the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 15 Oct 2024
| 15 Oct 2024
Uncertainty-informed selection of CMIP6 Earth system model subsets for use in multisectoral and impact models
Abigail Snyder
Noah Prime
Claudia Tebaldi
Kalyn Dorheim
Earth system models (ESMs) and general circulation models (GCMs) are heavily used to provide inputs to sectoral impact and multisector dynamic models, which include representations of energy, water, land, economics, and their interactions. Therefore, representing the full range of model uncertainty, scenario uncertainty, and interannual variability that ensembles of these models capture is critical to the exploration of the future co-evolution of the integrated human–Earth system. The pre-eminent source of these ensembles has been the Coupled Model Intercomparison Project (CMIP). With more modeling centers participating in each new CMIP phase, the size of the model archive is rapidly increasing, which can be intractable for impact modelers to effectively utilize due to computational constraints and the challenges of analyzing large datasets. In this work, we present a method to select a subset of the latest phase, CMIP6, featuring models for use as inputs to a sectoral impact or multisector dynamics models, while prioritizing preservation of the range of model uncertainty, scenario uncertainty, and interannual variability in the full CMIP6 ensemble results. This method is intended to help impact modelers select climate information from the CMIP archive efficiently for use in downstream models that require global coverage of climate information. This is particularly critical for large-ensemble experiments of multisector dynamic models that may be varying additional features beyond climate inputs in a factorial design, thus putting constraints on the number of climate simulations that can be used. We focus on temperature and precipitation outputs of CMIP6 models, as these are two of the most used variables among impact models, and many other key input variables for impacts are at least correlated with one or both of temperature and precipitation (e.g., relative humidity). Besides preserving the multi-model ensemble variance characteristics, we prioritize selecting CMIP6 models in the subset that preserve the very likely distribution of equilibrium climate sensitivity values as assessed by the latest Intergovernmental Panel on Climate Change (IPCC) report. This approach could be applied to other output variables of climate models and, possibly when combined with emulators, offers a flexible framework for designing more efficient experiments on human-relevant climate impacts. It can also provide greater insight into the properties of existing CMIP6 models.
- Article
(8874 KB) - Full-text XML
- BibTeX
- EndNote




The future evolution of the integrated human–Earth system is highly uncertain, but one common approach to begin addressing this uncertainty is to use outputs from a variety of computationally expensive, highly detailed process-based Earth system models (ESMs) and general circulation models (GCMs) run under different scenarios. This approach has been facilitated by the Coupled Model Intercomparison Project (CMIP; Eyring et al., 2016), which has organized experiments that are standardized across modeling centers. Scenario simulations from CMIP, most recently through ScenarioMIP (O'Neill et al., 2016), are commonly used as inputs to downstream sectoral impact and multisector dynamic models, both by individual modeling efforts and by large coordinated impact modeling projects like AgMIP or ISIMIP (e.g., Rosenzweig et al., 2013, 2014; Warszawski et al., 2014; Frieler et al., 2017). Using such multi-model ensembles captures the process and structural uncertainties represented by sampling across ESMs/GCMs, scenario uncertainty, and, to the extent that an ESM/GCM runs multiple initial-condition ensemble members for a scenario, internal variability in the individual ESM (Hawkins and Sutton, 2009, 2011; Lehner et al., 2020). These Earth system uncertainties can then be propagated through an impact model (perhaps after bias correction; Lange, 2019) to understand possible human-relevant outcomes.
From the Earth system modelers who produce climate data to the impact and multisector dynamic modelers who use it, each step in this process is computationally expensive. For Earth system modelers, variability across ESM/GCM projections of future climate variables can be significant (Hawkins and Sutton, 2009, 2011; Lehner et al., 2020), and so the participation of multiple modeling centers running multiple scenarios is critical to understanding the future of the Earth system. Furthermore, statistical evaluation (Tebaldi et al., 2021) suggests that 20–25 initial-condition ensemble members for each scenario that an ESM/GCM provides are needed to estimate the forced component of extreme metrics related to daily temperature and precipitation, which are key inputs to many impact models covering hydrological, agricultural, energy, and other sectors. Fortunately, emulation of ESM/GCM outputs to infill missing scenarios and enrich initial-condition ensembles continues to improve (Beusch et al., 2020; Nath et al., 2022; Quilcaille et al., 2022; Tebaldi et al., 2022). This suggests that ESMs/GCMs do not necessarily have to provide all of the runs desired for capturing possible futures but instead a subset of scenarios including initial-condition ensembles for emulator training. The total burden across the modeling and analysis community to sample across ESMs/GCMs and scenarios still remains high, even with the potential efficiency provided by emulators. Downstream from the physical climate science community, impact modelers often seek to understand future climate impacts in the context of ESM uncertainty using the outputs of multiple ESMs under multiple scenarios as inputs to impact models (e.g., Prudhomme et al., 2014; Müller et al., 2021). In a world unburdened by time and computing constraints, an impact model would take as input every projected dataset available (possibly weighted according to observation and/or by model independence) to have a full understanding of the total variance in possible outcomes. Our world includes those burdens, which are made even larger when impact models require bias-corrected climate data as input. This can quickly become an intractably sized set of runs to perform and analyze for impact modelers. For the multisector dynamics community, whose modelers often attempt to integrate results from multiple impact models to understand interactions of different sectors (like energy, water, land, and economics) of the integrated human–Earth system (Graham et al., 2020), this challenge multiplies. Finally, multisector dynamic models are beginning to run large-ensemble experiments that vary additional features beyond climate inputs in a factorial design (e.g., Dolan et al., 2021, 2022; Guivarch et al., 2022) further adding to the computational costs to be faced. The multisector dynamics approach is the approach that the examples in this work focus on downstream models that require global coverage of a variety of climate model output variables at different temporal scales. Were a study to be focused on particular regions or localized impacts and dynamics, other selection criteria, such as model skill (closeness to observation, ability to replicate modes of variability known to be particularly important to that region, etc.) and the effect of downscaling and bias correction, known to introduce additional sources of variability and uncertainty (Lafferty and Sriver, 2023) in that region could be explored.
For all communities involved, an efficient way to design and then use climate model runs is critical. While there is likely no perfect solution to balance the tension between the competing priorities of different climate data creators and climate data users, this work describes a method for selecting a subset of CMIP6 models that prioritizes retaining the overall uncertainty characteristics of the entire data set, particularly in dimensions relevant to impact and multisectoral modelers. The method proposed here exists in the context of a rich literature on model selection, with methods focused on model skill in comparison to observation and/or tracking and controlling for climate model dependence (Abramowitz et al., 2019; Brands, 2022; Merrifield et al., 2023; Parding et al., 2020). These are critical aspects to consider when subselecting climate models for downstream use. Merrifield et al. (2023) do include model spread as a critical consideration for model selection, but to our knowledge, there is no uncertainty-first consideration of climate model selection. The method we present in this work is an adaptable framework that could complement other approaches based on skill and climate model independence, and some of the choices made in implementing this method may be adaptable for other uses or priorities.
We approach the question of uncertainty in the full collection of CMIP6 models as being one of understanding the total variance in the CMIP6 outputs, which, following the Hawkins and Sutton framing of the problem (Hawkins and Sutton, 2009, 2011; Lehner et al., 2020), we understand as coming from three sources: internal variability and scenario and model uncertainties. Rather than attributing fractions of total variance to different sources and optimizing that as part of the selection process, however, we focus on projecting the data into a new coordinate basis designed to maximize total variance. Principal component analysis (PCA) does exactly this; it identifies a new set of basis vectors maximizing total variance that data can be projected into. Once climate model data have been projected into this space (e.g., as in Fig. 3), it is possible to sample a subset of climate models that cover the spread of the projections of the full set of climate model outputs in this variance-maximizing space.
