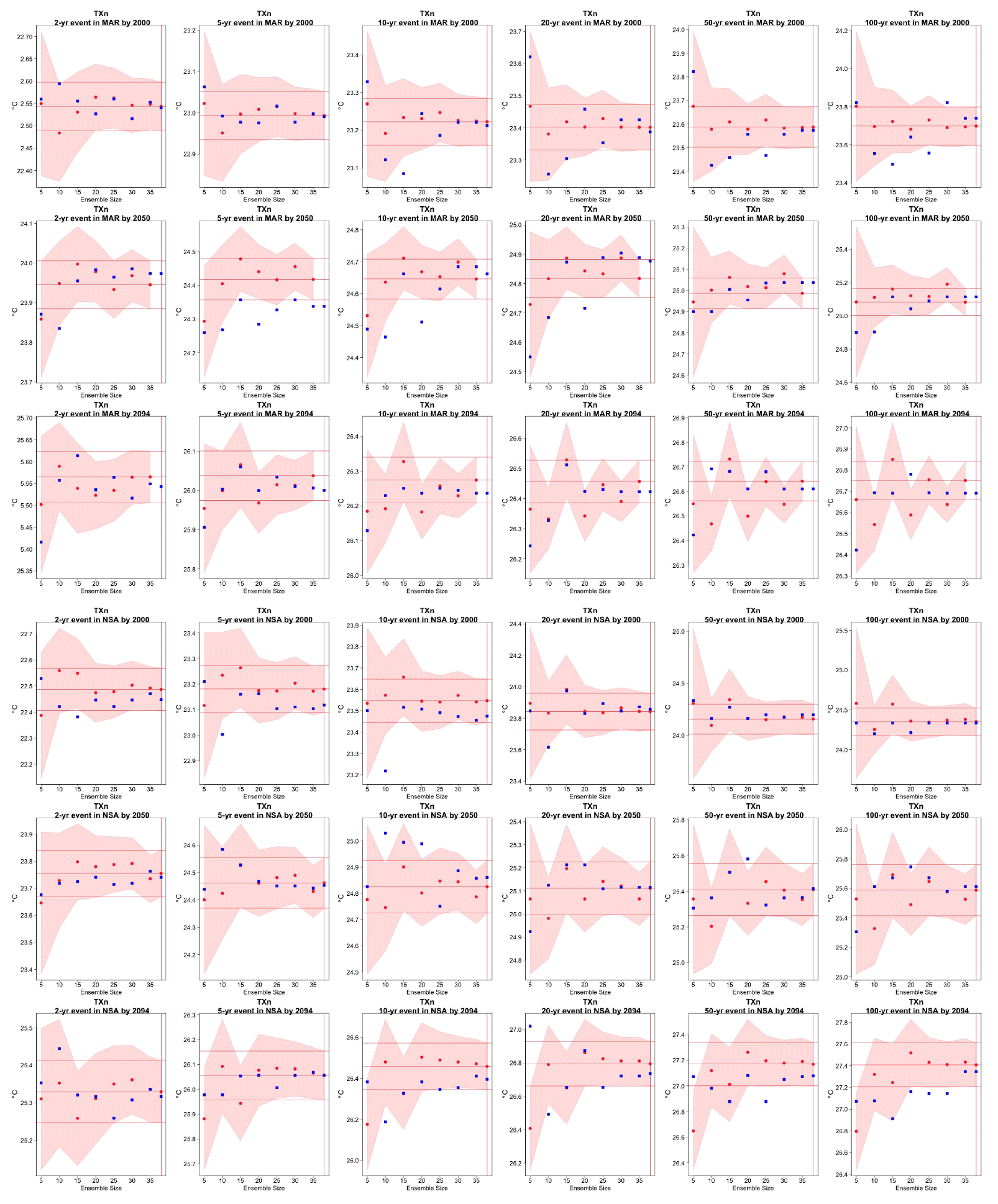
Figure C12Return levels for TXn from the CESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 40), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of TXn on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location on the Maritime Continent, while the following three rows show results for a location in northern South America (see Fig. C9).
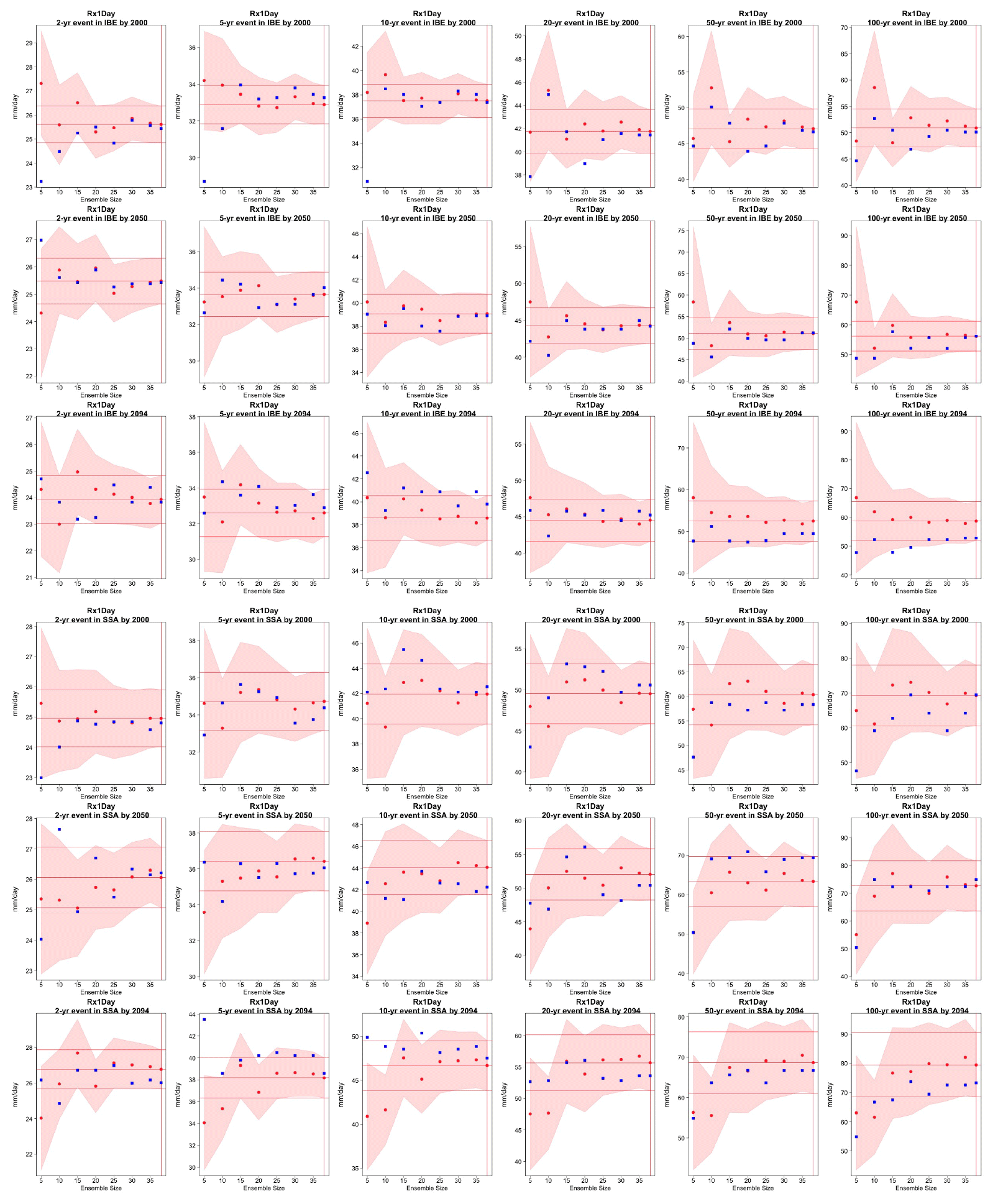
Figure C13Return levels for Rx1Day from the CESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 40), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of Rx1Day on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location on the Iberian Peninsula, while the following three rows show results for a location in southern South America (see Fig. C9).
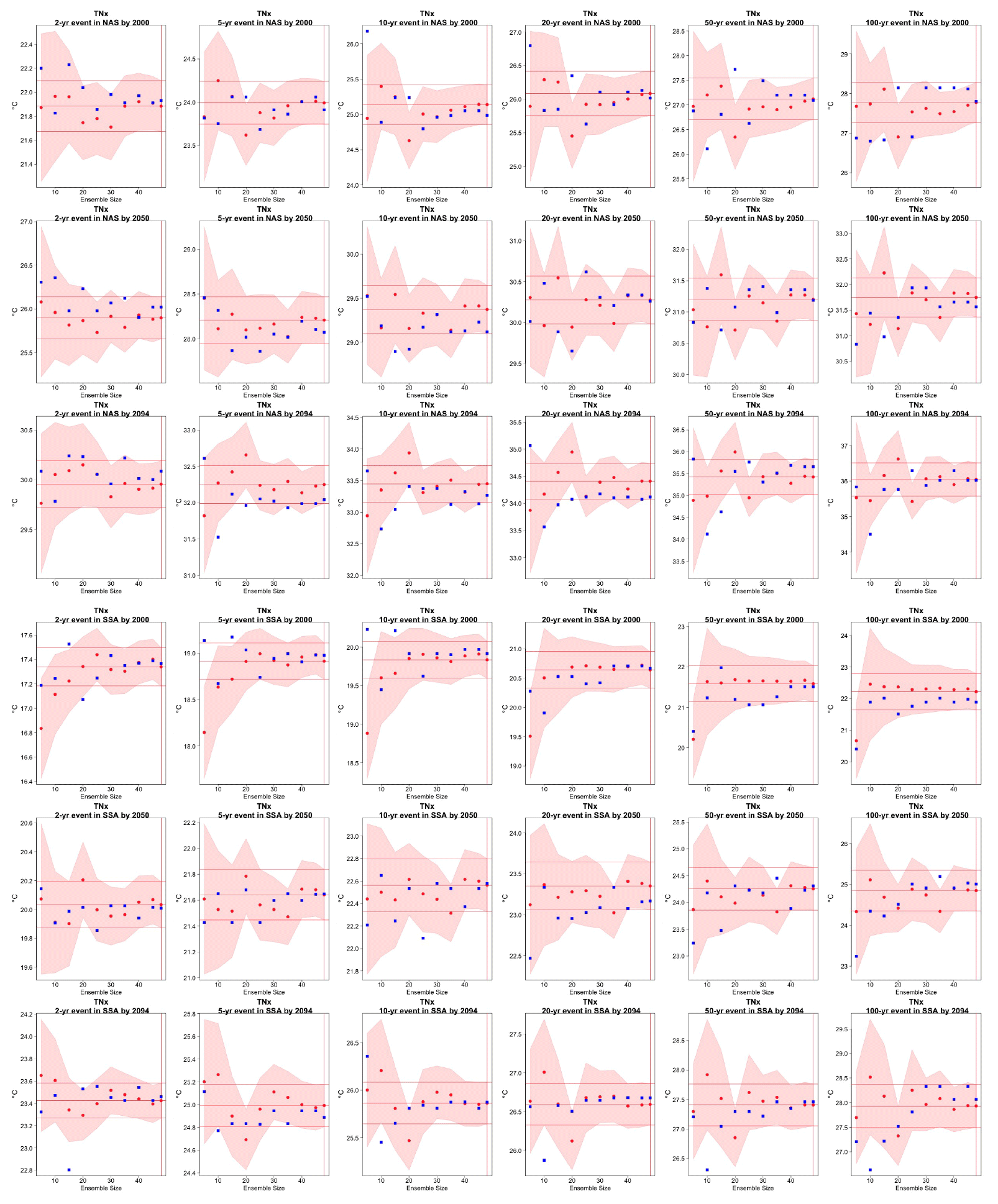
Figure C14Return levels for TNx from the CanESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 50), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of TNx on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location in northern Asia, while the following three rows show results for a location in southern South America (see Fig. C9).
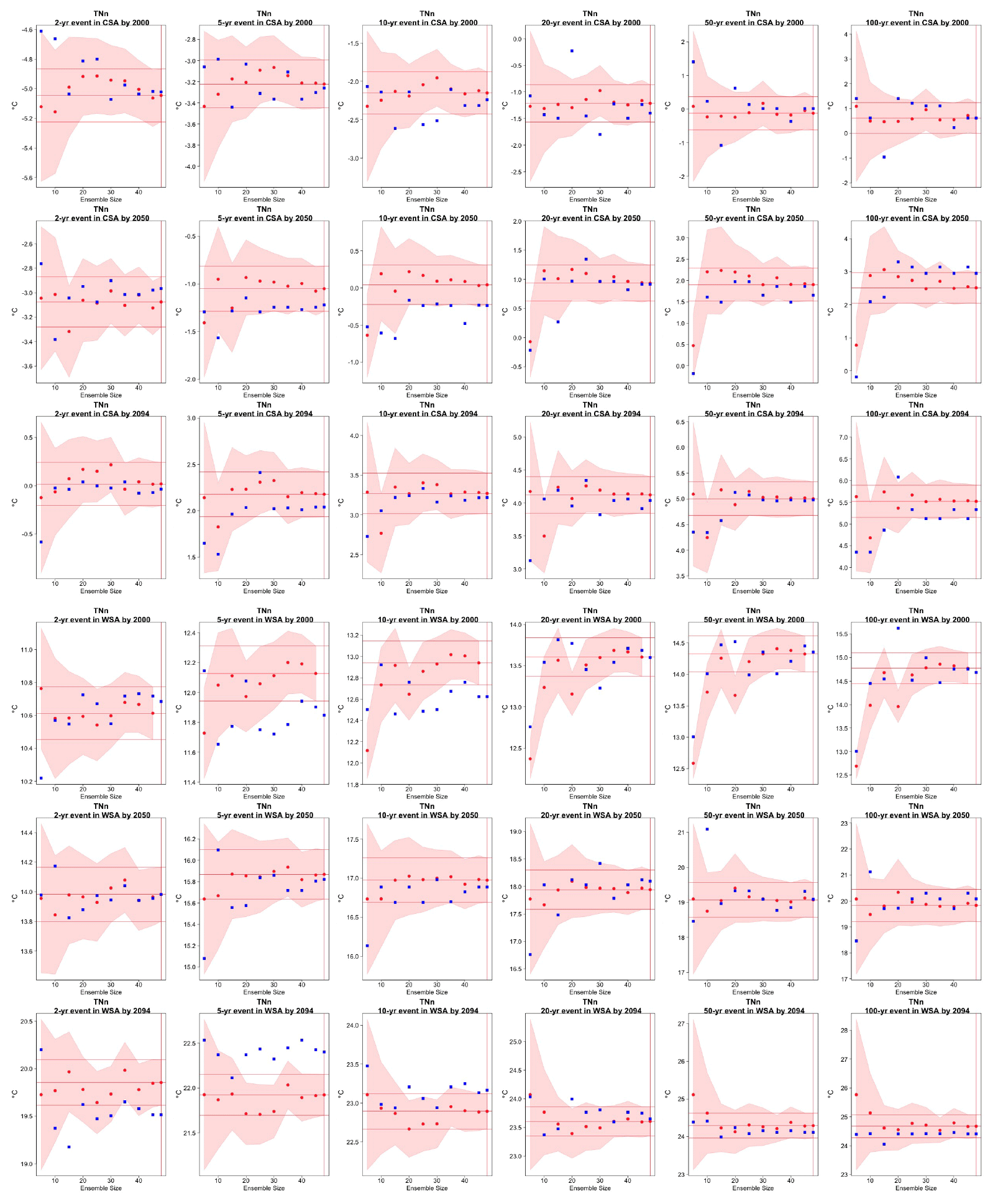
Figure C15Return levels for TNn from the CanESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 50), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of TNn on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location in central South America, while the following three rows show results for a location in western South America (see Fig. C9).