The overall steps of this method are summarized in Table 1. Section 2.1 and 2.2 provide fuller details on using PCA to characterize the full set of climate model data (Sect. 2.1) and selecting a representative subset of climate models within that characterization (Sect. 2.2). Table 1 especially highlights the choices made for this particular effort, based on the authors' experience with multisectoral impact modeling. Section 2.3 outlines our approach to evaluating the extent to which our model subset preserves the uncertainty properties of the full data set. Nothing in the method prevents its being adapted with different regions of interest, indices of behavior, or ESM/GCM output variables, although evaluation of results in new implementations would be necessary.
Table 1Summary of method.
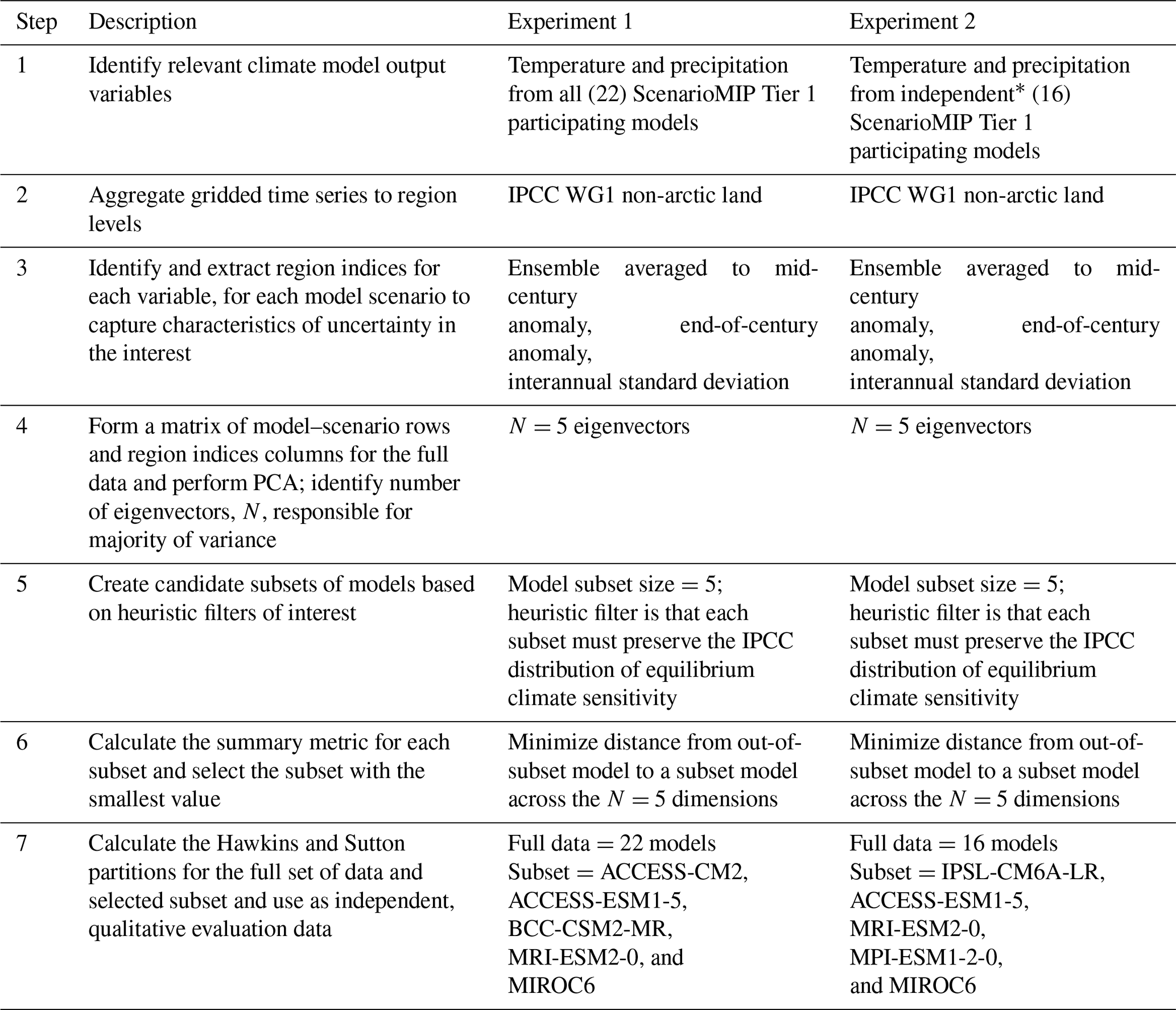
∗ Independent as defined in this work; many definitions exist.
2.1 Data preparation and characterization
Impact models often require multiple output variables from a climate model on daily or monthly timescales, with temperature and precipitation being the most common variables needed. For tractability, we focus on the Intergovernmental Panel on Climate Change (IPCC) Working Group I (WG1) non-arctic land regions (Iturbide et al., 2022), as these regions are primarily where humans live, consume water, generate electricity, and grow food; i.e., these are the places most relevant in multisectoral models of the integrated human–Earth system. We also limit ourselves to ESMs/GCMs that completed all four ScenarioMIP Tier 1 experiments (Table 2). This still results in more than 600 trajectories across models, scenarios, and ensemble members for each region.
Table 2Models and scenarios making up the full set of data, as well as their equilibrium climate sensitivity (ECS) values (sourced from Meehl et al., 2020, Lovato et al., 2022, and Zelinka et al., 2020). Note that even the Earth system models in CMIP6 run these experiments in concentration-driven mode rather than emissions-driven mode.
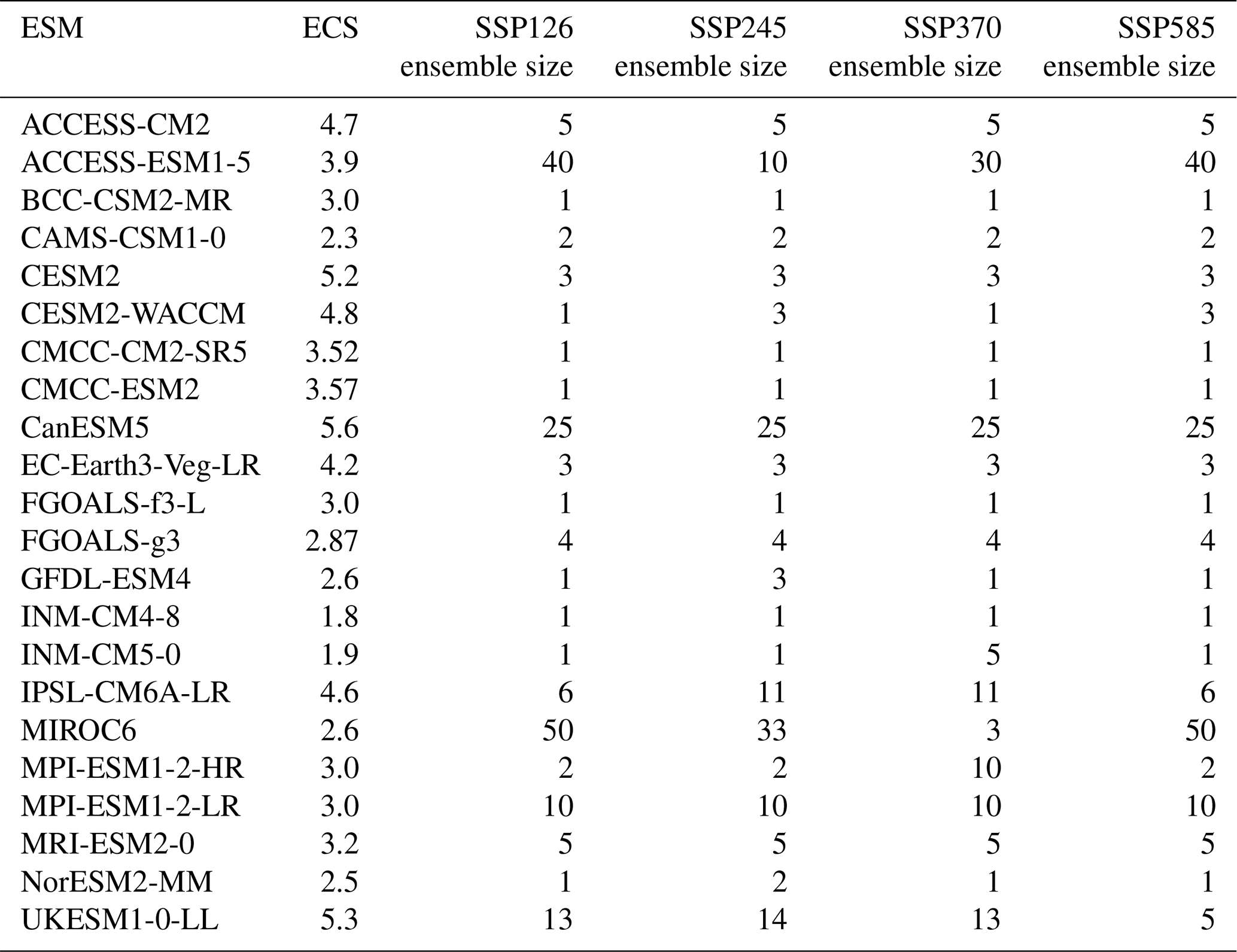
In this work, we are treating this collection of ESMs/GCMs and scenario results in these regions as the full set of data of which we would like to faithfully represent the uncertainty characteristics, and we then select a subset of climate models for impact modelers to use, based on preserving those characteristics. A critical point, however, is that once the full set of climate data is characterized, as we outline in this section, the selection step of the method includes a step to restrict the equilibrium climate sensitivity (ECS) distribution of the model subset to reflect that of the IPCC Sixth Assessment Report (AR6)-defined most likely distribution (Core Writing Team et al., 2023). This shifts the average ECS value of the selected subset down relative to the existing full data covered in Table 2. Following this ECS distribution, a single high ECS climate model is allowed to be included in the subset, allowing the “hot model problem” (Hausfather et al., 2022) to be addressed as part of the model subset selection process, as well as ensuring that a range of model behaviors across different ECS values is included. Models for which we could not readily identify ECS values in the literature are included in the characterization of the full space, but they are not eligible for selection in the subset, as preserving the IPCC distribution of ECS values is a critical filter in this selection process for the examples outlined in this work (more details in Sect. 2.2).
For each scenario, region, and available ensemble member in each in each ESM/GCM, we extract the following temperature and precipitation outputs: mid-century (2040–2059) average anomaly relative to that model's historical average (1995–2014), the end-of-century (2080–2099) anomaly relative to the historical average, and the interannual standard deviation (IASD). The interannual standard deviation is calculated by detrending the regional average level temperature and precipitation time series from 1994–2100, using non-parametric and locally weighted smoothing (loess, as implemented in the Python statsmodels package), and then taking the standard deviation of the residuals. For each scenario and model, these ensemble member values are used to calculate the ensemble average to form our final indices in each region. These six indices (three for each of temperature and precipitation) per ESM-scenario-region combination are selected to result in data that represent the model uncertainty, scenario uncertainty, and interannual variability in our full set of data. By focusing on ensemble averages, models that performed more realizations are not over-represented in the overall space. When an ensemble size is only one realization, then that realization's value is used. The key question is how to efficiently characterize this collection of data in a way that enables an efficient subsampling of models that still preserves the main dimensions of variations in the full ensemble.
These full data can be written as a matrix A with Nmodel*Nscenarios rows and Nindices*Nregions columns. In the case of considering all 22 models listed in Table 2 as representative of the full space, this makes 88 rows and 258 columns, and we use these numbers for simplicity in some of the vector descriptions that follow. Below, we outline two experiments that highlight the adaptability of this method by considering model dependency in the CMIP6 models versus not doing so. In the case of restricting to independent models only to make up the full data, these numbers will, of course, change.
Principal component analysis (PCA) is then a natural technique to understand the variance in this full data set by forming the covariance matrix S=ATA. The eigenvectors of S are a set of orthogonal basis vectors (each vector has a length of 258) that is ordered by how much variance of the full data each eigenvector explains. Mathematically, this means that each row of A (), representing the indices in all regions for a single climate model scenario, can be projected into the space of eigenvectors and written as ai=ΣjcijPCj for the projection coefficients (coordinates in the basis of eigenvectors), cij. Thus PC1, for example, represents some pattern of joint, spatiotemporal temperature, and precipitation behaviors that explains the greatest variance across ESM-/GCM-scenario observations. Each CMIP6 model–scenario combination has some contribution from this pattern described by its projection coefficient, ci1. This projection can be done over all eigenvectors or, as is common with PCA, a small subset of the eigenvectors that explain the majority of variance.
To demonstrate the flexibility of this approach to characterizing data, we perform the same analysis in two different experiments:
-
Experiment 1 assumes all 22 models listed in Table 2 make up the full data.
-
Experiment 2 assumes the full data are made up of only 16 of the models in Table 2, with ACCESS-CM2, CESM2-WACCM, CMCC-CM2-SR5, FGOALS-f3-L, INM-CM4-8, and MPI-ESM1-2-HR being removed from consideration as they share clear model dependencies with other models in the full data. When deciding which of two related models to keep, we chose based on keeping the model with greater number of realizations as this is valuable for downstream uses. Other criteria could be used to define model dependency and make selections, as determining model independence is itself a rich field of study (Abramowitz et al., 2019; Brands, 2022; Merrifield et al., 2023).
Figure 1 is a plot of the fraction of variance explained by each of the first 15 eigenvectors in each experiment. Based on this figure, we restrict ourselves to the first five eigenvectors for projections (just after the “elbow”), explaining more than 70 % of total variance for each experiment. The number of eigenvectors considered is another area of flexibility of this method. There is no reason this method could not be applied to more or even all of the eigenvectors. However, the more eigenvectors that are considered, the higher dimensional the space that model selection must take place in. This slows down the calculations for selecting a subset considerably, at the benefit of explaining only a few extra percent of total variance with each vector added.

Figure 1Fraction of variance explained by each eigenvector of the principal component analysis on scaled data for Experiment 1 (a) and Experiment 2 (b) for the first 15 eigenvectors.
Figure 2 is a visual representation of these five eigenvectors for each experiment. Each row is a map of all indices for each eigenvector. While it is tempting to interpret differences in sign as meaningful, note that these are centered and scaled variables. Interpretation of the eigenvectors is also less meaningful than the fact that they represent an orthogonal coordinate system that maximizes total variance. For both experiments PC1 is dominated by temperature and, to a lesser extent, high-latitude precipitation, highlighting that these features are responsible for 38.7 % of the total variance of our full set of data (from Fig. 1). This is not the only contribution to total variance of temperature, of course, but it is a good sanity check that temperature anomalies are the most dominant feature in the dimension explaining the highest fraction of total variance. PC2 is dominated by temperature interannual variability and high-latitude precipitation interannual variability. PC3 to PC5 feature a mix of the indices, with strong emphasis on precipitation-related behaviors. Note that because we treated temperature and precipitation indices together in one matrix, the eigenvectors include joint temperature-precipitation behaviors that may be missed if the variables were treated separately. When comparing each map between the two experiments, it is worth noting that the spatial patterns are very similar between Experiment 1 and Experiment 2. Specifically, it is primarily in the southern latitudes in PC5 (explaining only ∼5 % of total variance in the full data in either experiment) that clear differences between the two experiments begin to emerge. This suggests that the patterns of total variance in this data set are dominated by differences beyond those that might be captured in our definition of model dependence. For example, maybe different representations of ocean physics are playing a large role. Testing of this hypothesis is outside the scope of this method description work but highlights the potential value of characterizing an archive of CMIP data in this way. In Figs. 1 and 3, we also see that the fraction of total variance explained by each eigenvector is similar across the two experiments. Overall, this similarity when accounting for model dependence versus not is not entirely surprising. The full data set in Experiment 1, with all of the model dependencies it includes, does include over-representation of whatever physics (for example) that are used in the most ESMs/GCMs. However, because PCA is focused on maximizing total variance, this over-representation does get mitigated to an extent.