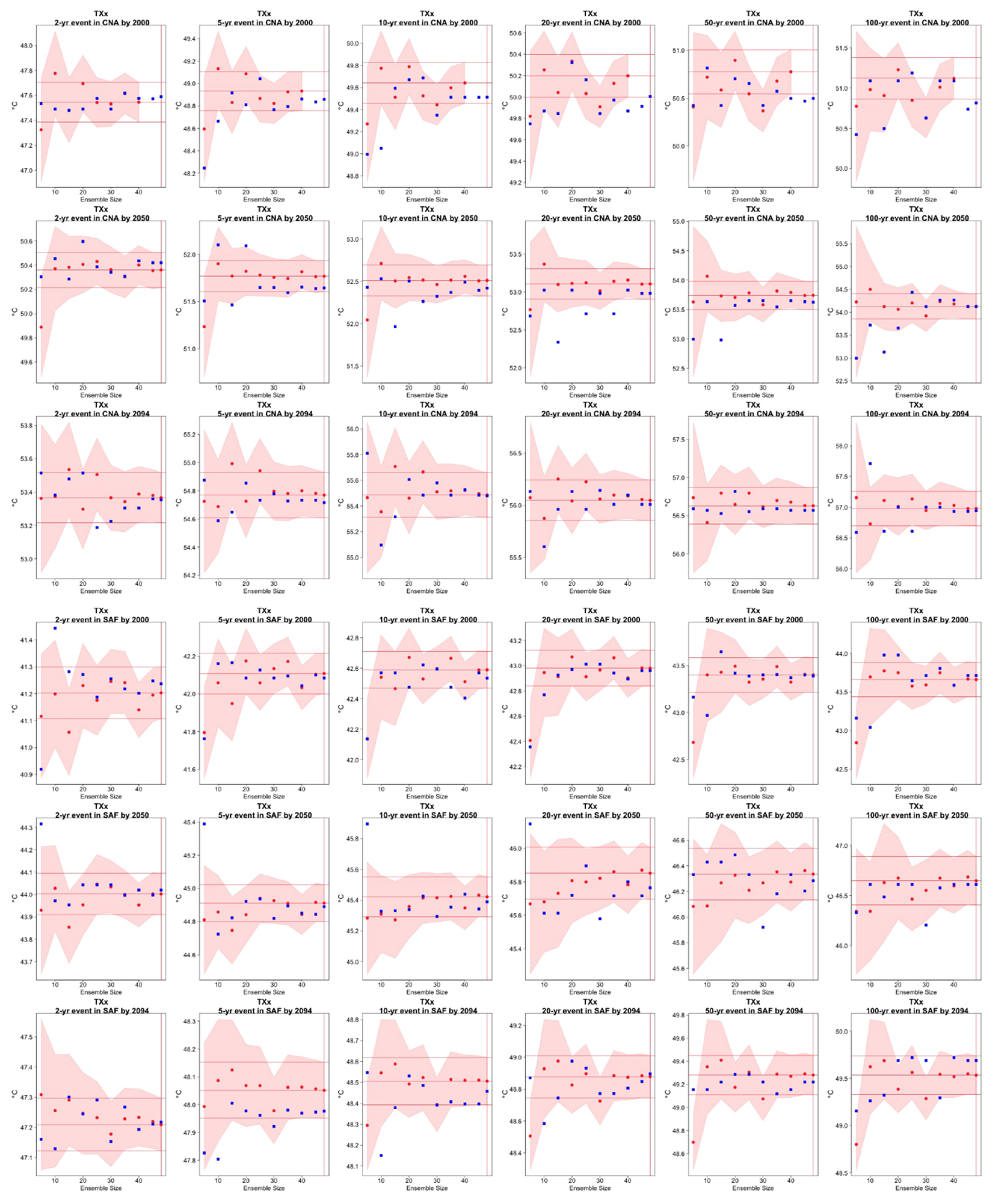
Figure C16Return levels for TXx from the CanESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 50), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of TXx on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location in central North America, while the following three rows show results for a location in southern Africa (see Fig. C9).
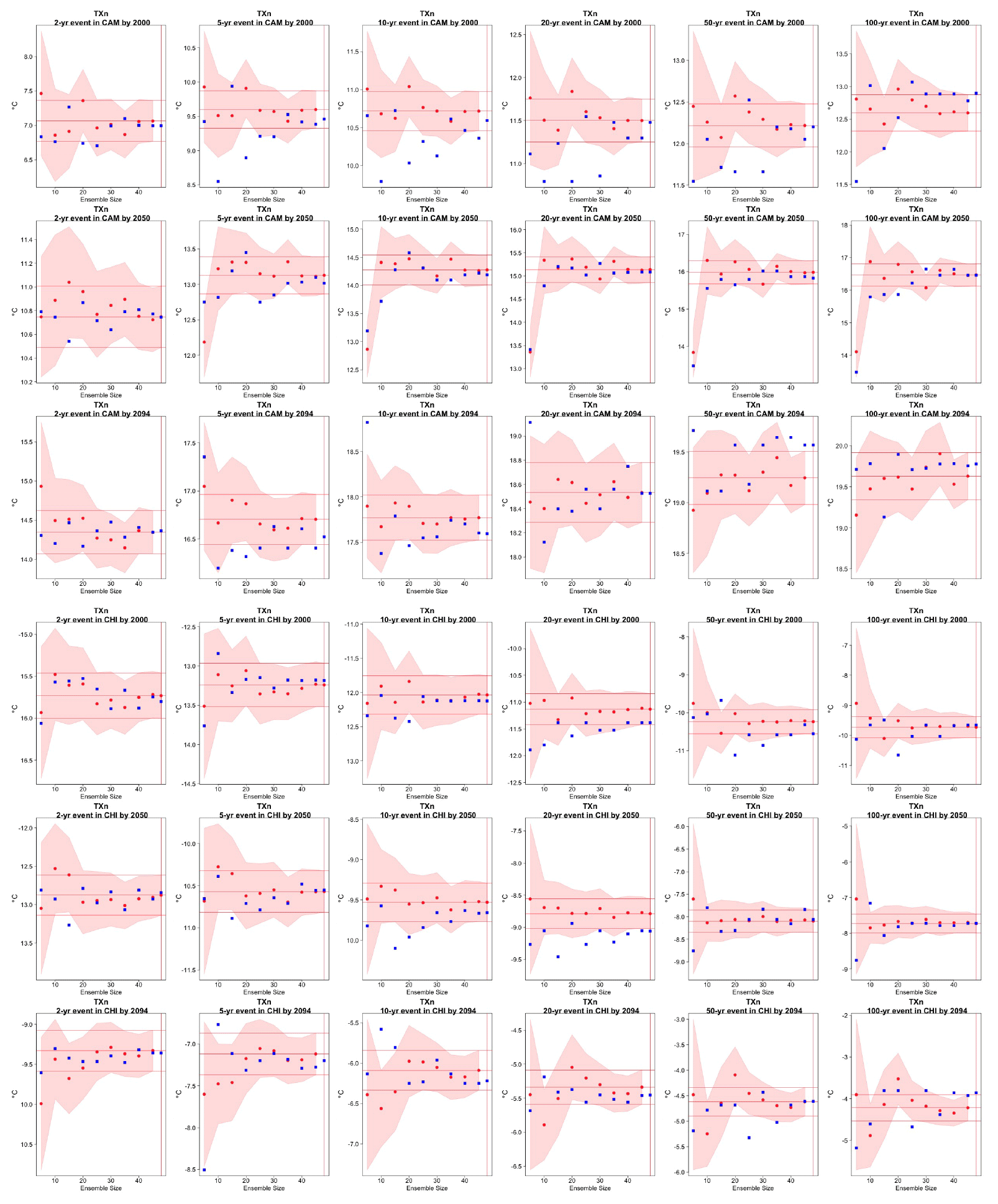
Figure C17Return levels for TXn from the CanESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 50), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of TXn on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location in Central America, while the following three rows show results for a location in China (see Fig. C9).
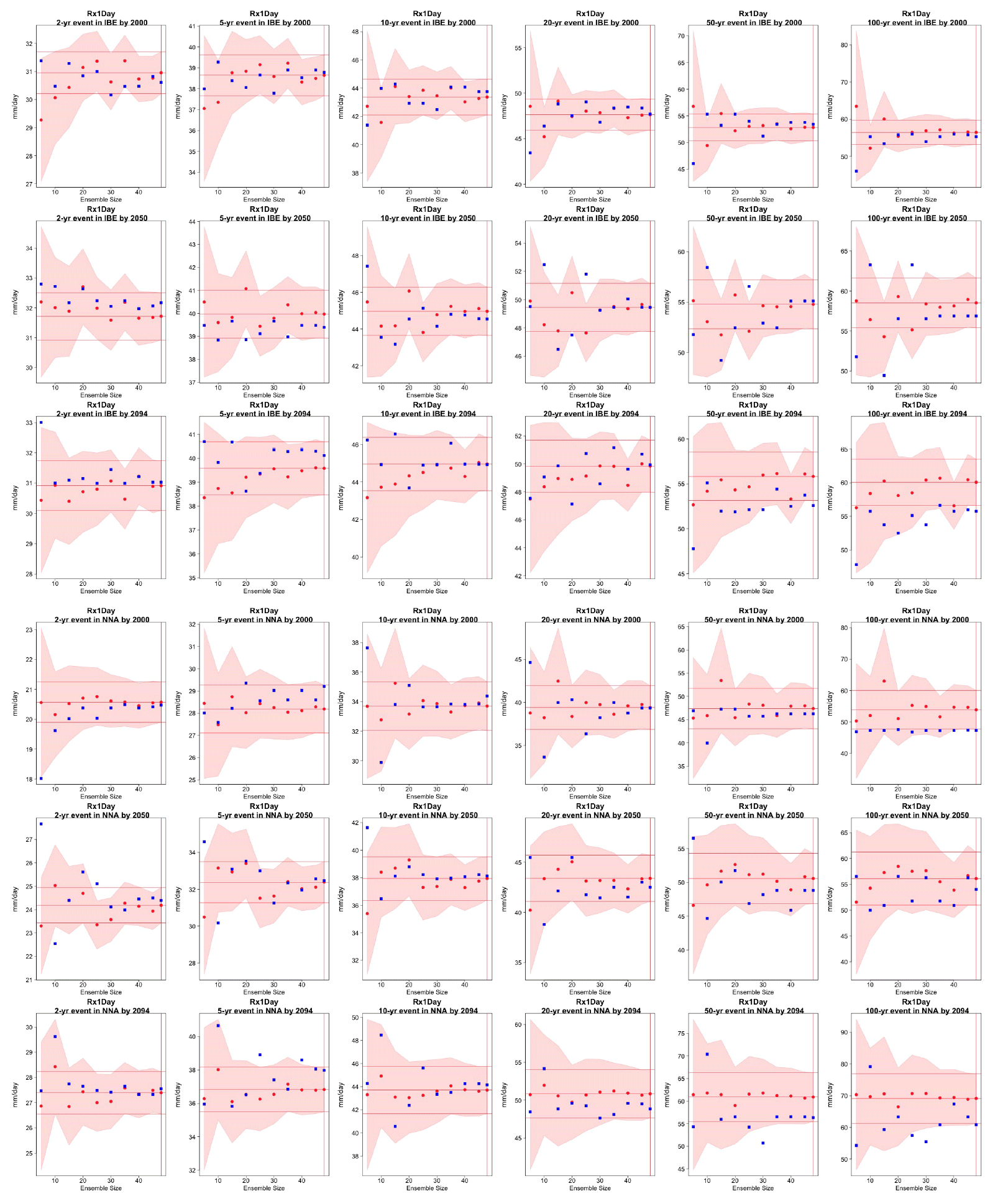
Figure C18Return levels for Rx1Day from the CanESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 50), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of Rx1Day on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location on the Iberian Peninsula, while the following three rows show results for a location in northern North America (see Fig. C9).
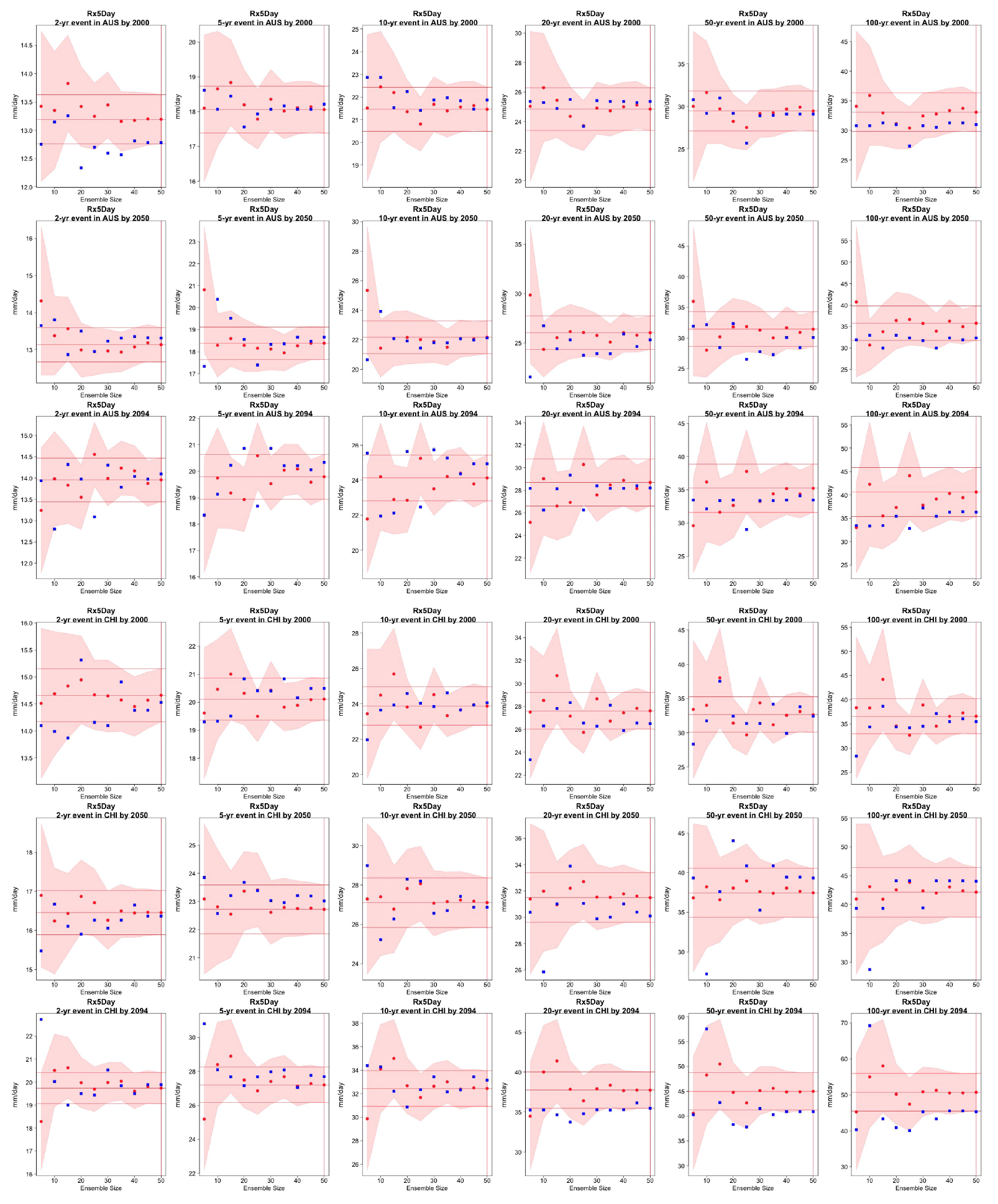
Figure C19Return levels for Rx5Day from the CanESM ensemble at (row-wise) 2000, 2050 and 2100 for (column-wise) 2-, 5-, 10-, 20-, 50- and 100-year return periods, based on estimating a GEV by using 11-year windows of data around each date. In each plot, for increasing ensemble sizes along the x axis (from 5 to the full ensemble, 50), the red dots indicate the central estimate, and the pink envelope represents the 95 % confidence interval. The estimates based on the full ensemble, which we consider the truth, are also drawn across the plot for reference as horizontal lines. The blue dots in each plot show the same quantities estimated by counting, i.e., computing the empirical cumulative distribution function of Rx5Day on the basis of the same sample used for the estimation of the corresponding GEV parameters. The first three rows show results for a location in Australia, while the following three rows show results for a location in China (see Fig. C9).