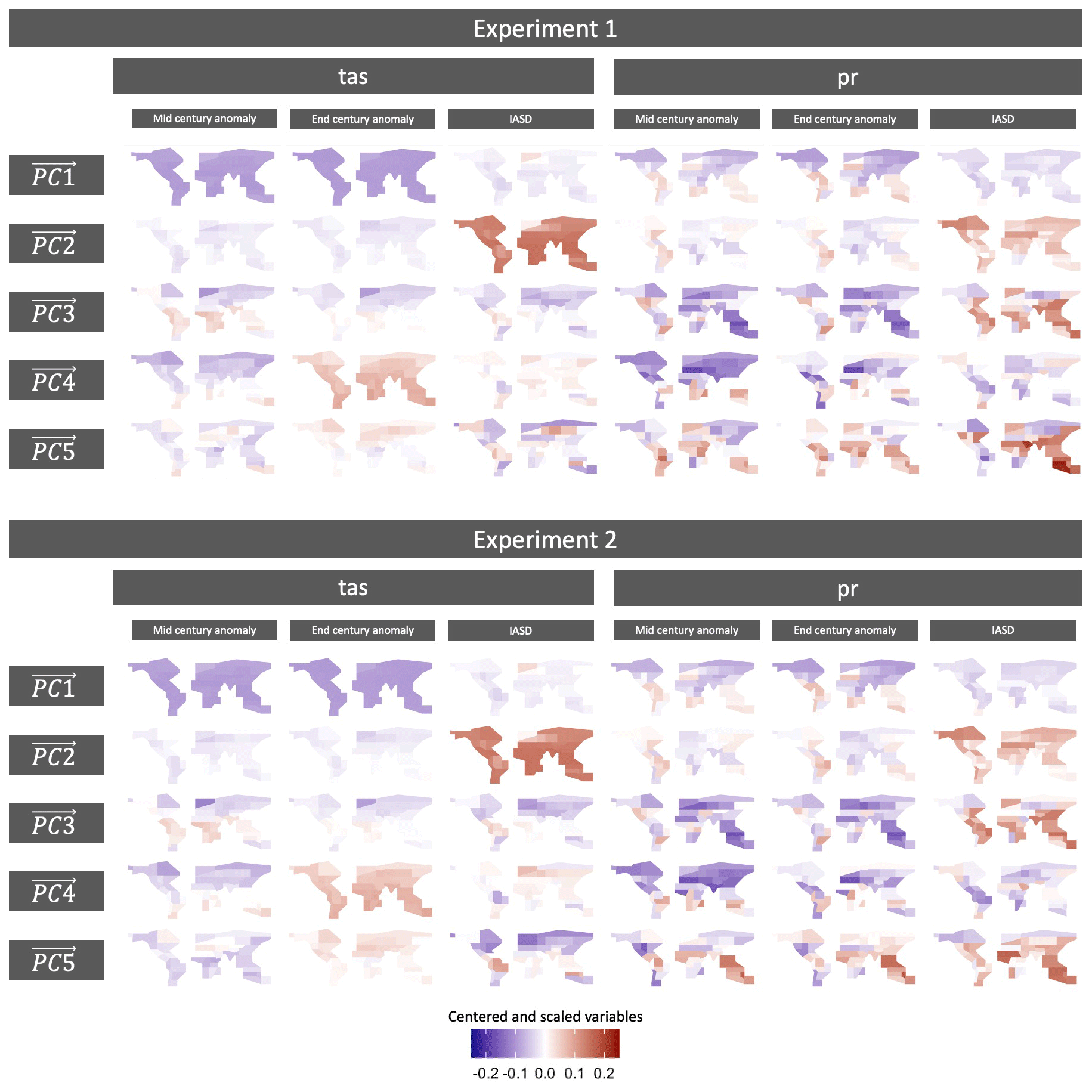
Figure 2Maps of the first five eigenvectors of our full data. Each row is a single eigenvector, with maps presented for each of the indices. Note that the color bar scales are all standardized. A larger, landscape-oriented version of this figure is included in Appendix A (Fig. A1) for easier inspection.

Figure 32-D slices of the projection coefficients for each ESM-/GCM-scenario combination into the space spanned by the first five eigenvectors.
By treating the span of these five eigenvectors as the representative space of full data, we can project all data into this space and visualize their behavior by two-dimensional plots of all five principal component (PC) combinations. Figure 3 shows these 2-D slices of the projection coefficients for each ESM/GCM and scenario into this space for each experiment. These points in space are the cij values in the principal component decomposition ai=ΣjcijPCj, where ai contains the indices in all regions for a single climate model-scenario. Because eigenvectors are orthogonal in PCA, together these panels are a complete visual representation of our ESM/GCM index data characterized in each ai, truncated to the first five projection dimensions (since they account for more than 70 % of total variance in the full data in each experiment). If an impact modeler wished, they could run every model-scenario combination here for all available ensemble members. In practice, however, this may not be computationally tractable to either run or analyze. This view also motivates our approach for selecting our subset of climate models that preserve the uncertainty characteristics defined by this space. Because we want to represent the same characteristics of variance with fewer ESMs/GCMs, our selection of a subset of ESMs/GCMs is seeking to essentially sample this cloud at its extremes, middle, and throughout as subset size allows.
2.2 Selection criteria of subset of CMIP6 models
Once the full set of data has been projected into the new basis identified to maximize total variance by PCA (as in Fig. 3), selecting a representative subset of climate models across that space is relatively straightforward, and so is adding additional selection criteria, like constraining the distribution of ECS values. The subset of climate models that minimizes distance to all other climate models across this five-dimensional space is the subset selected. In more detail, first, subsets of candidate models are formed (in this work, five models per subset, but the approach can be applied to any target subset size). While it would be possible to consider any combination of five models from the full set of 22, in this work we add a pre-filtering step. From all 22 choose 5 potential subsets, we only consider as candidate subsets the 150 subsets that roughly preserve the IPCC distribution of equilibrium climate sensitivity values and for which we could identify ECS values in the literature (Core Writing Team et al., 2023; Lovato et al., 2022; Meehl et al., 2020; Zelinka et al., 2020). Then for each subset, we step through each non-candidate model and calculate the minimum Euclidean distance to any of the subset's climate model's coefficients. The summary metric for each subset of candidates is then the average over all non-candidate model minimum distances, and the subset of candidate models with the smallest summary metric is the selected subset. Unlike many metrics (e.g., Nash and Sutcliffe, 1970; Tebaldi et al., 2020), there is unfortunately not a clear threshold for “good enough” performance based on this metric and so in the so in the next section, we provide a qualitative evaluation framework that assesses whether the selected subset is successful at preserving the major characteristics of the full ensemble's uncertainty characteristics.
2.3 Method for subset evaluation
The Hawkins and Sutton breakdown of total variance into relative sources of uncertainty inspired our choices of regional indices, both anomalies and interannual standard deviations. However, our subset selection is made in the space of the climate models' absolute positions, without formally considering the relative breakdowns into fraction of total variance explained by model uncertainty, scenario uncertainty, and internal variability. Therefore, the partitioning of relative uncertainty calculated in the style of Hawkins and Sutton (Hawkins and Sutton, 2009, 2011) is a useful independent framework to evaluate the extent to which our climate model subset preserves the characteristics of the full ensemble. We do not expect perfect agreement in the Hawkins and Sutton (HS) fractions between our climate model subset and the full data because we do change the distribution of ECS values in the subset we select. However, even qualitative discrepancies in the HS fractions between the full ensemble and the chosen subset can be useful to understand whether decisions such as constraining the distribution of ECS values are moving the relative contribution of each source of uncertainty in an explainable way.
The calculations of HS fractions are as follows. Consider a set of trajectories for a given climate variable produced by various model ESMs and scenarios. For example, this could be the annual average temperature or precipitation in a given world region. At each time step, t, there will be variation in the estimates from each observation in the set. The goal for a given set is to attribute a proportion of the variation or uncertainty at each time step to one of the three sources: interannual variation, model uncertainty, and scenario uncertainty. In our application, we want to do this for a “full” model set and compare the distribution of assigned variance to the same analysis on a selected subset of models.
The crux of this method for separating uncertainty is to write the raw predictions for each observation as , where is the raw prediction for model m scenario s at time t, is a smoothed fit of the variable anomaly with reference period 1995–2014, im,s is the average variable value over the reference period, and is the residual, representing interannual variation (IAV). Note that while the internal variability is itself a constant value for each climate model scenario, the fraction of total variance that internal variability explains can change over time as the model and scenario components change. Similarly, while we do not want to select subsets of scenarios, understanding the relative contribution of scenario uncertainty is critical to appreciate the variability across the different models.
We can then essentially calculate the interannual variation component as the variance of all ε, the model uncertainty component at each time step as the variation in x over the different models, and the scenario uncertainty at each time step as the variation in x over the different scenarios. The variance calculations can have a weighting component, although in this work we treat all models included in each experiment-specific full ensemble as uniformly weighted. The interannual variability component is computed as . The model uncertainty component is for the number of scenarios used Ns (four in this study). The scenario uncertainty component is .
Note that each of these components may, for example, be weighted based on each climate model's closeness to some observational set, but in this work we weight them uniformly, as we are not concerned with model validation. Furthermore, we follow the assertion by Hawkins and Sutton (2009), who assert that final fractions of total variability are not strongly affected when using different weights.
The selected subset of ESMs/GCMs and their respective ECS values are provided in Table 3 for each experiment. Figure 4 presents an identical plot to Fig. 3 but with the selected ESMs/GCMs highlighted by black box-shaped outlines to emphasize the extent to which the subset covers the full ensemble. We also perform a validation exercise based on the work of Hawkins and Sutton (2009, 2011), using the whole time series data rather than the six metrics that guided our subset selection to provide an additional perspective on the ability of the method to preserve the characteristics of variability in the whole ensemble.
Table 3Selected model subset and ECS values for each experiment. Models selected in both experiments are shown in bold.
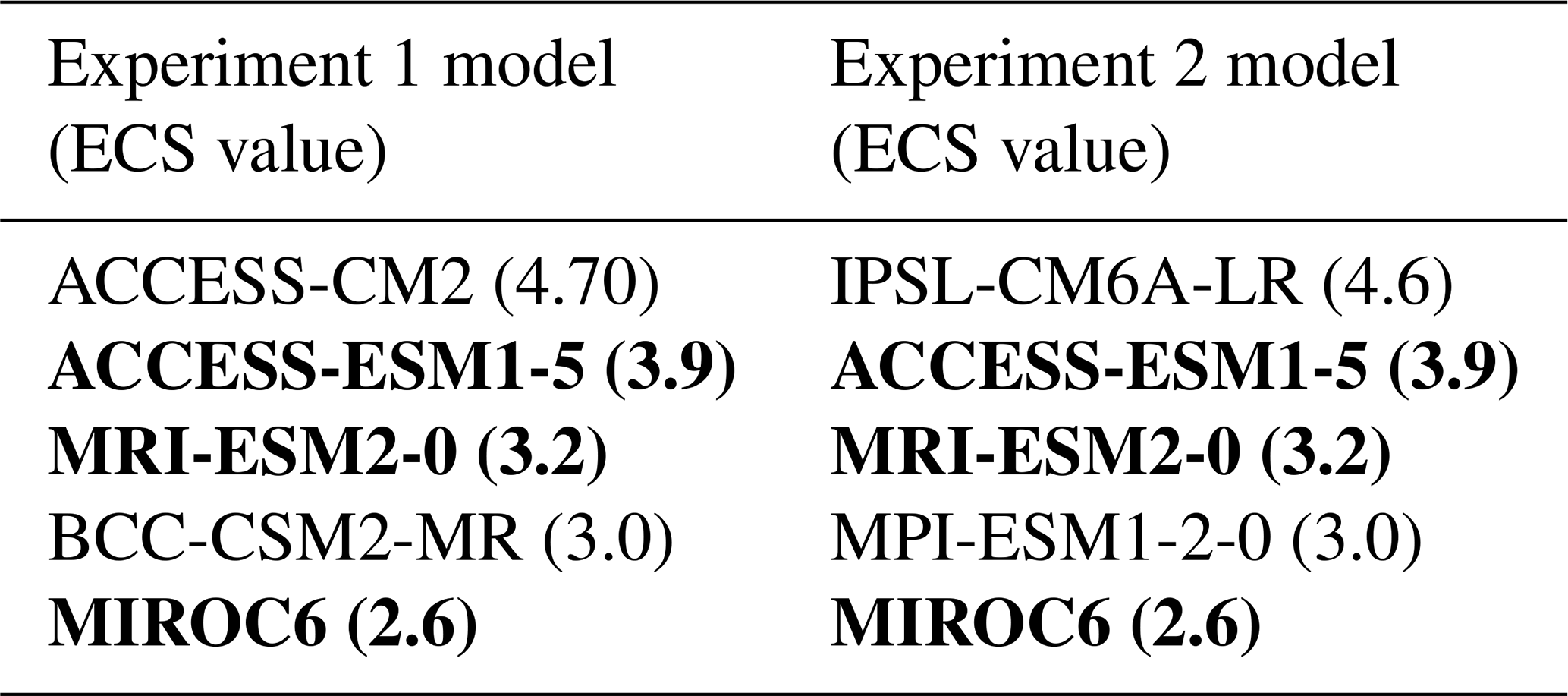

Figure 4Same as Fig. 3 but with the selected ESMs/GCMs highlighted by black box-shaped outlines in Experiment 1 (a) and Experiment 2 (b).
Subset evaluation
As noted in Sect. 2.3, the partitioning of total variance into the relative contribution of different sources calculated by Hawkins and Sutton (2009, 2011) is a useful independent framework to evaluate the extent to which our climate model subset preserves the characteristics of the full ensemble. As we did not calculate the specific time series of Hawkins and Sutton (HS) fractions for internal variability (there, as here, quantified as interannual variability after detrending the annual mean time series), scenario uncertainty, and model uncertainty to form any part of our selection procedure, we can use these HS fractions as an independent evaluation criteria. We calculate the time series of HS fractions for temperature and precipitation separately in each region for the full set of data and over just our selected subset of data, i.e., for each experiment, over the selection of CMIP6 models making up the full data set in that experiment, and only using the subset of five ESMs/GCMs that our method identified. Details of these calculations are provided in Sect. 2.3. To manage the inspection of three time series for each of the 86 region–variable combinations, we use the root mean square error (RMSE) to compare the full data time series and the subset data time series from 2040 onward (as that is the focus of our indices) for each uncertainty partition and for each variable in each region.
Because of the large number of regions we wish to examine for two variables over time in each of two separate experiments, we seek some criteria to narrow this down. To identify specific region–variable combinations that are due for closer inspection, we set a threshold on the RMSE values for each uncertainty partition for each region–variable combination. As we note in Sect. 2.3, a discrepancy between the HS fractions for the subset and the full data is not a sign of poor selection. Rather, it merely means it is a region to inspect more closely and then consider whether the discrepancies follow from our constraint of ECS values as part of our selection procedure. If any of the three uncertainty partitions have RMSE>0.1, we flag that region–variable combination for closer inspection. While thresholds like this are often arbitrary to set, each uncertainty partition for the subset data explaining the fraction of total variance within 10 % of the full data's partition seems a good place to start. We show in Appendix A the results of a less stringent choice, namely if we relax this to 20 %, then far fewer regions and variables get flagged for inspection in each experiment. Lowering this inspection threshold will of course flag more region–variable combinations, but as we point out below, a portion of the combinations flagged with a threshold of 0.1 still actually perform reasonably when plotted over time. Figure 5 provides a color-coded map of regions where temperature, precipitation, both, or neither have RMSE≦0.1 for all three uncertainty partitions to give a sense of the spatial extent of performance.