C2 Variability
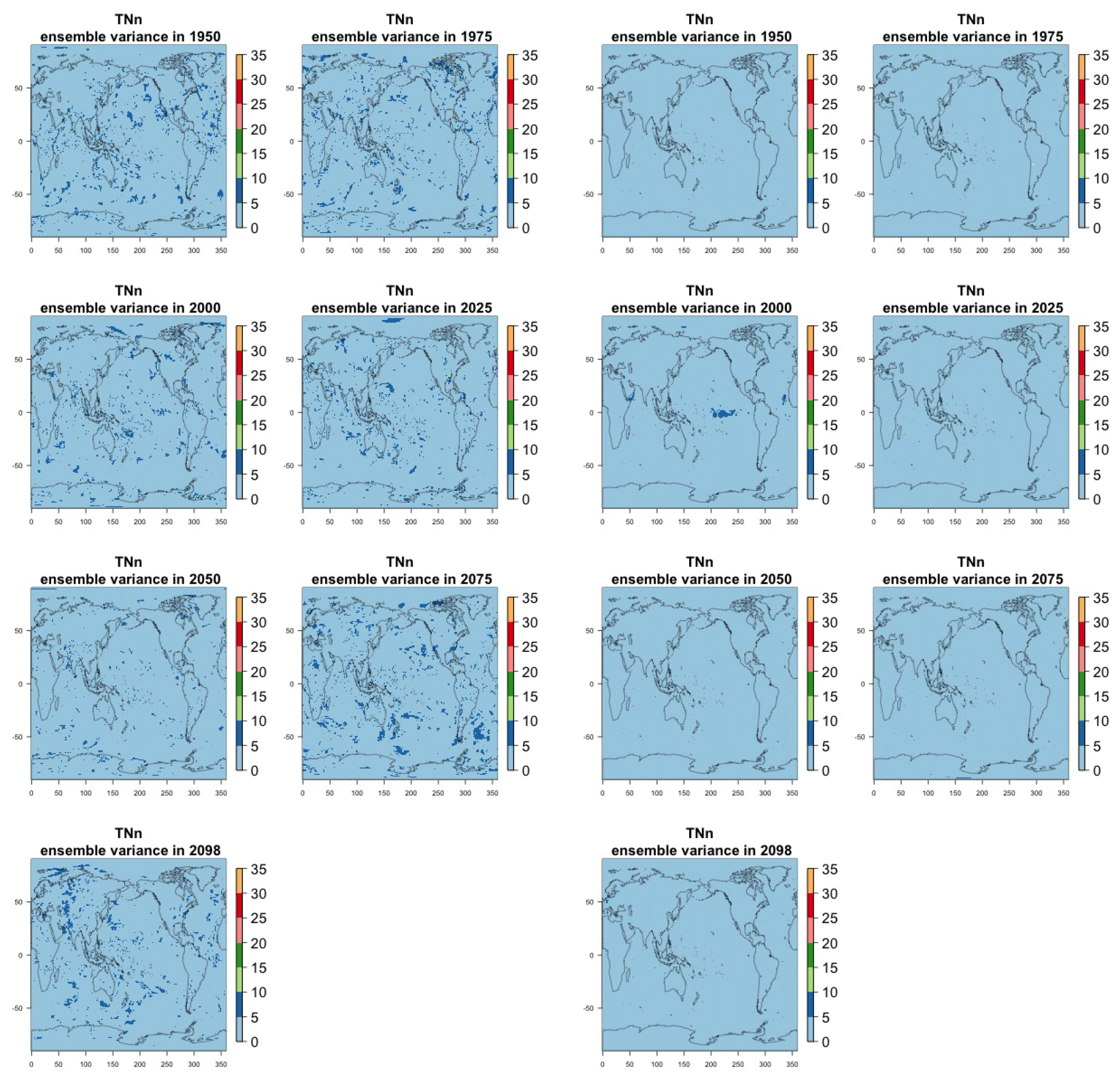
Figure C20Estimating the ensemble variance for TNn in the CESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 40-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
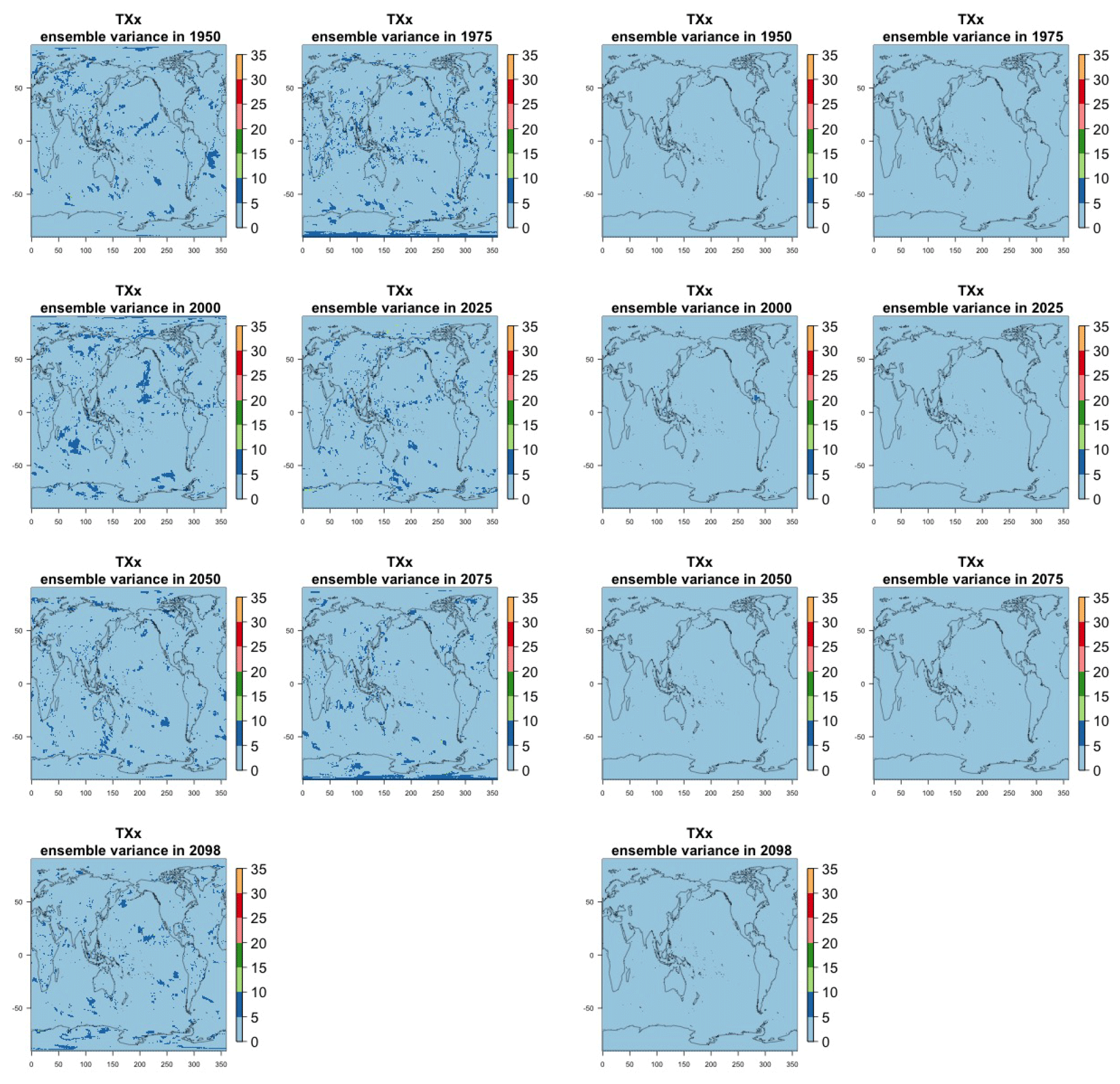
Figure C21Estimating the ensemble variance for TXx in the CESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 40-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
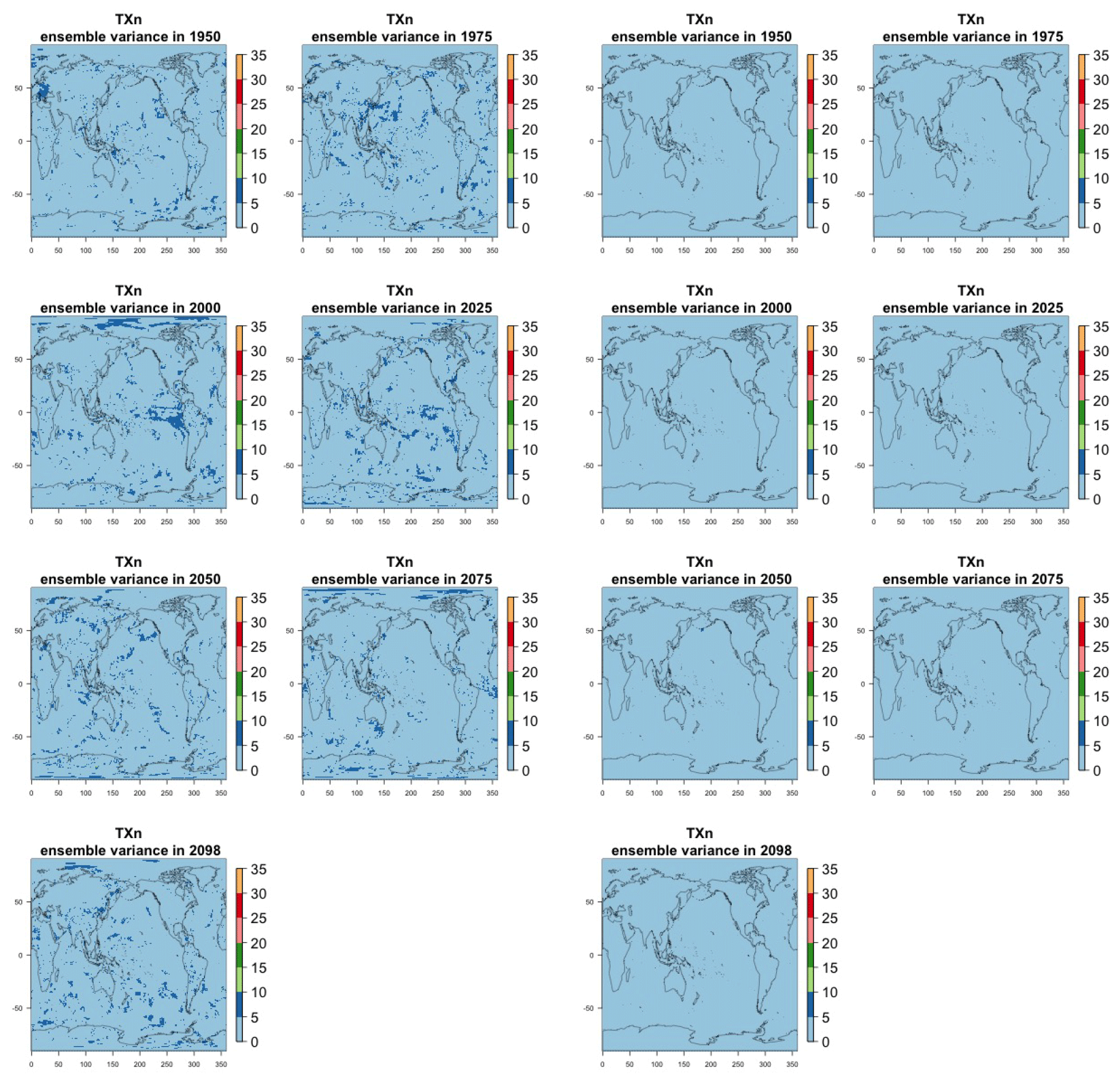
Figure C22Estimating the ensemble variance for TXn in the CESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 40-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
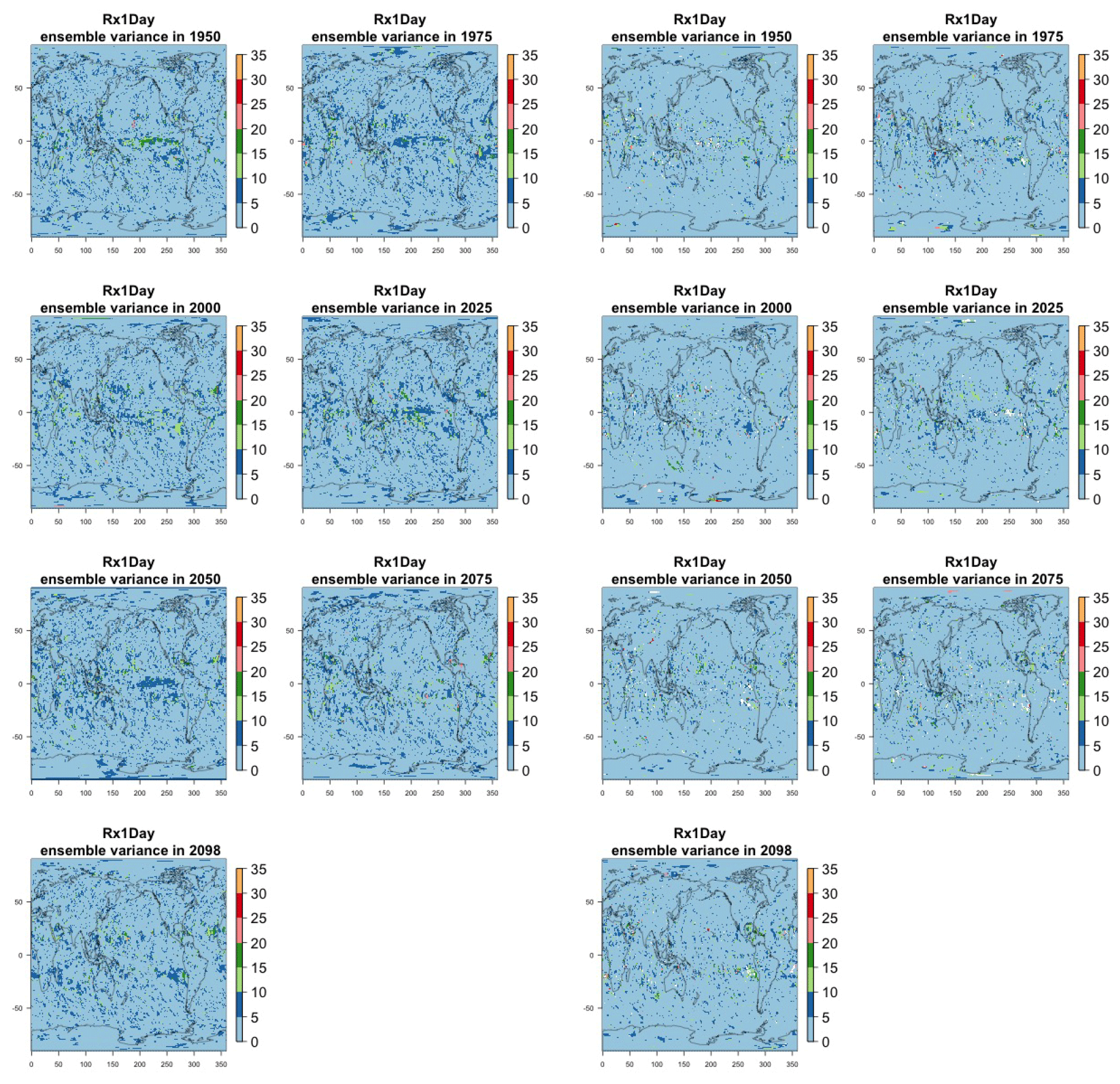
Figure C23Estimating the ensemble variance for Rx1Day in the CESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 40-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
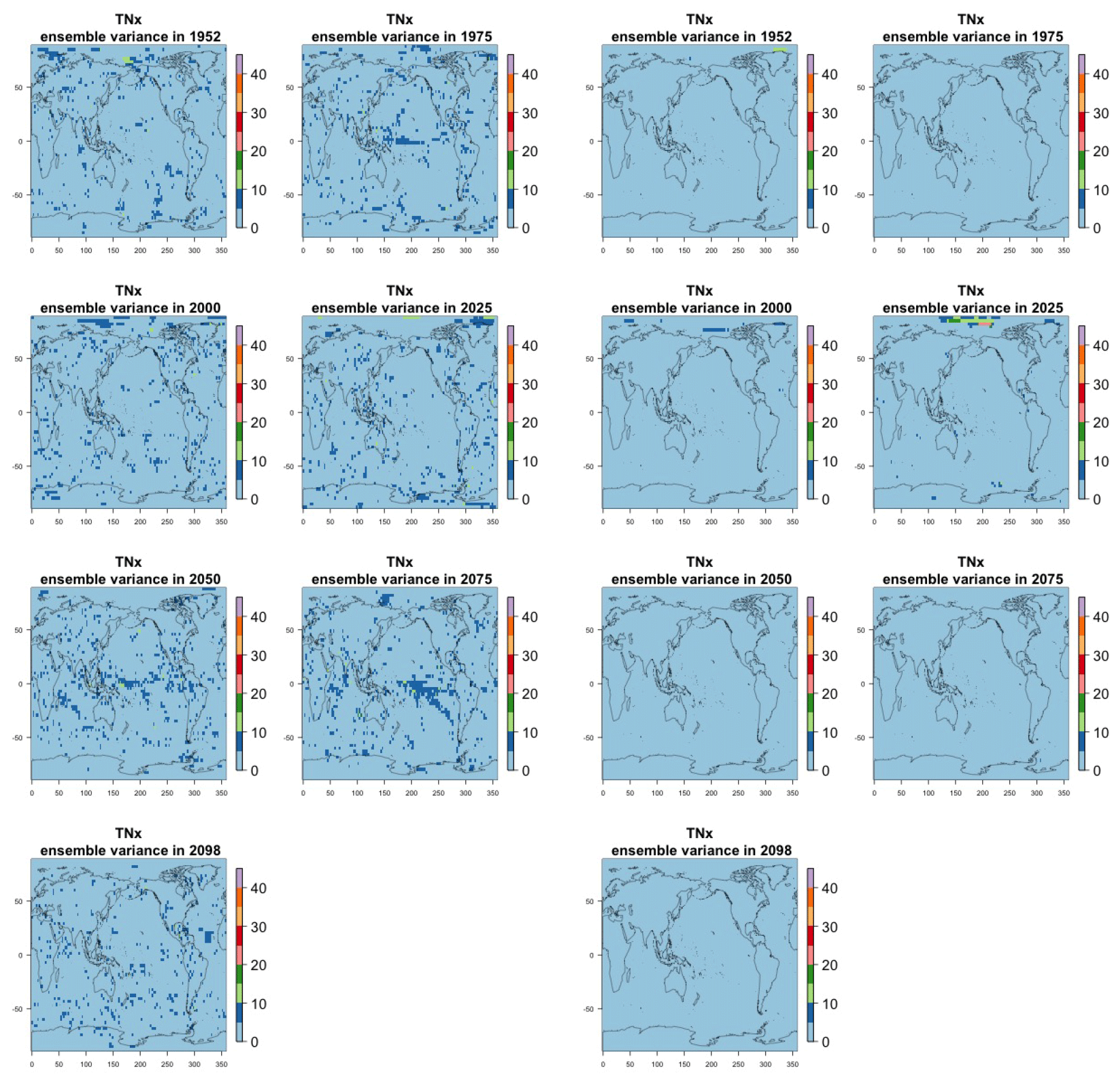
Figure C24Estimating the ensemble variance for TNx in the CanESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 50-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
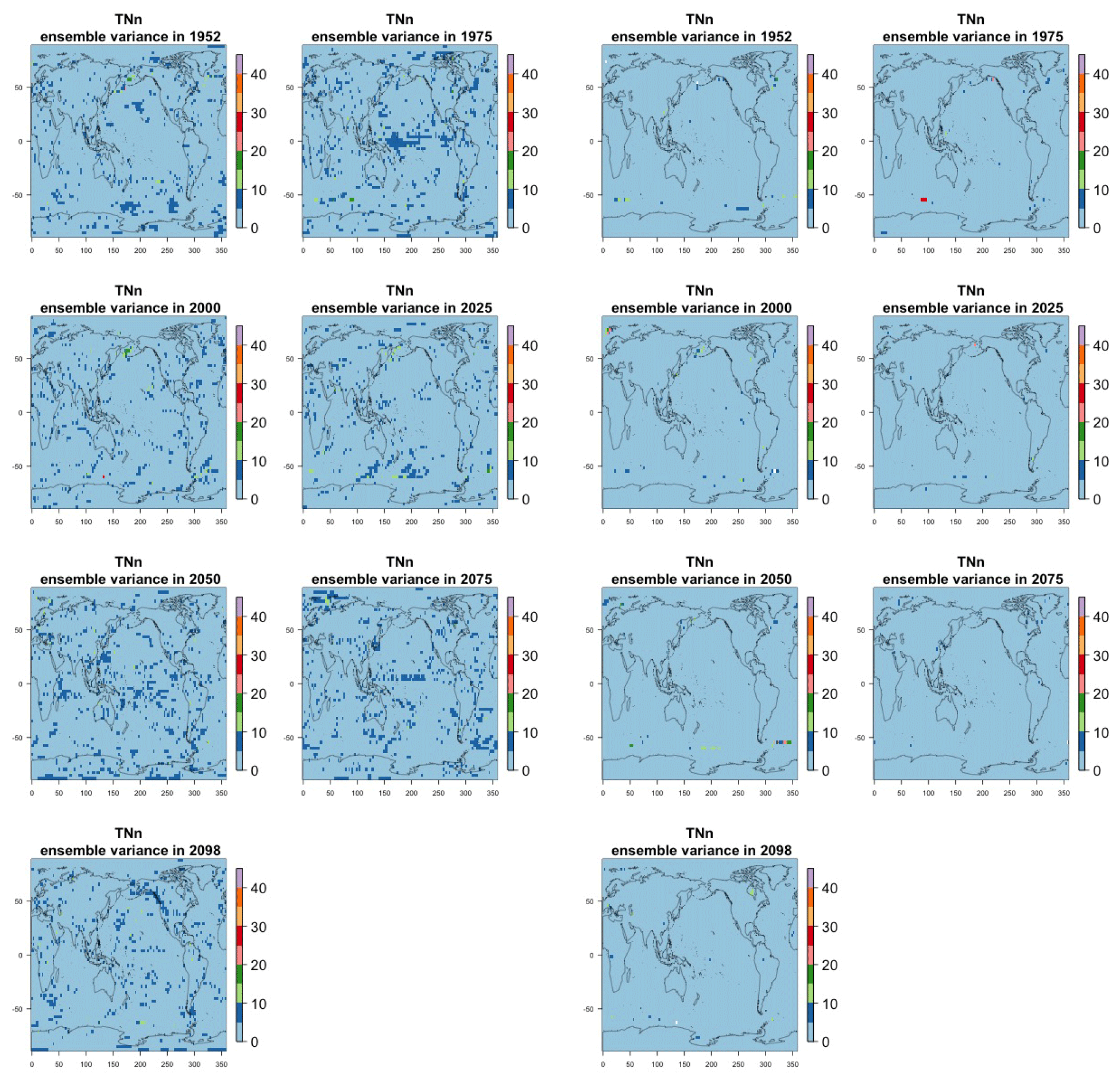
Figure C25Estimating the ensemble variance for TNn in the CanESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 50-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
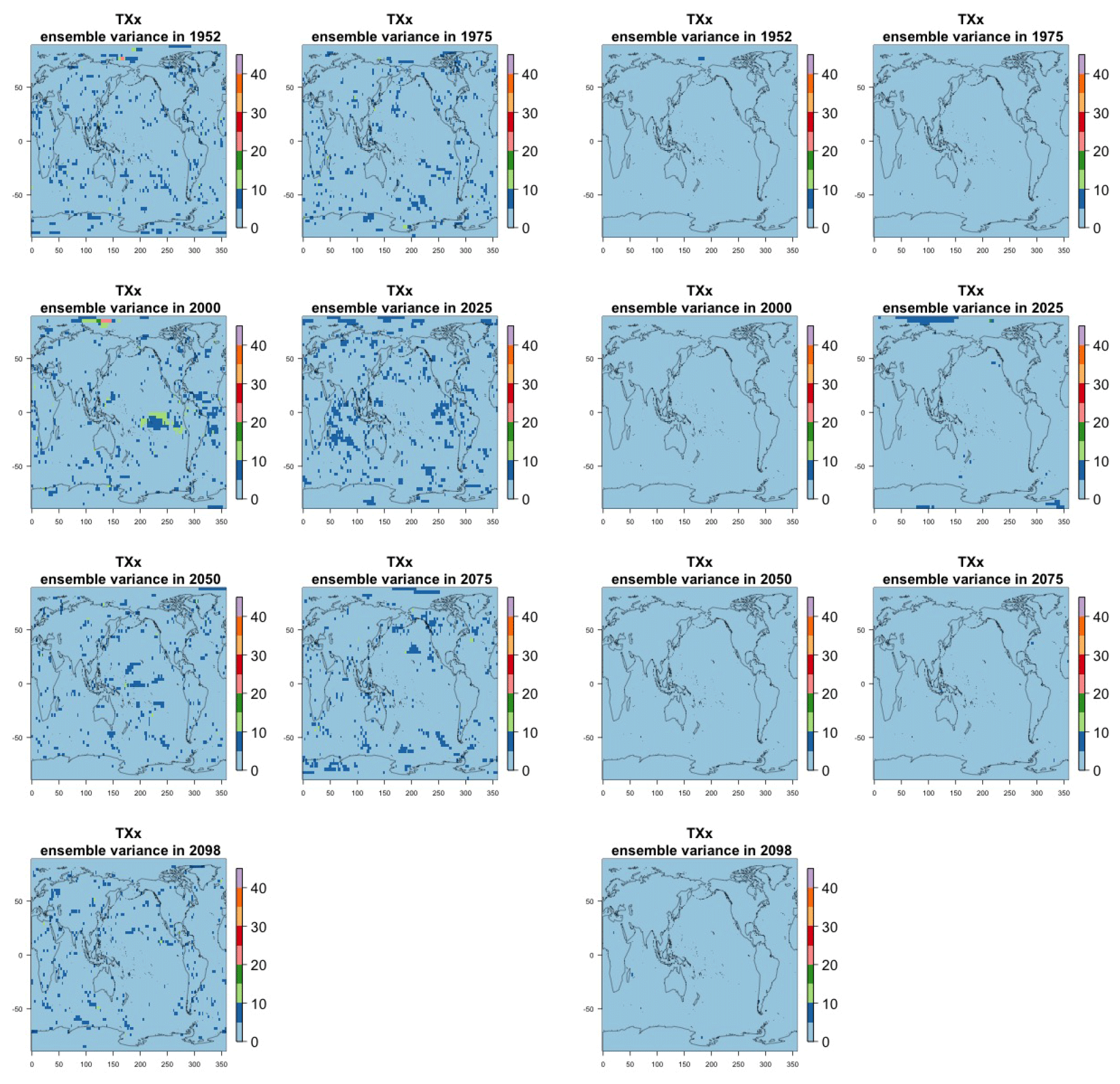
Figure C26Estimating the ensemble variance for TXx in the CanESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 50-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
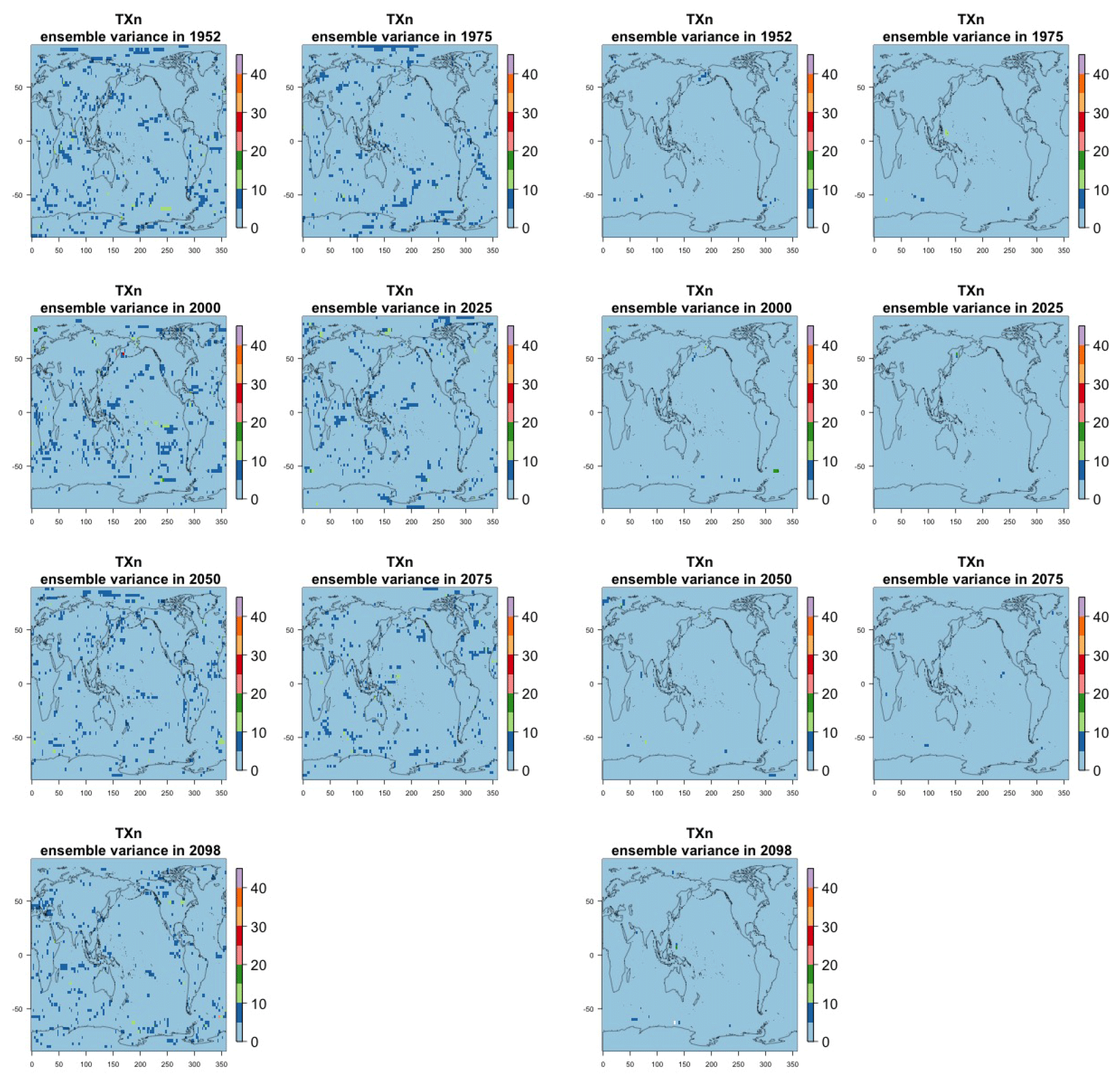
Figure C27Estimating the ensemble variance for TXn in the CanESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 50-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
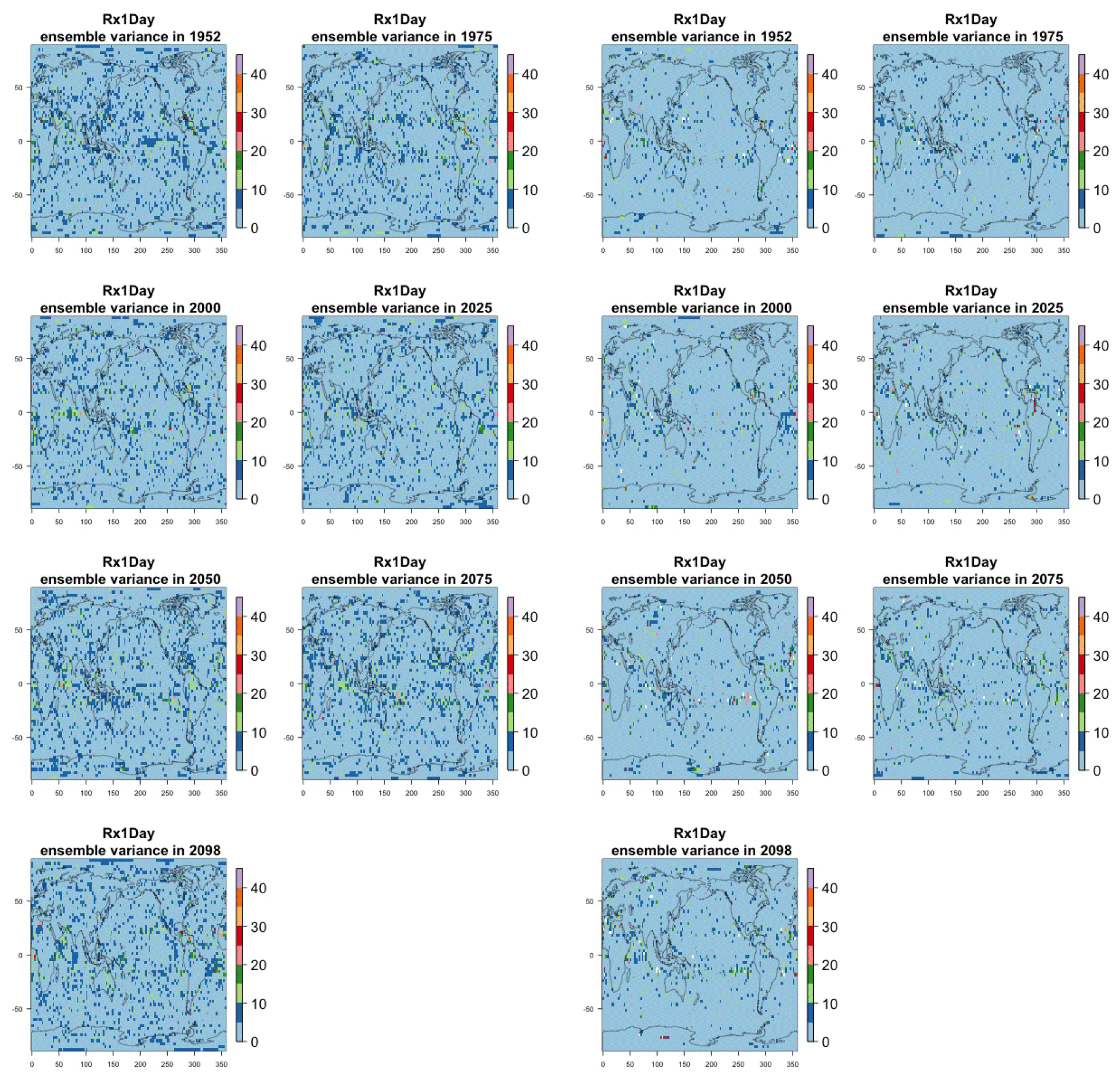
Figure C28Estimating the ensemble variance for Rx1Day in the CanESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 50-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
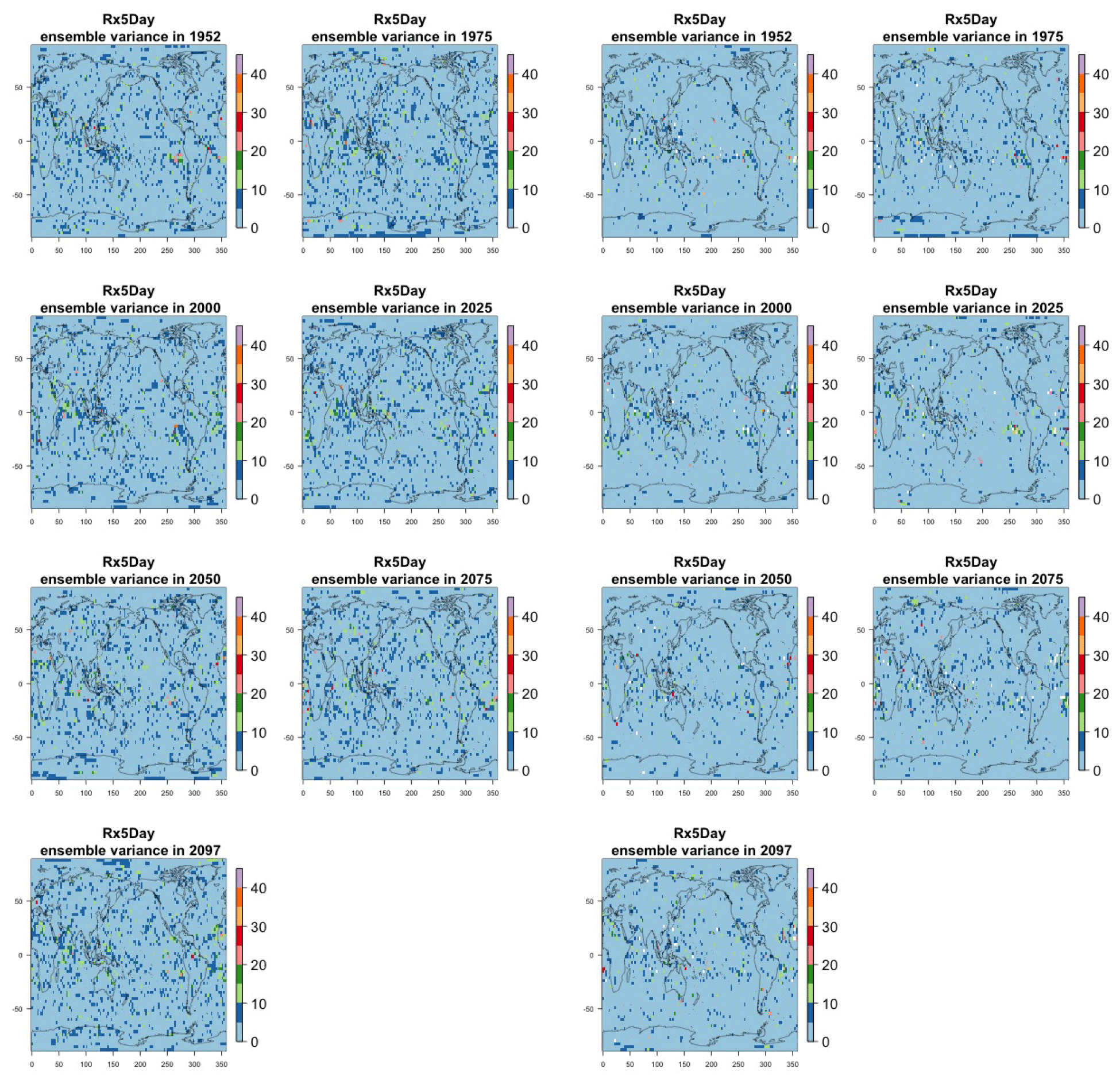
Figure C29Estimating the ensemble variance for Rx5Day in the CanESM ensemble: each plot corresponds to a year along the simulation length (1950, 1975, 2000, 2025, 2050, 2075, 2100). The color indicates the number of ensemble members needed to estimate a variance at that location that is statistically indistinguishable from that computed on the basis of the full 50-member ensemble. The results of the first two columns use only the specific year for each ensemble member. The results of the third and fourth columns enrich the samples by using 5 years around the specific date.