Figure 5A color-coded map of regions where temperature, precipitation, both, or neither have RMSE≦0.1 for all three uncertainty partitions.

Figure 6Regions flagged for a closer inspection of their HS fraction time series for temperature. The color-blocked time series are the HS fractions from the full set of data, and the overlaid white curves are the respective boundaries for the uncertainty partitions of the subset data.
The time series of HS fractions for the remaining region–variable combinations for which RMSE>0.1 are plotted in Fig. 6 (temperature) and Fig. 7 (precipitation). For temperature in both experiments, we see that the interannual variability is often performing well, with increasingly better performance over time. The partitioning of model and scenario uncertainty is where the subset's behavior begins to depart from the full data, although this too tends to have smaller discrepancies as time goes on. This is not surprising: in the full set of data, a good portion of the model uncertainty is driven by different ECS values. As provided in Table 2, the values across ESMs/GCMs that participated in Tier 1 ScenarioMIP experiments do not match the IPCC's very likely distribution. By contrast, we are only selecting subsets of ESMs/GCMs that match this distribution; overall, this results in a cooler collection of climate models compared to the full data. This accounts for much of the discrepancy with respect to the balance between the scenario and model uncertainty contributions being different between our full and our subset data. Enforcing a different distribution of ECS values in the selected subset relative to the full data will also explain many of the discrepancies for precipitation, given the known strong correlation between temperature and precipitation changes. For precipitation, overall we see the total uncertainty in the subset having a greater fraction explained by interannual variability and a smaller fraction explained by model uncertainty across time. For both temperature and precipitation, the direction of these discrepancies is not surprising, given our choice to reshape the distribution of ECS to an overall cooler collection than the full data. What we want to see in all panels of Figs. 6 and 7 is a qualitative agreement with the relevance of the three sources of uncertainty in the full ensemble. We note that even in the regions we have flagged for closer inspection in Figs. 6 and 7, model uncertainty is evolving in the subset in much the same way as it evolves in the full set, albeit with a shift. According to this criterion, most of the regions flagged by the application of the 0.1 threshold remain consistent with the full ensemble representation of the three uncertainty sources for both variables and across both experiments. A small portion of the regions inspected in Fig. 6 and 7 do ultimately simply differ more dramatically in the representations in the full set versus subset, such as TIB in Experiment 1 in Fig. 6. This is often unavoidable in a few regions when seeking to represent the entire globe with a subset of ESMs/GCMs; again, we note that an even more substantial quality discrepancy such as this is not a sign of the failure of the method due to the constraints on ECS distributions.

This work outlines and documents the success of a method for selecting a subset of climate models from CMIP6 that overall preserve the uncertainty characteristics of the full CMIP ensemble, particularly for use with multisectoral dynamics models that require global coverage and consistency across regions. The methodology is not focused on advocating for the idea that a particular set of models is superior; instead, it focuses on managing the uncertainty. Our methodology relies on pre-identifying regional indices of behavior for ESM/GCM output variables, as well as other filters (such as preserving the IPCC distribution of ECS values) judged to be critical for the robustness of impact and multisectoral modeling. With these assumptions, far fewer climate inputs are needed to span the range of uncertainties seen in CMIP6, resulting in fewer impact model runs needing to be performed and analyzed. There are likely many situations in which a modeler could adapt the details of the method (outlined in Table 1) and code for their purposes, re-run the code to identify a subset of climate models, and validate that new subset in much less time and with a great deal fewer computing resources needed than simply running impact models with all scenarios and ensemble members available for the 22 ESMs/GCMs documented in Table 2. For multisectoral modelers integrating multiple different impacts, or running large-ensemble experiments, the time saved only grows, even when accounting for the method adjustment and the re-validation of results. For researchers focused on emulators, there may be opportunities to identify fewer climate models that would benefit from generating more initial-condition ensemble members, focusing efforts. Finally, Earth system modelers can gain new insights into their individual climate models by adding the approach to uncertainty characterization outlined in this work to their existing analyses.
The methodology outlined in this paper is an adaptable approach to retain the major uncertainty characteristics of a large collection of global-coverage climate model data and to make changes (as we did to the full-ensemble ECS distribution). While there are resulting regions for both temperature and precipitation where the uncertainty partitions of the subset of ESMs/GCMs differ from the full set of CMIP6 models, these differences are primarily expected, based on the different ECS distribution represented by our subset ESMs/GCMs compared to the full data. For those interested in using our chosen subset, we hope that by providing detailed information about where the subset differs in Figs. 5–7, impact modelers may be able to infer how the results would change if the full set of data were used – and with a far lower computational burden than running all available data. Furthermore, because the method is adaptable, an impact modeler particularly interested in a specific region could weight the outcomes in that region more heavily for the selection of the subset.
As noted, this work is primarily coming from the perspective of a multisectoral dynamics modeler requiring the global coverage of a range of climate model output variables at different timescales, and naturally, other perspectives will come with their own caveats. Impacts can be estimated and worked with at a range of spatial scales; impact modelers concerned with finer-scale or local impacts, or modelers focused on a single region rather than global coverage, may very well be served by prioritizing other factors like skill in their climate model subselection. Bias correction and downscaling are also tools heavily used to get to these finer spatial scales, and these processes introduce their own sources of uncertainty, particularly for very local phenomenon and over complex terrain (Kendon et al., 2010; Mearns et al., 2013; Barsugli et al., 2013; Lafferty and Sriver, 2023). Generally, the method outlined in this work is more appropriate for working with raw CMIP6 data in the native resolutions or an ensemble of bias-adjusted and downscaled climate data that has been processed using a consistent bias-adjustment and downscaling method. On a final note, regarding adaptations of this method, we focused on temperature and precipitation because many variables used in impact modeling are correlated to or derived from these variables. This is especially true in agriculture (e.g., Sinha et al., 2023a, b; Peterson and Abatzoglou, 2014; Allstadt et al., 2015; Gerst et al., 2020), although it holds true in other sectors as well. One area for the potential expansion of this method that would have a more direct relevance for those derived variables would be to incorporate a time dimension more explicitly.



All code and data are available via a GitHub metarepository (https://github.com/JGCRI/SnyderEtAl2023_uncertainty_informed_curation_metarepo, last access: 9 July 2024) and have been minted with a permanent DOI (https://doi.org/10.57931/2223040, Snyder and Prime, 2023).
CT conceived of the project. AS led design of the methodology and performed the analysis. NP performed the analysis. KD provided data. All authors contributed to methodology, analysis, and the writing of the paper.
The contact author has declared that none of the authors has any competing interests.
The views and opinions expressed in this paper are those of the authors alone.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
This research has been supported by the U.S. Department of Energy (DOE), Office of Science, as part of research in MultiSector Dynamics, an Earth and Environmental System Modeling Program.
This research has been supported by the U.S. Department of Energy (GCIMS), and the Pacific Northwest National Laboratory is operated for the DOE by the Battelle Memorial Institute under contract DE-AC05-76RL01830.
This paper was edited by Gabriele Messori and reviewed by three anonymous referees.
Abramowitz, G., Herger, N., Gutmann, E., Hammerling, D., Knutti, R., Leduc, M., Lorenz, R., Pincus, R., and Schmidt, G. A.: ESD Reviews: Model dependence in multi-model climate ensembles: weighting, sub-selection and out-of-sample testing, Earth Syst. Dynam., 10, 91–105, https://doi.org/10.5194/esd-10-91-2019, 2019.
Allstadt, A. J., Vavrus, S. J., Heglund, P. J., Pidgeon, A. M., Thogmartin, W. E., and Radeloff, V. C.: Spring plant phenology and false springs in the conterminous US during the 21st century, Environ. Res. Lett., 10, 104008, https://doi.org/10.1088/1748-9326/10/10/104008, 2015.