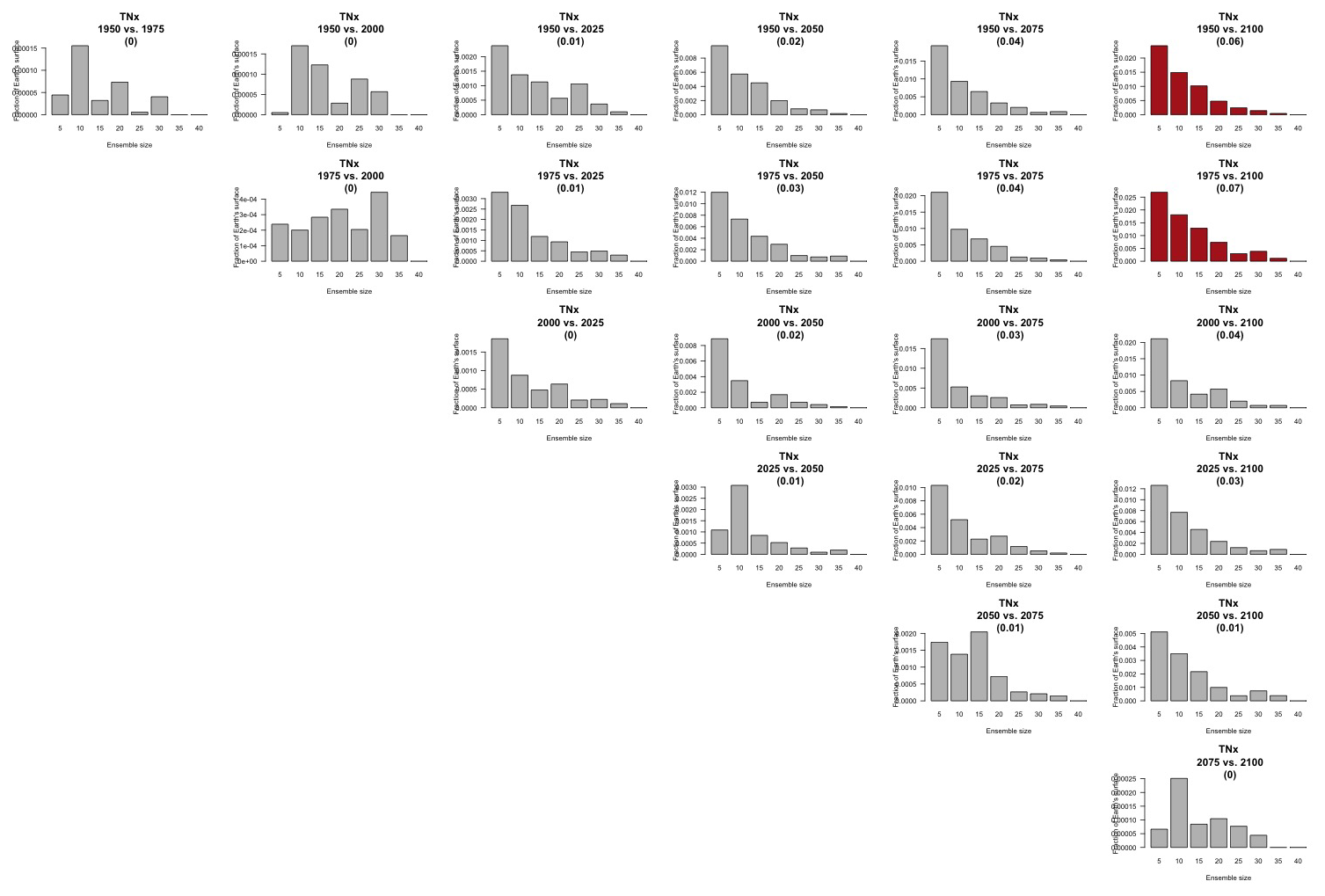
Figure C30Histograms of required ensemble sizes at grid boxes where significant change in variability is detected: each plot corresponds to a map in Fig. 9 and shows a histogram of the values at each grid box that is colored in that map. Histograms are weighted according to the cosine of the latitude of the grid box, so that the values along the y axes can be interpreted as fractions of the Earth's surface. In red are histograms that represent a total fraction of the Earth's surface larger than 5 %.
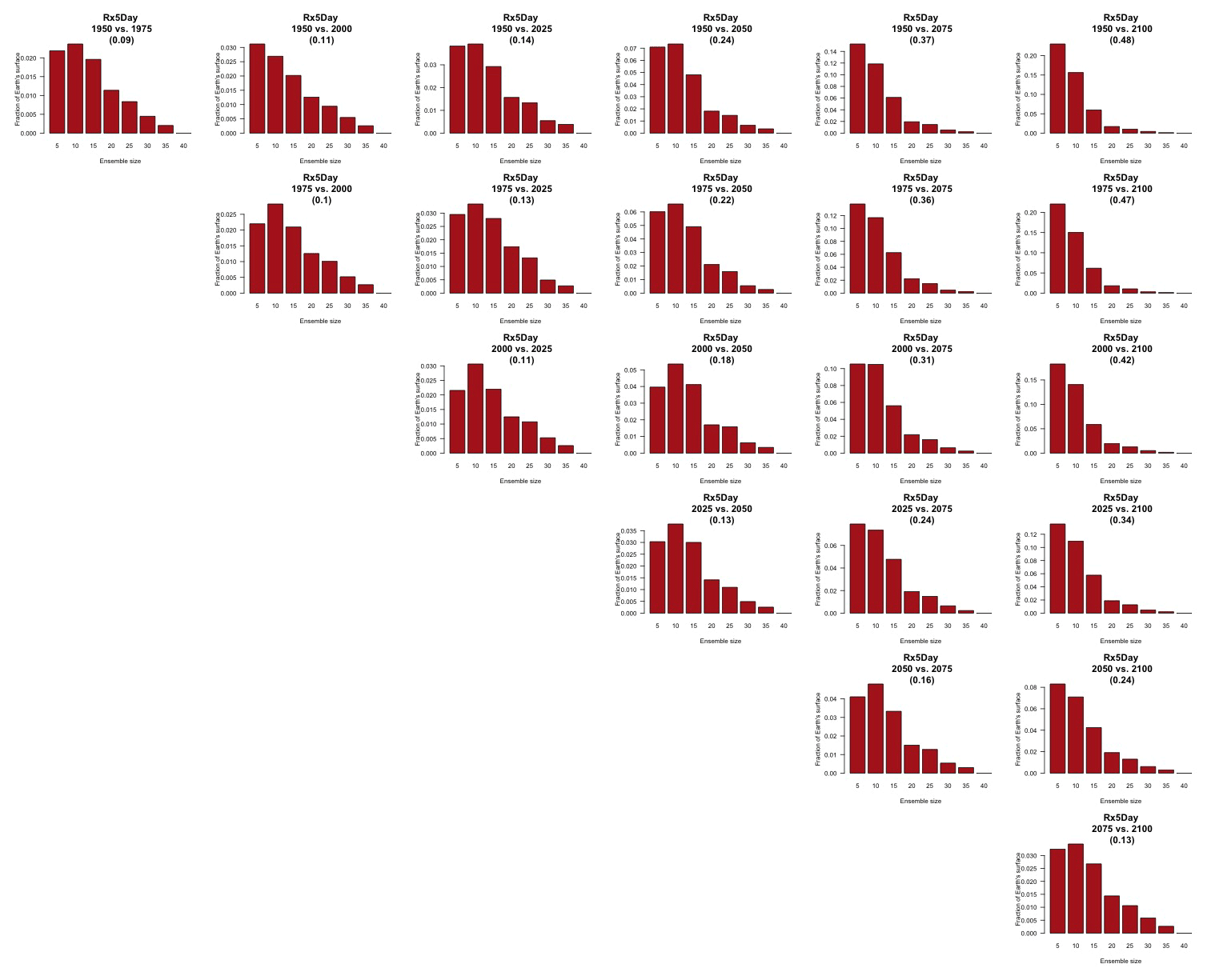
Figure C31Histograms of required ensemble sizes at grid boxes where significant change in variability is detected: each plot corresponds to a map in Fig. 10 and shows a histogram of the values at each grid box that is colored in that map. Histograms are weighted according to the cosine of the latitude of the grid box, so that the values along the y axes can be interpreted as fractions of the Earth's surface. In red are histograms that represent a total fraction of the Earth's surface larger than 5 %.
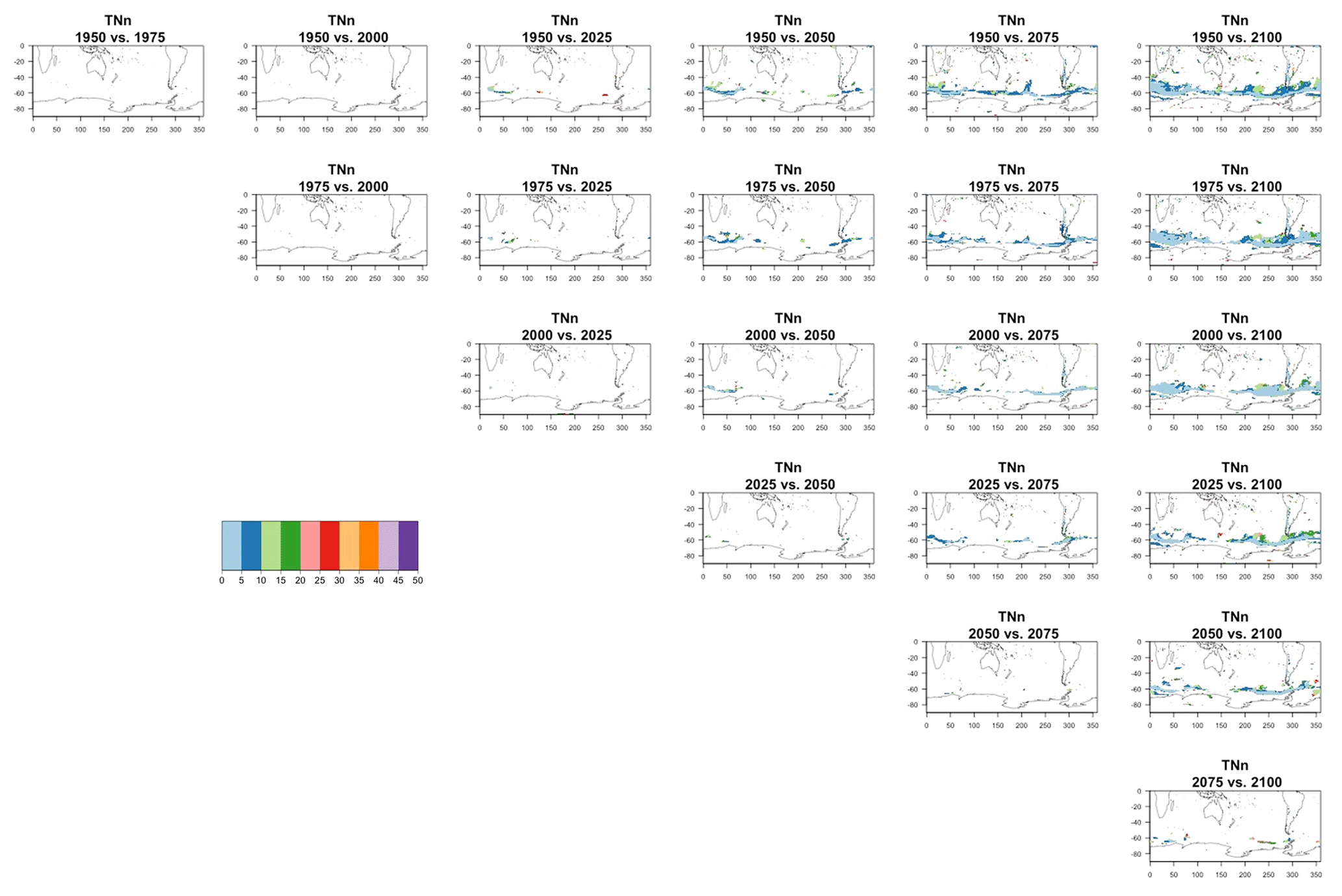
Figure C32Estimating changes in ensemble variance for TNn in the CESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 40-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
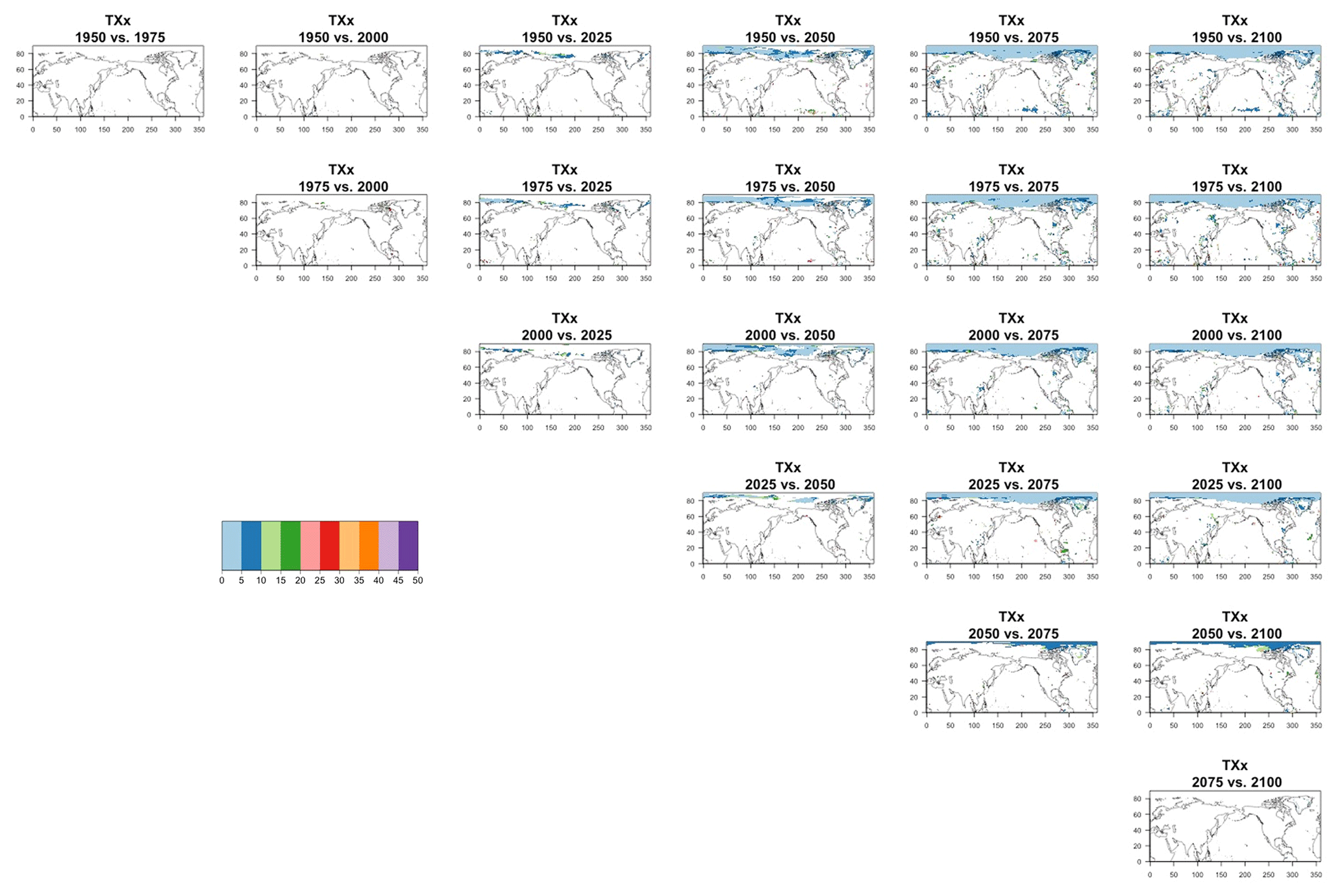
Figure C33Estimating changes in ensemble variance for TXx in the CESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 40-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
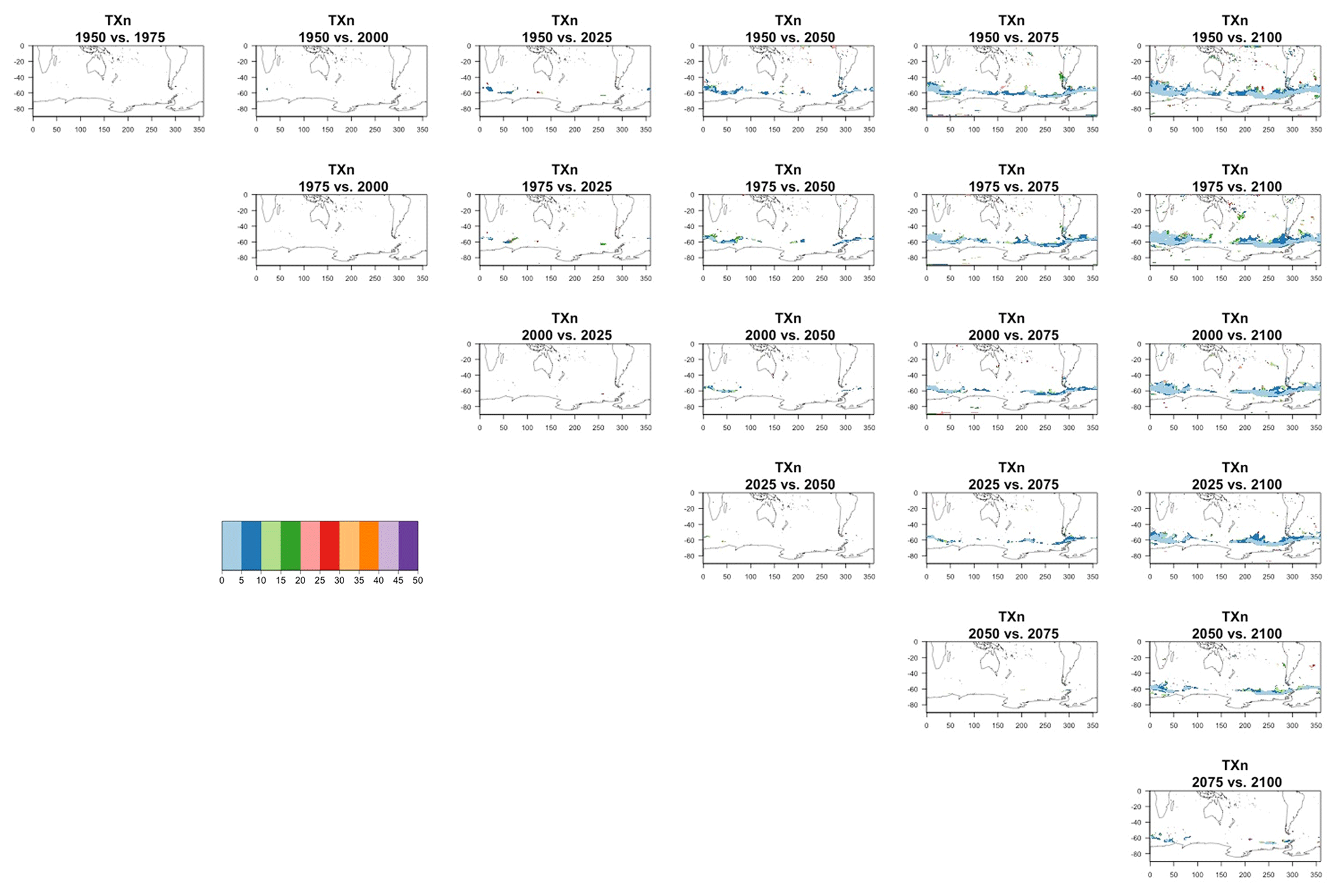
Figure C34Estimating changes in ensemble variance for TXn in the CESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 40-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
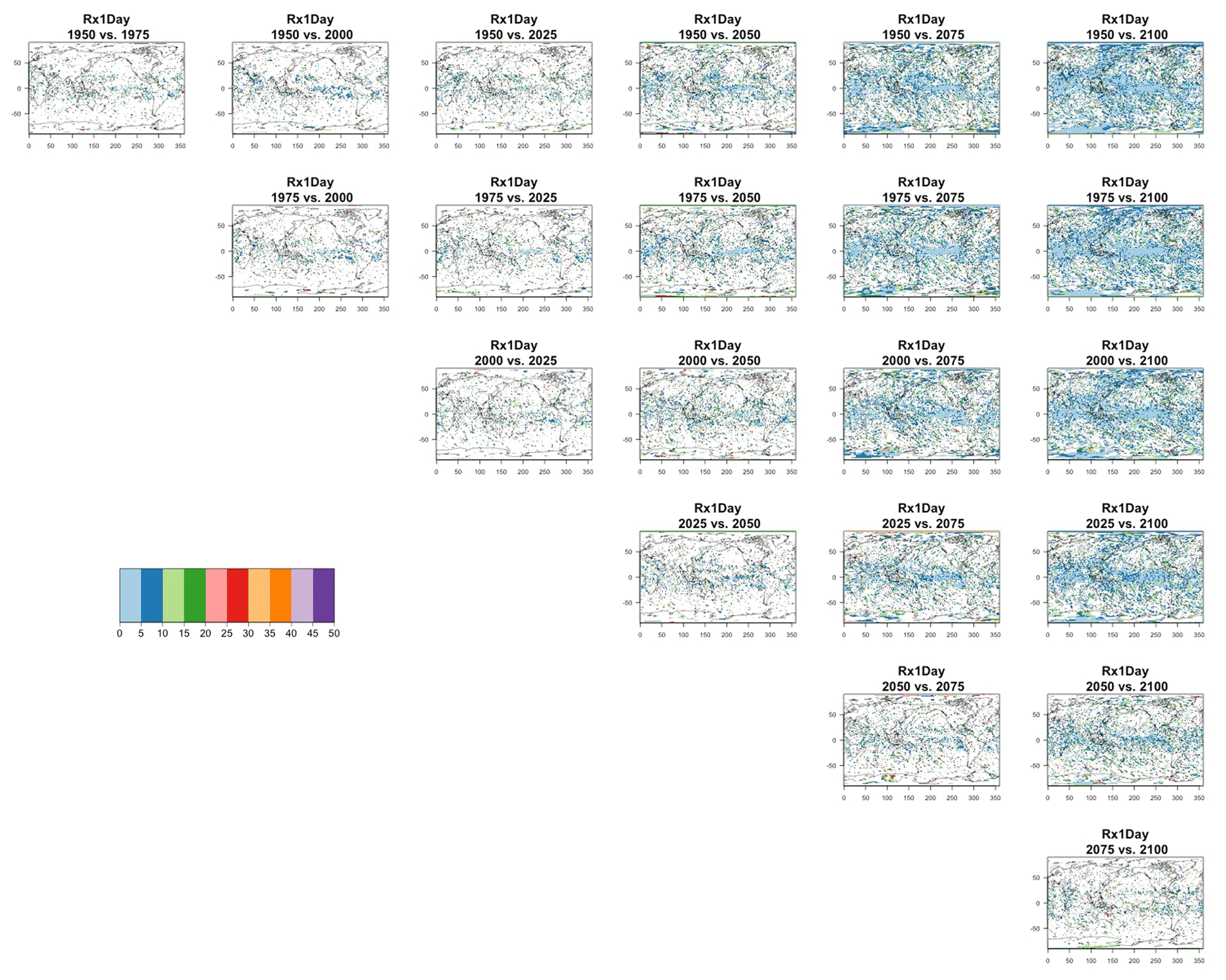
Figure C35Estimating changes in ensemble variance for Rx1Day in the CESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 40-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
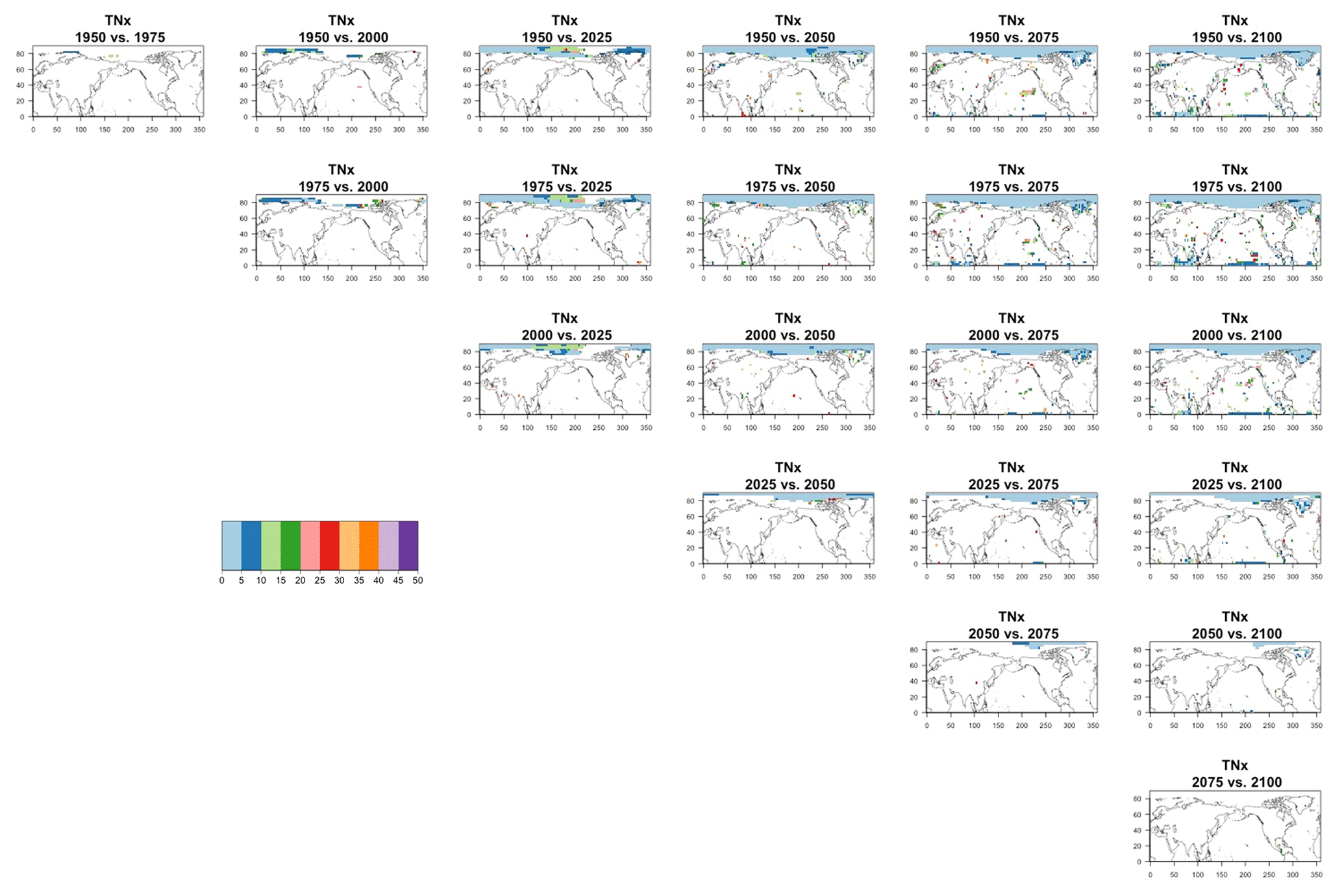
Figure C36Estimating changes in ensemble variance for TNx in the CanESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 50-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
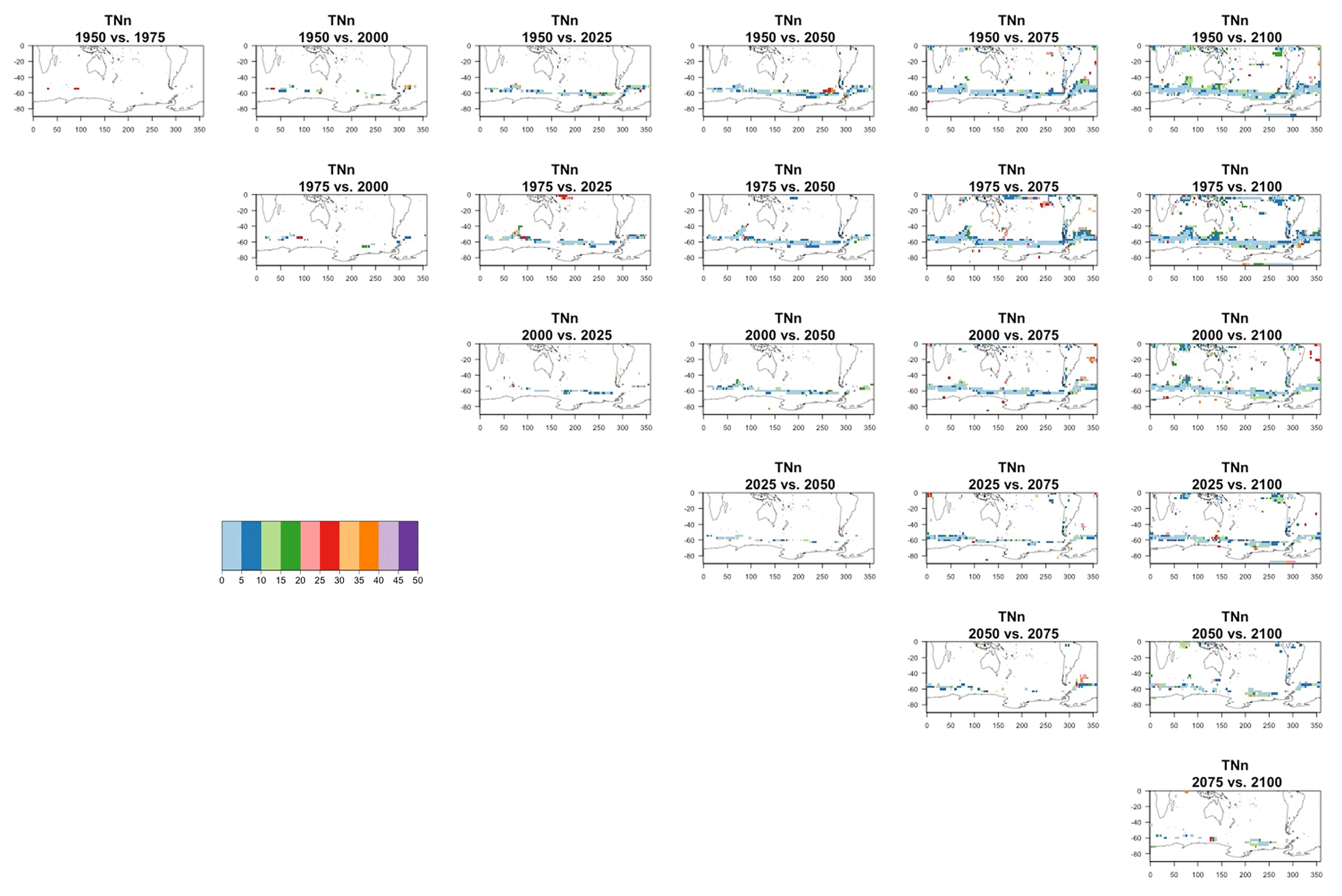
Figure C37Estimating changes in ensemble variance for TNn in the CanESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 50-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
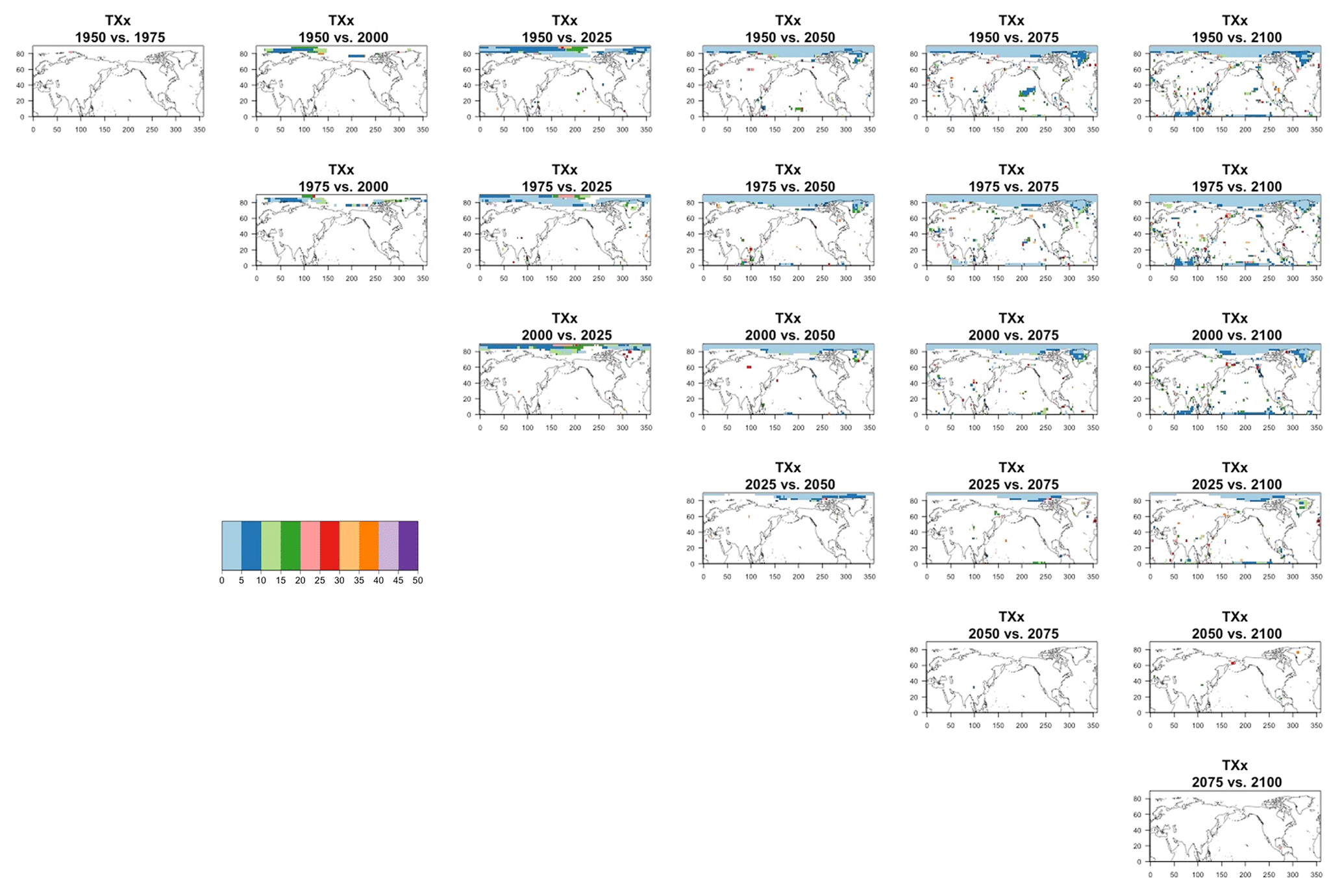
Figure C38Estimating changes in ensemble variance for TXx in the CanESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 50-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
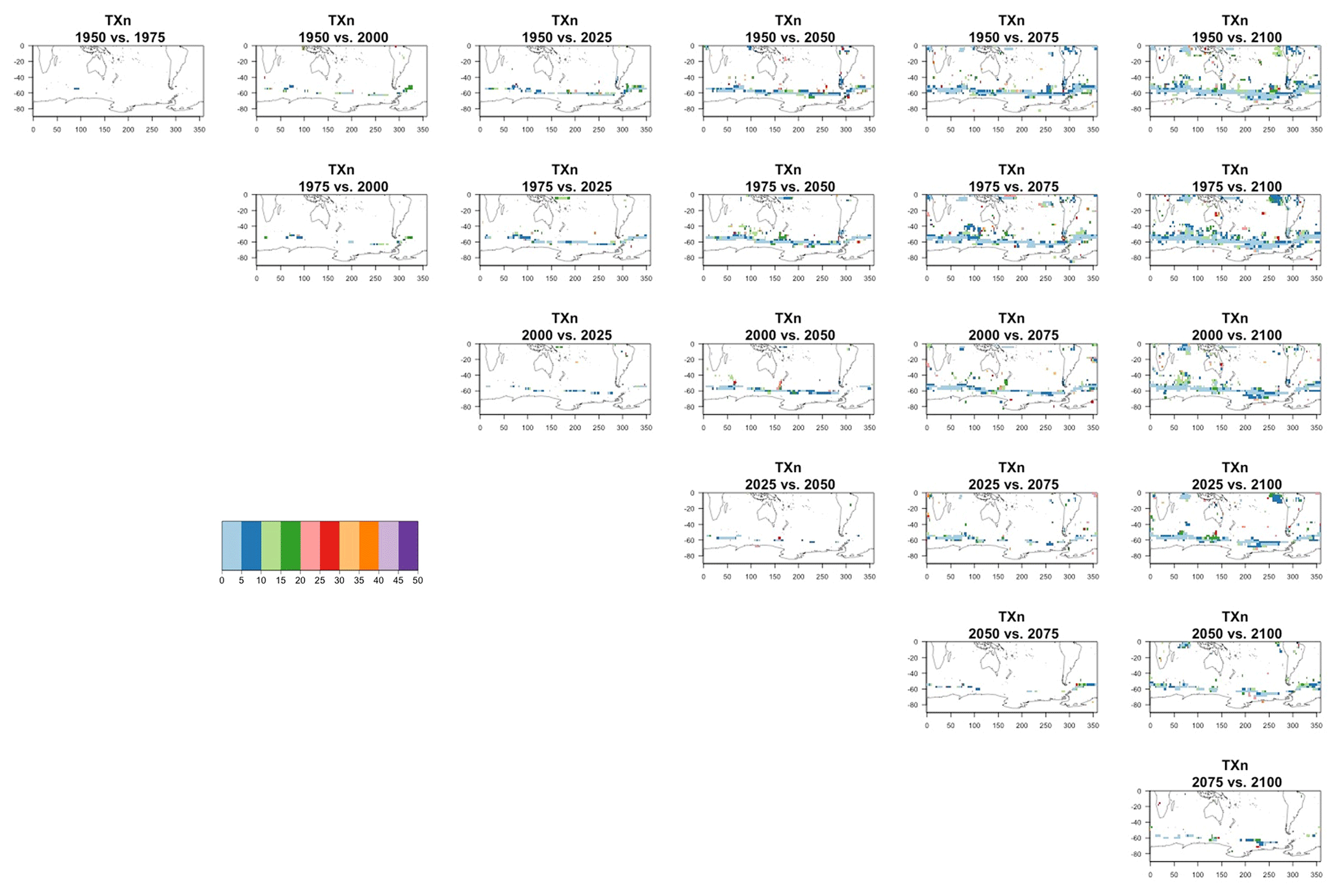