Barsugli, J. J., Guentchev, G., Horton, R. M., Wood, A., Mearns, L. O., Liang, X.-Z., Winkler, J. A., Dixon, K., Hayhoe, K., Rood, R. B., Goddard, L., Ray, A., Buja, L., and Ammann, C.: The practitioner's dilemma: How to assess the credibility of downscaled climate projections, Eos T. Am. Geophys. Un., 94, 424–425, https://doi.org/10.1002/2013eo460005, 2013.
Beusch, L., Gudmundsson, L., and Seneviratne, S. I.: Emulating Earth system model temperatures with MESMER: from global mean temperature trajectories to grid-point-level realizations on land, Earth Syst. Dynam., 11, 139–159, https://doi.org/10.5194/esd-11-139-2020, 2020.
Brands, S.: A circulation-based performance atlas of the CMIP5 and 6 models for regional climate studies in the Northern Hemisphere mid-to-high latitudes, Geosci. Model Dev., 15, 1375–1411, https://doi.org/10.5194/gmd-15-1375-2022, 2022.
Core Writing Team, Lee, H., and Romero, J. (Eds.): Summary for Policymakers, in: Climate Change 2023: Synthesis Report. Contribution of Working Groups I, II and III to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change, IPCC, https://doi.org/10.59327/IPCC/AR6-9789291691647.001, 2023.
Dolan, F., Lamontagne, J., Link, R., Hejazi, M., Reed, P., and Edmonds, J.: Evaluating the economic impact of water scarcity in a changing world, Nat. Commun., 12, 1915, https://doi.org/10.1038/s41467-021-22194-0, 2021.
Dolan, F., Lamontagne, J., Calvin, K., Snyder, A., Narayan, K. B., Di Vittorio, A. V., and Vernon, C. R.: Modeling the economic and environmental impacts of land scarcity under deep uncertainty, Earths Future, 10, e2021EF002466, https://doi.org/10.1029/2021EF002466, 2022.
Eyring, V., Bony, S., Meehl, G. A., Senior, C. A., Stevens, B., Stouffer, R. J., and Taylor, K. E.: Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization, Geosci. Model Dev., 9, 1937–1958, https://doi.org/10.5194/gmd-9-1937-2016, 2016.
Frieler, K., Lange, S., Piontek, F., Reyer, C. P. O., Schewe, J., Warszawski, L., Zhao, F., Chini, L., Denvil, S., Emanuel, K., Geiger, T., Halladay, K., Hurtt, G., Mengel, M., Murakami, D., Ostberg, S., Popp, A., Riva, R., Stevanovic, M., Suzuki, T., Volkholz, J., Burke, E., Ciais, P., Ebi, K., Eddy, T. D., Elliott, J., Galbraith, E., Gosling, S. N., Hattermann, F., Hickler, T., Hinkel, J., Hof, C., Huber, V., Jägermeyr, J., Krysanova, V., Marcé, R., Müller Schmied, H., Mouratiadou, I., Pierson, D., Tittensor, D. P., Vautard, R., van Vliet, M., Biber, M. F., Betts, R. A., Bodirsky, B. L., Deryng, D., Frolking, S., Jones, C. D., Lotze, H. K., Lotze-Campen, H., Sahajpal, R., Thonicke, K., Tian, H., and Yamagata, Y.: Assessing the impacts of 1.5 °C global warming – simulation protocol of the Inter-Sectoral Impact Model Intercomparison Project (ISIMIP2b), Geosci. Model Dev., 10, 4321–4345, https://doi.org/10.5194/gmd-10-4321-2017, 2017.
Gerst, K. L., Crimmins, T. M., Posthumus, E. E., Rosemartin, A. H., and Schwartz, M. D.: How Well Do the Spring Indices Predict Phenological Activity across Plant Species?, Int. J. Biometeorol., 64, 889–901, https://doi.org/10.1007/s00484-020-01879-z, 2020.
Graham, N. T., Hejazi, M. I., Chen, M., Davies, E. G. R., Edmonds, J. A., Kim, S. H., Turner, S. W. D., Li, X., Vernon, C. R., Calvin, K., Miralles-Wilhelm, F., Clarke, L., Kyle, P., Link, R., Patel, P., Snyder, A., and Wise, M.: Humans drive future water scarcity changes across all Shared Socioeconomic Pathways, Environ. Res. Lett., 15, 014007, https://doi.org/10.1088/1748-9326/ab639b, 2020.
Guivarch, C., Le Gallic, T., Bauer, N., Fragkos, P., Huppmann, D., Jaxa-Rozen, M., Keppo, I., Kriegler, E., Krisztin, T., Marangoni, G., Pye, S., Riahi, K., Schaeffer, R., Tavoni, M., Trutnevyte, E., van Vuuren, D., and Wagner, F.: Using large ensembles of climate change mitigation scenarios for robust insights, Nat. Clim. Change, 12, 428–435, https://doi.org/10.1038/s41558-022-01349-x, 2022.
Hausfather, Z., Marvel, K., Schmidt, G. A., Nielsen-Gammon, J. W., and Zelinka, M.: Climate Simulations: Recognize the `hot Model' Problem, Nature Publishing Group UK, https://doi.org/10.1038/d41586-022-01192-2, 2022.
Hawkins, E. and Sutton, R.: The potential to narrow uncertainty in regional climate predictions, B. Am. Meteorol. Soc., 90, 1095–1108, https://doi.org/10.1175/2009BAMS2607.1, 2009.
Hawkins, E. and Sutton, R.: The potential to narrow uncertainty in projections of regional precipitation change, Clim. Dynam., 37, 407–418, https://doi.org/10.1007/s00382-010-0810-6, 2011.
Iturbide, M., Fernández, J., Gutiérrez, J. M., Pirani, A., Huard, D., Al Khourdajie, A., Baño-Medina, J., Bedia, J., Casanueva, A., Cimadevilla, E., Cofiño, A. S., De Felice, M., Diez-Sierra, J., García-Díaz, M., Goldie, J., Herrera, D. A., Herrera, S., Manzanas, R., Milovac, J., Radhakrishnan, A., San-Martín, D., Spinuso, A., Thyng, K. M., Trenham, C., and Yelekçi, Ö.: Implementation of FAIR principles in the IPCC: the WGI AR6 Atlas repository, Scientific Data, 9, 629, https://doi.org/10.1038/s41597-022-01739-y, 2022.
Kendon, E. J., Jones, R. G., Kjellström, E., and Murphy, J. M.: Using and Designing GCM–RCM Ensemble Regional Climate Projections, J. Climate, 23, 6485–6503, https://doi.org/10.1175/2010JCLI3502.1, 2010.
Lafferty, D. C. and Sriver, R. L.: Downscaling and Bias-Correction Contribute Considerable Uncertainty to Local Climate Projections in CMIP6, Npj Climate and Atmospheric Science, 6, 1–13, https://doi.org/10.1038/s41612-023-00486-0, 2023.
Lange, S.: Trend-preserving bias adjustment and statistical downscaling with ISIMIP3BASD (v1.0), Geosci. Model Dev., 12, 3055–3070, https://doi.org/10.5194/gmd-12-3055-2019, 2019.
Lehner, F., Deser, C., Maher, N., Marotzke, J., Fischer, E. M., Brunner, L., Knutti, R., and Hawkins, E.: Partitioning climate projection uncertainty with multiple large ensembles and CMIP5/6, Earth Syst. Dynam., 11, 491–508, https://doi.org/10.5194/esd-11-491-2020, 2020.
Lovato, T., Peano, D., Butenschön, M., Materia, S., Iovino, D., Scoccimarro, E., Fogli, P. G., Cherchi, A., Bellucci, A., Gualdi, S., Masina, S., and Navarra, A.: CMIP6 simulations with the CMCC Earth system model (CMCC-ESM2), J. Adv. Model. Earth Sy., 14, e2021MS002814, https://doi.org/10.1029/2021MS002814, 2022.