Figure C39Estimating changes in ensemble variance for TXn in the CanESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 50-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
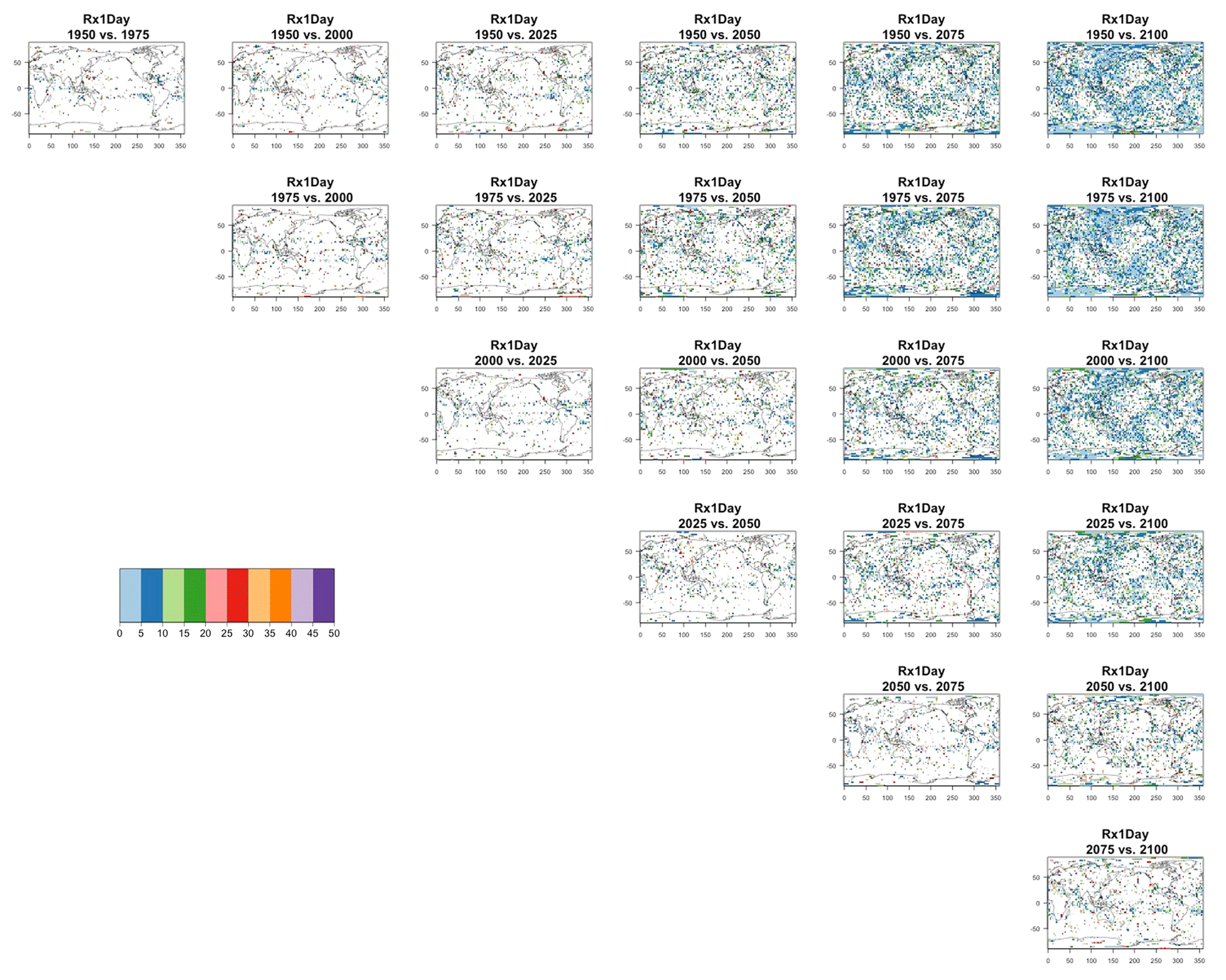
Figure C40Estimating changes in ensemble variance for Rx1Day in the CanESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 50-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here too the sample size is increased by using 5 years around each date.
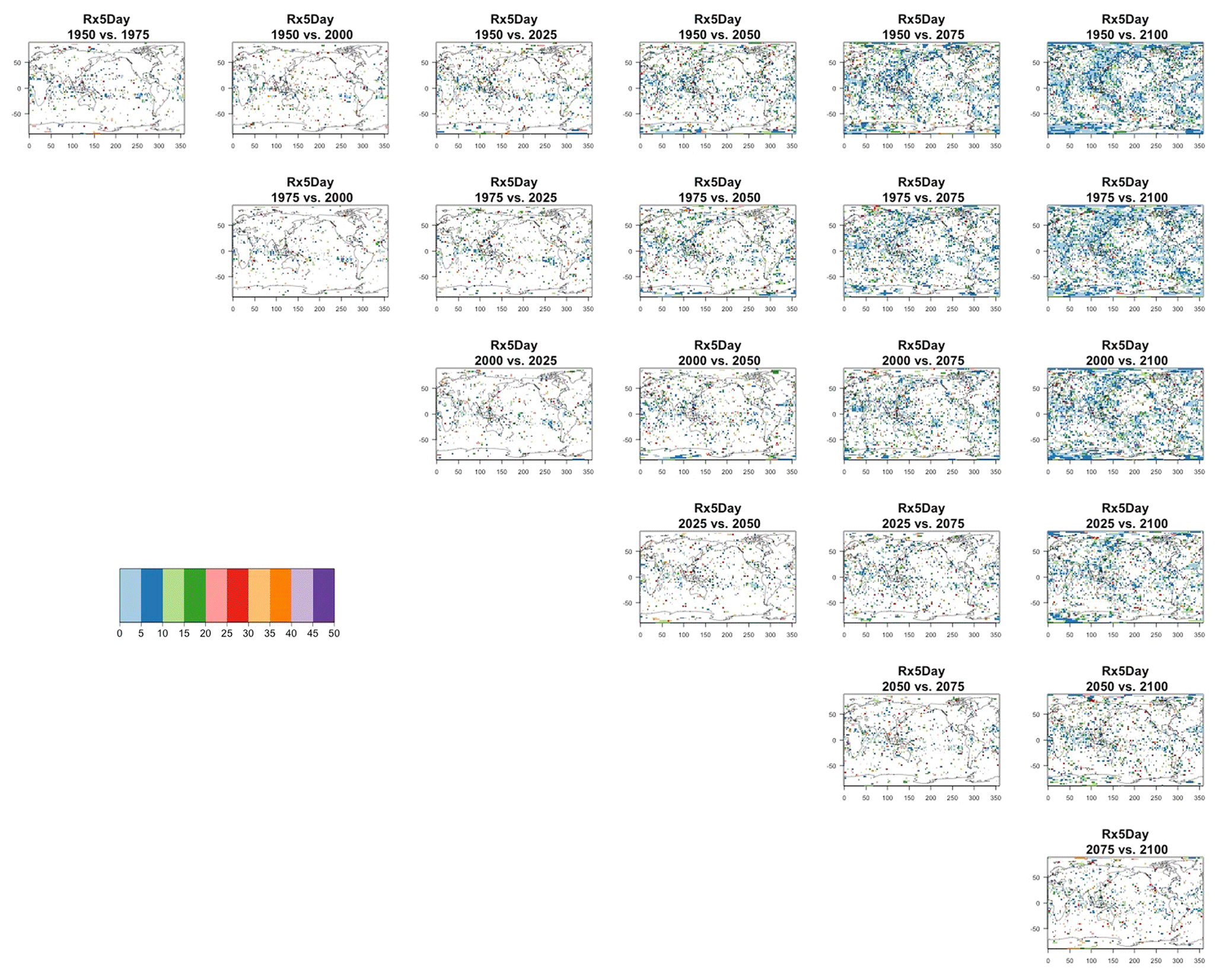
Figure C41Estimating changes in ensemble variance for Rx5Day in the CanESM ensemble: each plot corresponds to a pair of years along the simulation. Colored areas are regions where on the basis of the full 50-member ensemble a significant change in variance was detected. The colors indicate the size of the smaller ensemble needed to detect the same change. Here, too, the sample size is increased by using 5 years around each date.
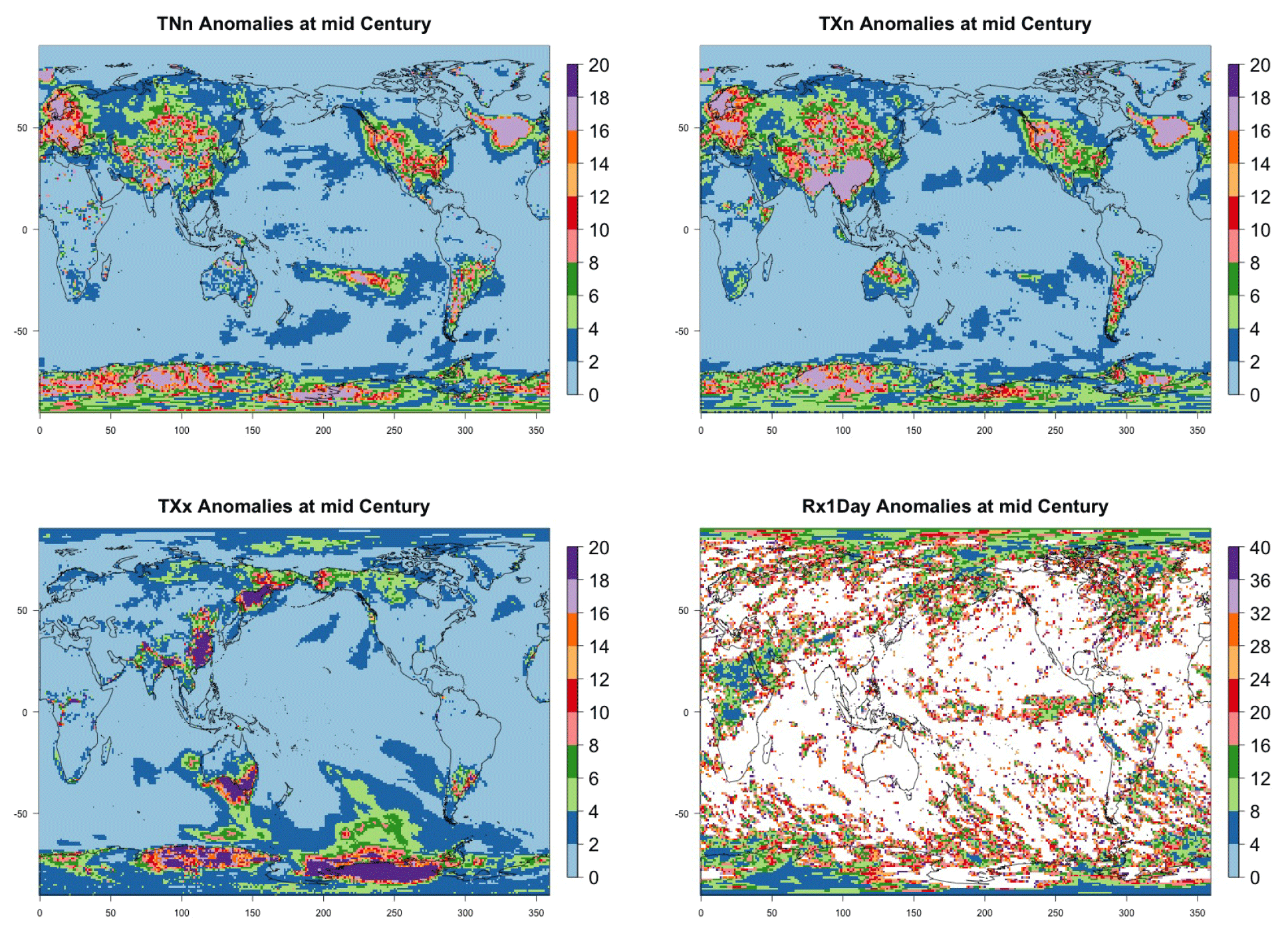
Figure C42Ensemble size n required for the signal-to-noise ratio of the grid-point scale anomalies to exceed 2 (anomalies defined as the mean of 2048–2052 minus the historical baseline of 2000–2005). Results are shown for CESM and all remaining metrics not shown in the main text: coldest night (TNn) and coldest day (TXn) of the year along the top row; Hottest day (TXx) and wettest day (Rx1Day) of the year along the bottom row.
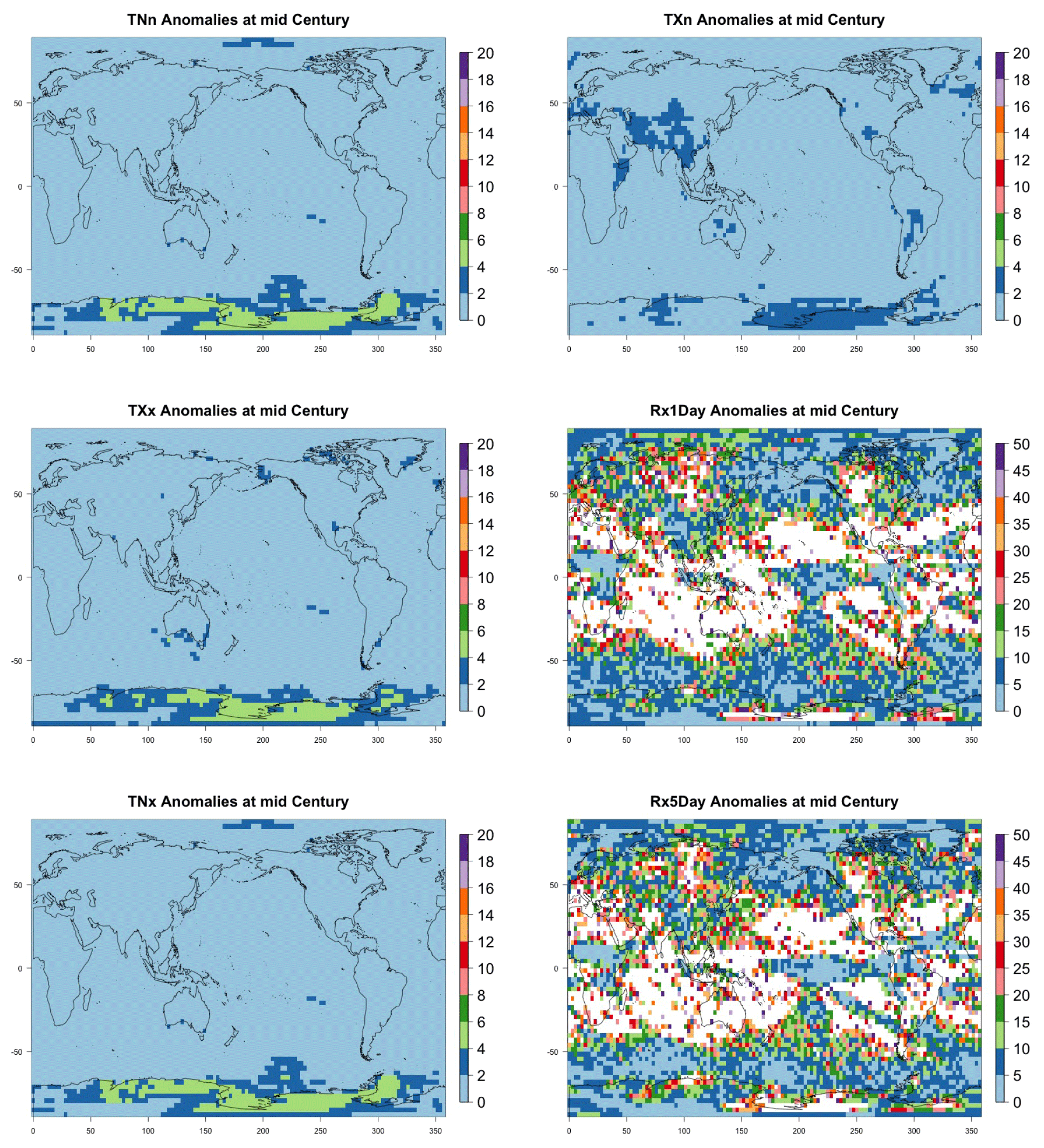
Figure C43Ensemble size n required for the signal-to-noise ratio of the grid-point scale anomalies to exceed 2 (anomalies defined as the mean of 2048–2052 minus the historical baseline of 2000–2005). Results are shown for CanESM and all metrics: coldest night (TNn) and coldest day (TXn) of the year on the top row; hottest day (TXx) and wettest day (Rx1Day) of the year on the middle row; hottest night (TNx) and wettest 5 d (Rx5Day) of the year on the bottom row.
The large ensembles output is available through the CLIVAR Large Ensemble Working Group webpage in the archive maintained through the NCAR CESM community project http://cesm.ucar.edu/projects/community-projects/MMLEA/ (last access: 2 February 2021). The R code for these analyses is available from the first author on reasonable request.
CT conceived the study, analyzed the data and wrote the paper. KD and MW provided data pre-processing and co-wrote the paper. RL advised and co-wrote the paper.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors would like to thank Flavio Lehner and Chengzhu (Jill) Zhang for help with data access, and two anonymous reviewers and the editor for comments that helped improve the study significantly.
This study was supported by the Energy Exascale Earth System Model (E3SM) project funded by the US Department of Energy, Office of Science, Office of Biological and Environmental Research. Michael Wehner was supported by the CASCADE project also funded by the US Department of Energy, Office of Science, Office of Biological and Environmental Research. The Pacific Northwest National Laboratory is operated by Battelle for the US Department of Energy (contract no. DE-AC05-76RLO1830). Lawrence Berkeley National Laboratory is operated by the US Department of Energy (contract no. DE340AC02-05CH11231).
This paper was edited by Christian Franzke and reviewed by two anonymous referees.
Alexander, L. V.: Global Observed Long-term Changes in Temperature and Precipitation Extremes: a Review of Progress and Limitations in IPCC Assessments and Beyond, Weather and Climate Extremes, 11, 4–16, 2016. a
Arora, V. K., Scinocca, J. F., Boer, G. J., Christian, J. R., Denman, K. L., Flato, G. M., Kharin, V. V., Lee, W. G., and Merryfield, W. J.: Carbon emission limits required to satisfy future representative concentration pathways of greenhouse gases, Geophys. Res. Lett., 38, L05805, https://doi.org/10.1029/2010GL046270, 2011. a
Bittner, M., Schmidt, H., Timmreck, C., and Sienz, F.: Using a large ensemble of simulations to assess the Northern Hemisphere stratospheric dynamical response to tropical volcanic eruptions and its uncertainty, Geophys. Res. Lett., 43, 9324–9332, https://doi.org/10.1002/2016GL070587, 2016. a
Coles, S.: An Introduction to Statistical Modeling of Extreme Values, Springer-Verlag, London, London, United Kingdom, 2001. a
Deser, C., Phillips, A., Bourdette, V., and Teng, H.: Uncertainty in Climate Change Projections: the Role of Internal Variability, Clim. Dynam., 38, 527–546, https://doi.org/10.1007/s00382-010-0977-x, 2012. a
Deser, C., Lehner, F., Rodgers, K. B., Ault, T., Delworth, T. L., DiNezio, P. N., Fiore, A., Frankignoul, C., Fyfe, J. C., Horton, D. E., Kay, J. E., Knutti, R., Lovenduski, N. S., Marotzke, J., McKinnon, K. A., Minobe, S., Randerson, J., Screen, J. A., Simpson, I. R., and Ting, M.: Insights from Earth system model initial-condition large ensembles and future prospects, Nat. Clim. Change, 10, 277–286, https://doi.org/10.1038/s41558-020-0731-2, 2020. a, b
Gilleland, E. and Katz, R. W.: extRemes 2.0: An Extreme Value Analysis Package in R, J. Statist. Softw., 72, 1–39, https://doi.org/10.18637/jss.v072.i08, 2016. a
Hawkins, E. and Sutton, R.: The Potential to Narrow Uncertainty in Regional Climate Predictions, B. Am. Meteorol. Soc., 90, 1095–1108, https://doi.org/10.1175/2009BAMS2607.1, 2009. a
Hawkins, E. and Sutton, R.: The potential to narrow uncertainty in projections of regional precipitation change, Clim. Dynam., 37, 407–418, https://doi.org/10.1007/s00382-010-0810-6, 2011. a
Hawkins, E., Smith, R. S., Gregory, J. M., and Stainforth, D. A.: Irreducible uncertainty in near-term climate projections, Clim. Dynam., 46, 3807–3819, https://doi.org/10.1007/s00382-015-2806-8, 2016. a
Huntingford, C., Jones, P. D., Livina, V. N., Lenton, T. M., and Cox, P. M.: No increase in global temperature variability despite changing regional patterns, Nature, 500, 327–330, https://doi.org/10.1038/nature12310, 2013. a
Hurrell, J. W., Holland, M. M., and Gent, P. R.: The Community Earth System Model: A Framework for Collaborative Research, B. Am. Meteorol. Soc., 94, 1339–1360, https://doi.org/10.1175/BAMS-D-12-00121.1, 2013. a
Kay, J. E., Deser, C., Phillips, A., Mai, A., Hannay, C., Strand, G., Arblaster, J. M., Bates, S. C., Danabasoglu, G., Edwards, J., Holland, M., Kushner, P., Lamarque, J.-F., Lawrence, D., Lindsay, K., Middleton, A., Munoz, E., Neale, R., Oleson, K., Polvani, L., and Vertenstein, M.: The Community Earth System Model (CESM) Large Ensemble Project: A Community Resource for Studying Climate Change in the Presence of Internal Climate Variability, B. Am. Meteorol. Soc., 96, 1333–1349, https://doi.org/10.1175/BAMS-D-13-00255.1, 2015. a, b
Kirchmeier-Young, M. C., Zwiers, F. W., and Gillett, N. P.: Attribution of Extreme Events in Arctic Sea Ice Extent, J. Climate, 30, 553–571, https://doi.org/10.1175/JCLI-D-16-0412.1, 2017. a
Knutti, R., Furrer, R., Tebaldi, C., Cermak, J., and Meehl, G. A.: Challenges in Combining Projections from Multiple Climate Models, J. Climate, 23, 2739–2758, https://doi.org/10.1175/2009JCLI3361.1, 2010. a
Kushner, P. J., Mudryk, L. R., Merryfield, W., Ambadan, J. T., Berg, A., Bichet, A., Brown, R., Derksen, C., Déry, S. J., Dirkson, A., Flato, G., Fletcher, C. G., Fyfe, J. C., Gillett, N., Haas, C., Howell, S., Laliberté, F., McCusker, K., Sigmond, M., Sospedra-Alfonso, R., Tandon, N. F., Thackeray, C., Tremblay, B., and Zwiers, F. W.: Canadian snow and sea ice: assessment of snow, sea ice, and related climate processes in Canada's Earth system model and climate-prediction system, The Cryosphere, 12, 1137–1156, https://doi.org/10.5194/tc-12-1137-2018, 2018. a
Leduc, M., Mailhot, A., Frigon, A., Martel, J.-L., Ludwig, R., Brietzke, G. B., Gigu?re, M., Brissette, F., Turcotte, R., Braun, M., and Scinocca, J.: The ClimEx Project: A 50-Member Ensemble of Climate Change Projections at 12-km Resolution over Europe and Northeastern North America with the Canadian Regional Climate Model (CRCM5), J. Appl. Meteorol. Climatol., 58, 663–693, https://doi.org/10.1175/JAMC-D-18-0021.1, 2019. a
Lehner, F., Deser, C., Maher, N., Marotzke, J., Fischer, E. M., Brunner, L., Knutti, R., and Hawkins, E.: Partitioning climate projection uncertainty with multiple large ensembles and CMIP5/6, Earth Syst. Dynam., 11, 491–508, https://doi.org/10.5194/esd-11-491-2020, 2020. a, b, c
Li, H. and Ilyina, T.: Current and Future Decadal Trends in the Oceanic Carbon Uptake Are Dominated by Internal Variability, Geophys. Res. Lett., 45, 916–925, https://doi.org/10.1002/2017GL075370, 2018. a
Maher, N., Matei, D., Milinski, S., and Marotzke, J.: ENSO Change in Climate Projections: Forced Response or Internal Variability?, Geophys. Res. Lett., 45, 11,390–11,398, https://doi.org/10.1029/2018GL079764, 2018. a
Maher, N., Milinski, S., and Ludwig, R.: Large ensemble climate model simulations: introduction, overview, and future prospects for utilising multiple types of large ensemble, Earth Syst. Dynam., 12, 401–418, https://doi.org/10.5194/esd-12-401-2021, 2021a. a
Maher, N., Power, S. B., and Marotzke, J.: More accurate quantification of model-to-model agreement in externally forced climatic responses over the coming century, Nat. Commun., 12, 788, https://doi.org/10.1038/s41467-020-20635-w, 2021b. a
Marotzke, J.: Quantifying the irreducible uncertainty in near-term climate projections, WIREs Climate Change, 10, e563, https://doi.org/10.1002/wcc.563, 2019. a, b
Milinski, S., Maher, N., and Olonscheck, D.: How large does a large ensemble need to be?, Earth Syst. Dynam., 11, 885–901, https://doi.org/10.5194/esd-11-885-2020, 2020. a, b, c
Pausata, F. S. R., Grini, A., Caballero, R., Hannachi, A., and Seland, Ø.: High-latitude volcanic eruptions in the Norwegian Earth System Model: the effect of different initial conditions and of the ensemble size, Tellus B, 67, 26728, https://doi.org/10.3402/tellusb.v67.26728, 2015. a
Riahi, K., Rao, S., Krey, V., Cho, C., Chirkov, V., Fischer, G., Kindermann, G., Nakicenovic, N., and Rafaj, P.: RCP 8.5 – A scenario of comparatively high greenhouse gas emissions, Clim. Change, 109, 33, https://doi.org/10.1007/s10584-011-0149-y, 2011. a
Steinman, B. A., Frankcombe, L. M., Mann, M. E., Miller, S. K., and England, M. H.: Response to Comment on “Atlantic and Pacific multidecadal oscillations and Northern Hemisphere temperatures”, Science, 350, 1326–1326, https://doi.org/10.1126/science.aac5208, 2015. a
Taylor, K. E., Stouffer, R. J., and Meehl, G. A.: An Overview of CMIP5 and the Experiment Design, B. Am. Meteorol. Soc., 93, 485–498, https://doi.org/10.1175/BAMS-D-11-00094.1, 2012. a
Ventura, V., Paciorek, C., and Risbey, J. S.: Controlling the Proportion of Falsely Rejected Hypotheses when Conducting Multiple Tests with Climatological Data, J. Climate, 17, 4343–4356, https://doi.org/10.1175/3199.1, 2004. a, b, c
Wehner, M. F.: A method to aid in the determination of the sampling size of AGCM ensemble simulations, Clim. Dynam., 16, 321–331, https://doi.org/10.1007/s003820050331, 2000. a
Wilks, D. S.: “The Stippling Shows Statistically Significant Grid Points”: How Research Results are Routinely Overstated and Overinterpreted, and What to Do about It, B. Am. Meteorol. Soc., 97, 2263–2273, https://doi.org/10.1175/BAMS-D-15-00267.1, 2016. a, b
Available from Gilleland and Katz (2016)
Since some of the simulations end at 2099, this becomes 2094 in such cases.
- Abstract
- Introduction
- Models, experiments and metrics
- Methods
- Results
- Conclusions
- Appendix A: RMSE estimation for more indices and based on the CanESM ensemble
- Appendix B: Summary of error ratio patterns as shown in Figs. 3 and 4 for all metrics and models
- Appendix C: Additional figures
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Models, experiments and metrics
- Methods
- Results
- Conclusions
- Appendix A: RMSE estimation for more indices and based on the CanESM ensemble
- Appendix B: Summary of error ratio patterns as shown in Figs. 3 and 4 for all metrics and models
- Appendix C: Additional figures
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References