Mearns, L. O., Sain, S., Leung, L. R., Bukovsky, M. S., McGinnis, S., Biner, S., Caya, D., Arritt, R. W., Gutowski, W., Takle, E., Snyder, M., Jones, R. G., Nunes, A. M. B., Tucker, S., Herzmann, D., McDaniel, L., and Sloan, L.: Climate change projections of the North American Regional Climate Change Assessment Program (NARCCAP), Climatic Change, 120, 965–975, https://doi.org/10.1007/s10584-013-0831-3, 2013.
Meehl, G. A., Senior, C. A., Eyring, V., Flato, G., Lamarque, J.-F., Stouffer, R. J., Taylor, K. E., and Schlund, M.: Context for interpreting equilibrium climate sensitivity and transient climate response from the CMIP6 Earth system models, Science Advances, 6, eaba1981, https://doi.org/10.1126/sciadv.aba1981, 2020.
Merrifield, A. L., Brunner, L., Lorenz, R., Humphrey, V., and Knutti, R.: Climate model Selection by Independence, Performance, and Spread (ClimSIPS v1.0.1) for regional applications, Geosci. Model Dev., 16, 4715–4747, https://doi.org/10.5194/gmd-16-4715-2023, 2023.
Müller, C., Franke, J., Jägermeyr, J., Ruane, A. C., Elliott, J., Moyer, E., Heinke, J., Falloon, P. D., Folberth, C., Francois, L., Hank, T., Izaurralde, R. C., Jacquemin, I., Liu, W., Olin, S., Pugh, T. A. M., Williams, K., and Zabel, F.: Exploring uncertainties in global crop yield projections in a large ensemble of crop models and CMIP5 and CMIP6 climate scenarios, Environ. Res. Lett., 16, 034040, https://doi.org/ 10.1088/1748-9326/abd8fc, 2021.
Nash, J. E. and Sutcliffe, J. V.: River flow forecasting through conceptual models part I – A discussion of principles, J. Hydrol., 10, 282–290, https://doi.org/10.1016/0022-1694(70)90255-6, 1970.
Nath, S., Lejeune, Q., Beusch, L., Seneviratne, S. I., and Schleussner, C.-F.: MESMER-M: an Earth system model emulator for spatially resolved monthly temperature, Earth Syst. Dynam., 13, 851–877, https://doi.org/10.5194/esd-13-851-2022, 2022.
O'Neill, B. C., Tebaldi, C., van Vuuren, D. P., Eyring, V., Friedlingstein, P., Hurtt, G., Knutti, R., Kriegler, E., Lamarque, J.-F., Lowe, J., Meehl, G. A., Moss, R., Riahi, K., and Sanderson, B. M.: The Scenario Model Intercomparison Project (ScenarioMIP) for CMIP6, Geosci. Model Dev., 9, 3461–3482, https://doi.org/10.5194/gmd-9-3461-2016, 2016.
Parding, K. M., Dobler, A., McSweeney, C. F., Landgren, O. A., Benestad, R., Erlandsen, H. B., Mezghani, A., Gregow, H., Räty, O., Viktor, E., El Zohbi, J., Christensen, O. B., and Loukos, H.: GCMeval – An interactive tool for evaluation and selection of climate model ensembles, Clim. Serv., 18, 100167, https://doi.org/10.1016/j.cliser.2020.100167, 2020.
Peterson, A. G. and Abatzoglou, J. T.: Observed changes in false springs over the contiguous United States, Geophys. Res. Lett., 41, 2156–2162, https://doi.org/10.1002/2014gl059266, 2014.
Prudhomme, C., Giuntoli, I., Robinson, E. L., Clark, D. B., Arnell, N. W., Dankers, R., Fekete, B. M., Franssen, W., Gerten, D., Gosling, S. N., Hagemann, S., Hannah, D. M., Kim, H., Masaki, Y., Satoh, Y., Stacke, T., Wada, Y., and Wisser, D.: Hydrological droughts in the 21st century, hotspots and uncertainties from a global multimodel ensemble experiment, P. Natl. Acad. Sci. USA, 111, 3262–3267, https://doi.org/10.1073/pnas.1222473110, 2014.
Quilcaille, Y., Gudmundsson, L., Beusch, L., Hauser, M., and Seneviratne, S. I.: Showcasing MESMER-X: Spatially Resolved Emulation of Annual Maximum Temperatures of Earth System Models, Geophys. Res. Lett., 49, e2022GL099012, https://doi.org/10.1029/2022GL099012, 2022.
Rosenzweig, C., Jones, J. W., Hatfield, J. L., Ruane, A. C., Boote, K. J., Thorburn, P., Antle, J. M., Nelson, G. C., Porter, C., Janssen, S., Asseng, S., Basso, B. B., Ewert, F. A., Wallach, D., Baigorria, G. A., and Winter, J. M.: The agricultural model intercomparison and improvement project (AgMIP): protocols and pilot studies, Agr. Forest Meteorol., 170, 166–182, https://doi.org/10.1016/j.agrformet.2012.09.011, 2013.
Rosenzweig, C., Elliott, J., Deryng, D., Ruane, A. C., Müller, C., Arneth, A., Boote, K. J., Folberth, C., Glotter, M., Khabarov, N., Neumann, K., Piontek, F., Pugh, T. A. M., Schmid, E., Stehfest, E., Yang, H., and Jones, J. W.: Assessing agricultural risks of climate change in the 21st century in a global gridded crop model intercomparison, P. Natl. Acad. Sci. USA, 111, 3268–3273, https://doi.org/10.1073/pnas.1222463110, 2014.
Sinha, E., Bond-Lamberty, B., Calvin, K. V., Drewniak, B. A., Bisht, G., Bernacchi, C., Blakely, B. J., and Moore, C. E.: The Impact of Crop Rotation and Spatially Varying Crop Parameters in the E3SM Land Model (ELMv2), J. Geophys. Res.-Biogeo., 128, e2022JG007187, https://doi.org/10.1029/2022jg007187, 2023a.
Sinha, E., Calvin, K. V., and Bond-Lamberty, B.: Modeling Perennial Bioenergy Crops in the E3SM Land Model (ELMv2), J. Adv. Model. Earth Sy., 15, e2022MS003171, https://doi.org/10.1029/2022MS003171, 2023b.
Snyder, A. and Prime, N.: code and data for Uncertainty-informed selection of CMIP6 Earth System Model subsets for use in multisectoral and impact models (Version v1), MSD-LIVE Data Repository [data set], https://doi.org/10.57931/2223040, 2023.
Tebaldi, C., Armbruster, A., Engler, H. P., and Link, R.: Emulating climate extreme indices, Environ. Res. Lett., 15, 074006, https://doi.org/10.1088/1748-9326/ab8332, 2020.
Tebaldi, C., Dorheim, K., Wehner, M., and Leung, R.: Extreme metrics from large ensembles: investigating the effects of ensemble size on their estimates, Earth Syst. Dynam., 12, 1427–1501, https://doi.org/10.5194/esd-12-1427-2021, 2021.
Tebaldi, C., Snyder, A., and Dorheim, K.: STITCHES: creating new scenarios of climate model output by stitching together pieces of existing simulations, Earth Syst. Dynam., 13, 1557–1609, https://doi.org/10.5194/esd-13-1557-2022, 2022.
Warszawski, L., Frieler, K., Huber, V., Piontek, F., Serdeczny, O., and Schewe, J.: The inter-sectoral impact model intercomparison project (ISI–MIP): project framework, P. Natl. Acad. Sci. USA, 111, 3228–3232, https://doi.org/10.1073/pnas.1312330110, 2014.
Zelinka, M. D., Myers, T. A., McCoy, D. T., Po-Chedley, S., Caldwell, P. M., Ceppi, P., Klein, S. A., and Taylor, K. E.: Causes of higher climate sensitivity in CMIP6 models, Geophys. Res. Lett., 47, e2019GL085782, https://doi.org/10.1029/2019GL085782, 2020.